Match
- Ankur Parekh
- Subhajit Sengupta
- Mohammed Iqbal
On this Page
Overview
This Snap performs record linkage to identify documents from different data sources (input views) that may represent the same entity without relying on a common key. The Match Snap enables you to automatically identify matched records across datasets that do not have a common key field.
The Match Snap is part of our ML Data Preparation Snap Pack.
This Snap uses Duke, which is a library for performing record linkage and deduplication, implemented on top of Apache Lucene.
Input and Output
Expected input
- First Input: The first dataset that must be matched with the second dataset.
- Second Input: The second dataset that must be matched with the first dataset.
Expected Output
- First Output: The matched documents and, optionally, the confidence level associated with the matching.
- Second Output: Optional. Unmatched documents from the first dataset.
- Third Output: Optional. Unmatched documents from the second dataset.
Expected Upstream Snaps
- First Input: A Snap that offers documents. For example, Mapper, MySQL - Select, and JSON Parser.
- Second Input: A Snap that offers documents. For example, Mapper, MySQL - Select, and JSON Parser.
Expected Downstream Snaps
- Snaps that accept documents. For example, Mapper, JSON Formatter, and CSV Formatter.
Prerequisites
None.
Configuring Accounts
Accounts are not used with this Snap.
Configuring Views
Input | This Snap has exactly two document input views. |
|---|---|
| Output | This Snap has at most three document output views. |
| Error | This Snap has at most one document error view. |
Troubleshooting
None.
Limitations and Known Issues
None.
Modes
- Ultra Pipelines: Does not work in Ultra Pipelines.
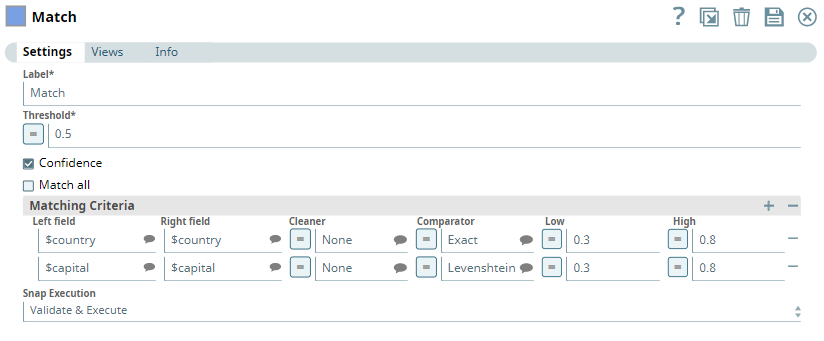
Snap Settings
| Label | Required. The name for the Snap. Modify this to be more specific, especially if there are more than one of the same Snap in the pipeline. |
|---|---|
| Threshold | Required. The minimum confidence required for documents to be considered matched. Minimum Value: 0 Maximum Value: 1 Default Value: 0.8 |
| Confidence | Select this check box to include each match's confidence levels in the output. Default Value: Deselected |
| Match all | Select this check box to match one record from the first input with multiple records in the second input. Else, the Snap matches the first record of the second input with the first record of the first input. Default Value: Deselected |
| Matching Criteria | Enables you to specify the settings that you want to use to perform the matching between the two input datasets. |
| Left Field | The field in the first dataset that you want to use for matching. This property is a JSONPath. Example: $name Default Value: [None] |
| Right Field | The field in the second dataset that you want to use for matching. This property is a JSONPath. Example: $country Default Value: [None] |
| Cleaner | Select the cleaner that you want to use on the selected fields. A cleaner makes comparison easier by removing variations from data, which are not likely to indicate genuine differences. For example, a cleaner might strip everything except digits from a ZIP code. Or, it might normalize and lowercase text. Depending on the nature of the data in the identified input fields, you can select the kind of cleaner you want to use from the options available:
|
| Comparator | A comparator compares two values and produces a similarity indicator, which is represented by a number that can range from 0 (completely different) to 1 (exactly equal). Choose the comparator that you want to use on the selected fields, from the drop-down list:
Default Value: Levenshtein |
| Low | Enter a decimal value representing the level of probability of the records to be matched if the specified fields are completely unlike. Example: 0.1 Default Value: [None] If this value is left empty, a value of 0.3 is applied automatically. |
| High | Enter a decimal value representing the level of probability of the records to be matched if the specified fields are exact match. Example: 0.8 Default Value: [None] If this value is left empty, a value of 0.95 is applied automatically. |
| Snap execution | Select one of the three modes in which the Snap executes. Available options are:
|
Temporary Files
During execution, data processing on Snaplex nodes occurs principally in-memory as streaming and is unencrypted. When larger datasets are processed that exceeds the available compute memory, the Snap writes Pipeline data to local storage as unencrypted to optimize the performance. These temporary files are deleted when the Snap/Pipeline execution completes. You can configure the temporary data's location in the Global properties table of the Snaplex's node properties, which can also help avoid Pipeline errors due to the unavailability of space. For more information, see Temporary Folder in Configuration Options.Example
Matching Countries Based on their Names and Capitals
One of the challenges associated with data integration is consolidating datasets representing the same entities but using different measurement standards of the data. For example, if you buy the same data from multiple brokers, you may see that the datasets are organized or labeled differently. In data lake scenarios, consolidating data across thousands of datasets manually is a nearly impossible task, given the large number of datasets and the various formats and labeling patterns used across databases. The Match Snap enables you to identify such matched records automatically.
In this example, you take two datasets as input and match country records in them using the Match Snap. You then adjust the similarity threshold value in the Match Snap to try to get the best results (maximize the number of matches while making sure the results are reliable).
Download this Pipeline.
To use the Match Snap, you need two datasets coming into the Snap, where you list out the dataset fields that you want to use to match the records. Once you have the matched data, you create a mechanism for identifying the lowest possible threshold for which you can get the maximum number of reliable matches. To do so, you need to perform the following tasks:
- Send data from two datasets into the Match Snap and configure the Match Snap to match countries based on their names and capitals.
- Sort the matched country records based on their confidence levels and write them out to a file. This file helps you determine whether to increase or decrease the threshold to adjust the number of matches.
- Write the matched country records without their confidence information to a file. This is the output of the Pipeline.
- Write the unmatched records from the source datasets into separate files, so you can see how many remain unmatched. If you do not need the unmatched records, remove the second and third output views of the Match Snap.
You create the Pipeline as shown below:
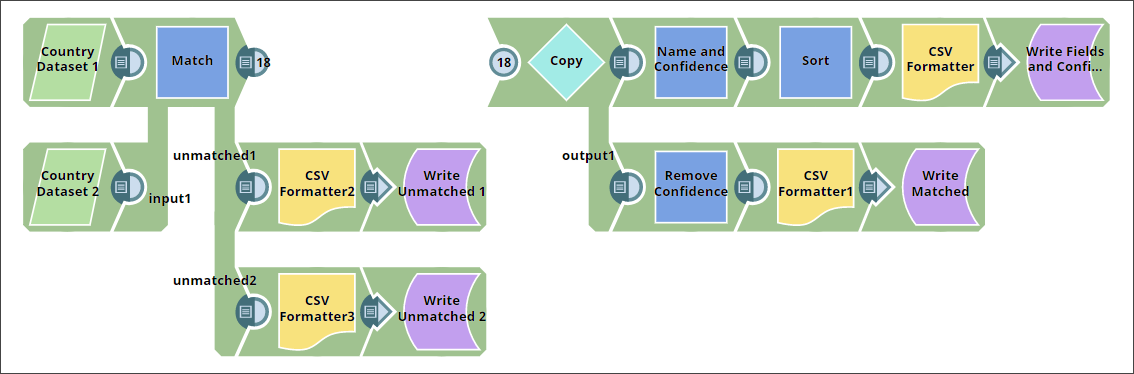
Receiving input datasets
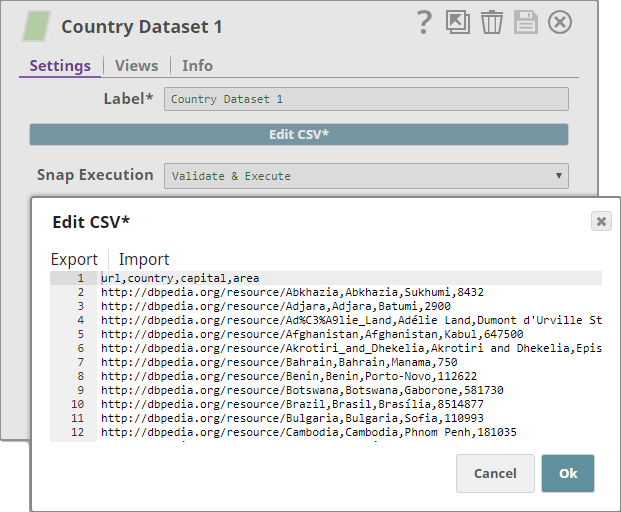
You use a CSV Generator Snap to create the first input dataset. This dataset contains URLs to specific pages that contain a country's details, followed by the name of the country, its capital, and its area.
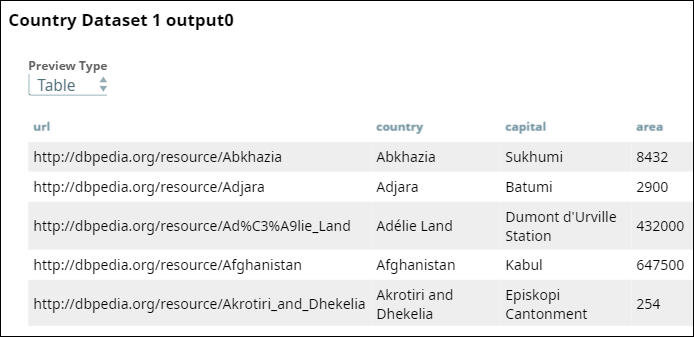
Once you validate the Pipeline, you can view a preview of the output of this Snap:
You use another CSV Generator Snap to create the second input dataset. Each row of this dataset contains a country ID, followed by a country's name, its capital, and area:
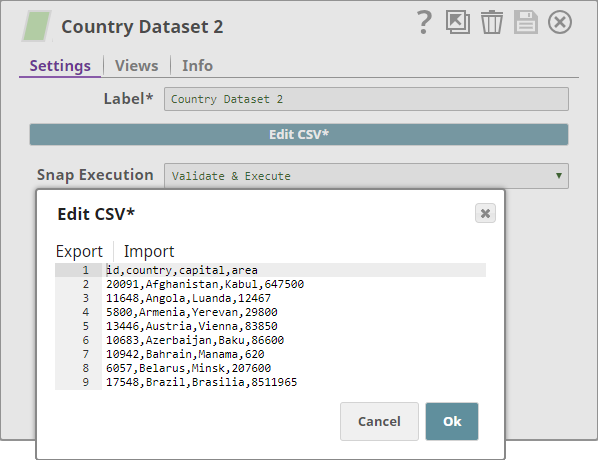
Once you validate the Pipeline, you can view the output:
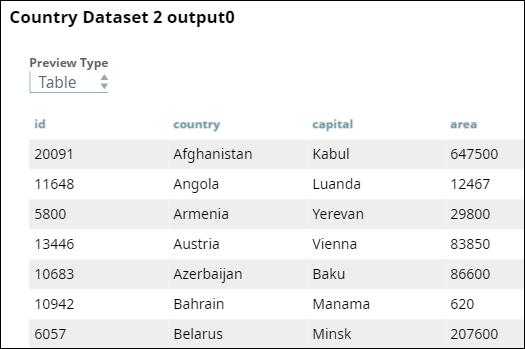
Matching records in dataset fields
You now connect a Match Snap to the two CSV Generator Snaps and configure them to match countries based on their names and capitals, represented in text:
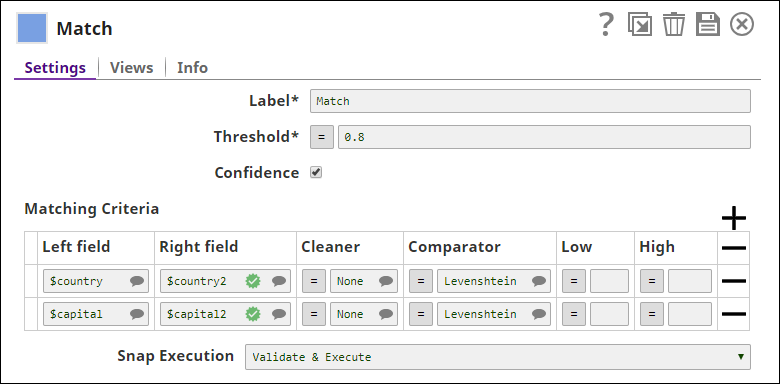
The Match Snap can offer up to three outputs:
- First Output: The list of matched records.
- Second Output: The list of unmatched records from the first input view.
- Third Output: The list of unmatched records from the second input view.
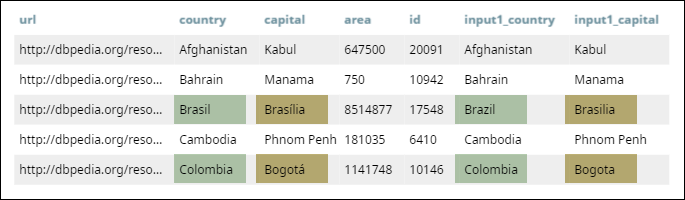
Once you validate the Pipeline, you can view the matched entries in the first output view:
Note that this Snap supports strings that contain diacritics (é, è, â, ñ, and so on), and is able to match the two versions of 'Brasilia' and 'Bogota' (highlighted in the screenshot below.)
The second output view shows the list of unmatched records from the first input view:
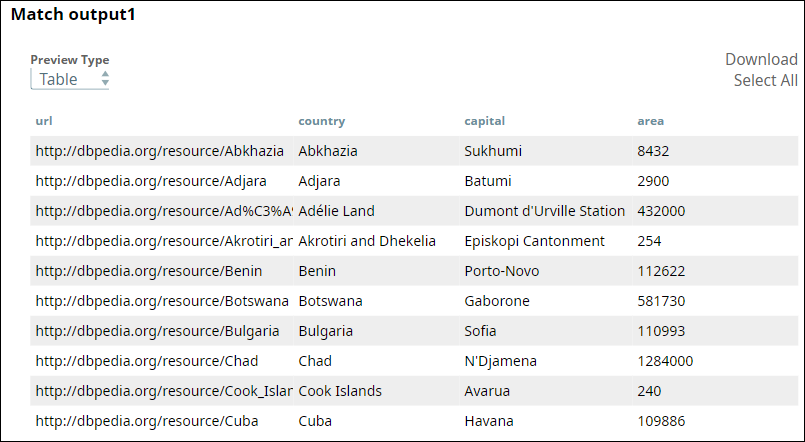
The third output view shows the list of unmatched records from the second input view:
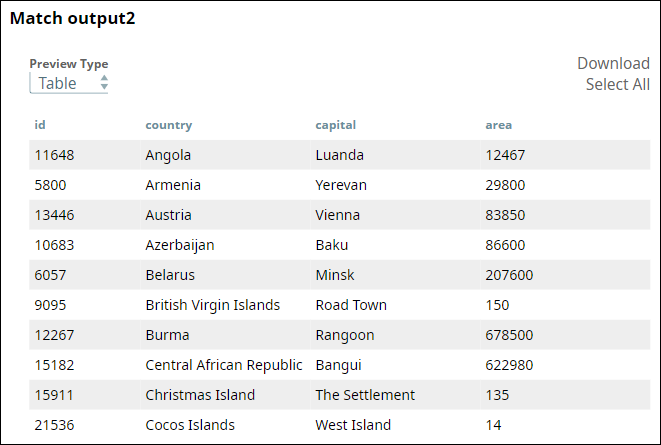
You can now review the matched records to check whether they represent the same entities.
The Match Snap example offers three outputs:
- The list of matched countries
- The list of countries in Country Dataset 1 that could not be matched
- The list of countries in Country Dataset 2 that could not be matched
In the second half of this Pipeline, you review the matched records and tweak the value in the Threshold field of the Match Snap until you arrive at the lowest threshold value that gives you the maximum number of correct matches. You decide to make two copies of the output document containing the list of matched countries. In one of these, you decide to retain the confidence level, so you can sort the results by confidence. In the other, you decide to remove the confidence levels, so you can retain only the data you need. If the output contains wrong matches, increase the threshold. If the output looks great, but you want to see more matches with lower confidence, try lowering the threshold.
To do so, you create two copies of the document containing the matched countries, using the Copy Snap. You now need to generate the following two documents and identify the lowest confidence level that gives you the most number of reliable matches:
- A document containing the matched documents and confidence-level data
- A document containing only the matched fields, which is the main output of this pipeline
Generating a document containing matched fields and confidence-level data
From one copy of the list of matched countries, you use the Mapper Snap to create a document containing the matched countries and their confidence levels: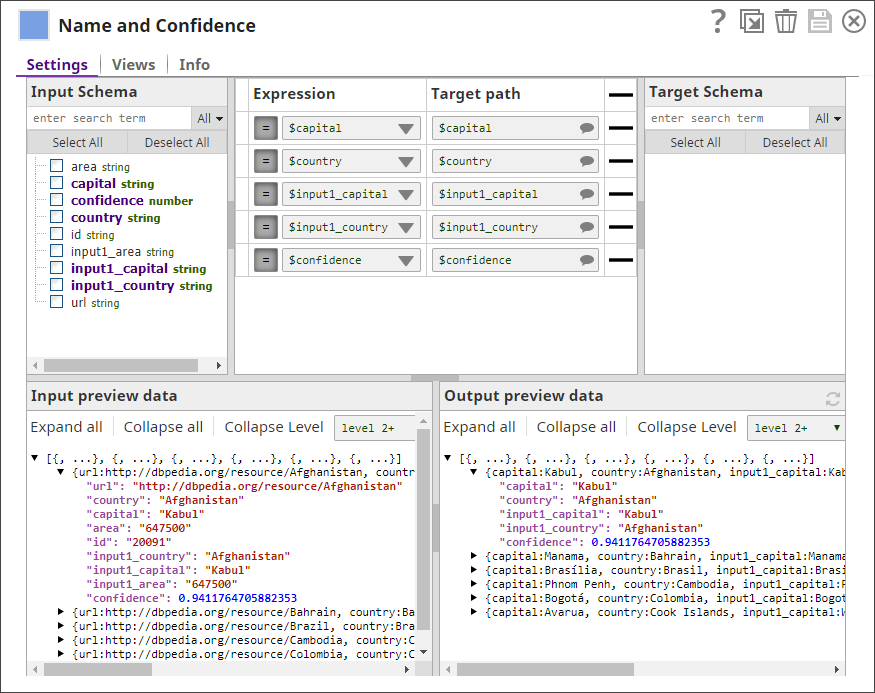
You now sort them based on their confidence levels, so that the countries with the lowest confidence levels will appear at the top of the list: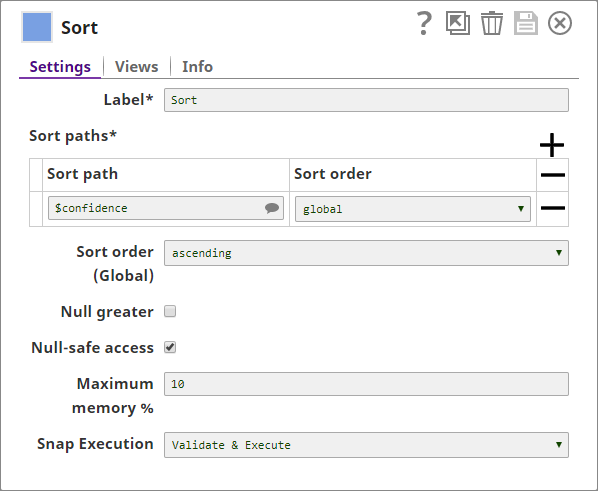
You use a File Writer Snap to write the sorted data into a CSV file: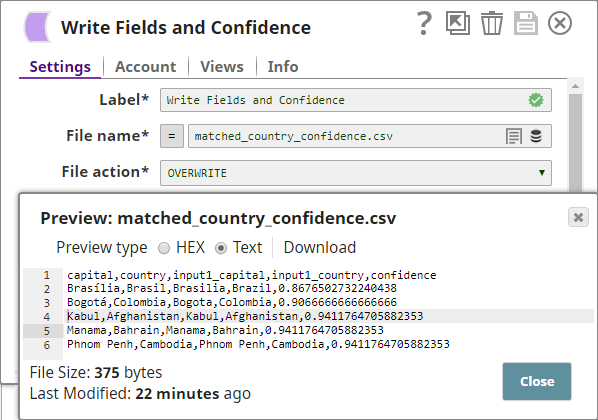
Generating a document containing only matched records
From the other copy, you use the Mapper Snap to create a document containing only the matched countries: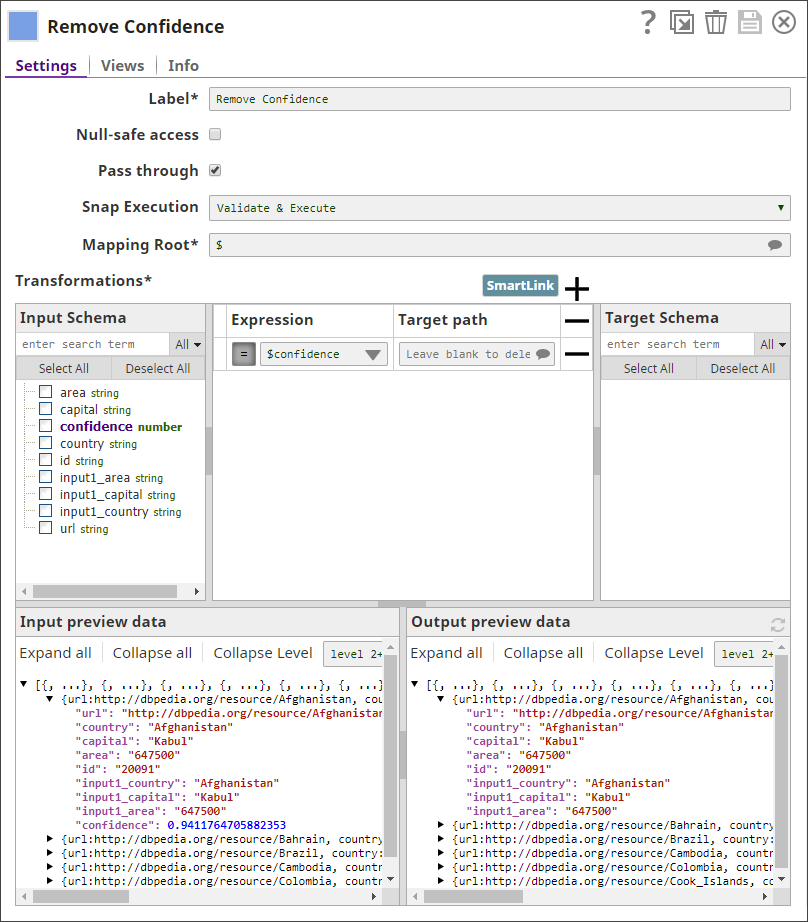
You use a File Writer Snap to write the data into a CSV file: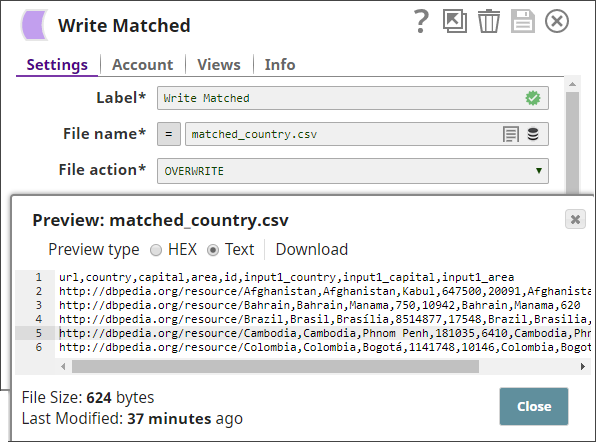
Modifying matching threshold values to improve the result
You now need to iteratively lower the threshold values until you reach a threshold that is best suited to offer the most number of reliable matches. To do so, you execute the Pipeline a number of times, using iteratively lower values in the Threshold field of the Match Snap, until you reach a value below which your output matching data is not reliable. For example, if you decide to lower the threshold value from the default 0.8 to 0.5, you will find an additional row of data displaying inaccurately as matched:
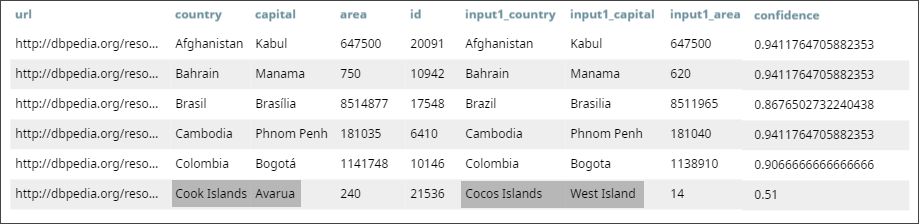
You now know that given this data, the value in the Threshold field must be above 0.51 to be reliable and offer the most number of correct matches.
Download this Pipeline.
Downloads
Important steps to successfully reuse Pipelines
- Download and import the pipeline into the SnapLogic application.
- Configure Snap accounts as applicable.
- Provide pipeline parameters as applicable.
Have feedback? Email documentation@snaplogic.com | Ask a question in the SnapLogic Community
© 2017-2025 SnapLogic, Inc.