Predictor (Regression)
- Ankur Parekh
- Mohammed Iqbal
- Amritesh Singh
On this Page
Overview
This is a Transform type Snap that enables you to predict the target field for an unlabeled document. An unlabeled document is one that does not have a label field. So, the Snap reads this unlabeled document and predicts the target field. Predictions are made based on the regression model built by the Trainer (Regression) Snap.
Input and Output
Expected input: An unlabeled document and the regression model.
Expected output: Predictions from the regression model based on the input document.
Expected upstream Snaps:
- First input view: Any Snap that generates an unlabeled document document. For example, JSON Parser, JSON Generator, CSV Parser, CSV Generator, Mapper, and so on.
- Second input view: Any Snap that reads and outputs the regression model. For example, a combination of File Reader, and JSON Parser.
Expected downstream Snaps: Any Snap that uses the predicted result. For example, Aggregate, or a combination of File Writer and JSON Formatter.
Prerequisites
The input document must be in tabular format (no nested structure).
Configuring Accounts
Accounts are not used with this Snap.
Configuring Views
Input | This Snap has exactly two document input views. The first input view is for the unlabeled document that requires prediction. The second input view is for the regression model. |
|---|---|
| Output | This Snap has exactly one document output view. |
| Error | This Snap has at most one document error view. |
Troubleshooting
None.
Limitations and Known Issues
None.
Modes
- Ultra Pipelines: Works in Ultra Pipelines.
Snap Settings
| Label | Required. The name for the Snap. Modify this to be more specific, especially if there are more than one of the same Snap in the pipeline. |
|---|---|
Snap Execution | Select one of the following three modes in which the Snap executes:
Default Value: Execute only |
Examples
Heating Load Prediction – Testing
The model trained in the Heating Load Prediction – Model Training example pipeline is tested against an unlabeled dataset.
Download this pipeline.
To understand the dataset and the process prior to testing the model see the following examples:
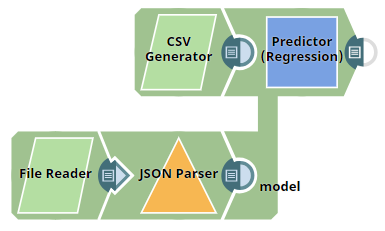
In this example, the unlabeled dataset is created using the CSV Generator Snap. This dataset is used as the data input for the Predictor (Regression) Snap. The target field (heating load) is to be predicted for this dataset.

The model trained in the Heating Load Prediction – Model Training example is used as the model input. The File Reader Snap is configured to read this model from the SLDB. The JSON Parser Snap is used to parse the output from the File Reader Snap. Below is a preview of the output from the JSON Parser Snap (the model):

Model Testing
To test a model trained on a classification dataset, the Predictor (Regression) Snap must be used.
The Predictor (Regression) Snap requires two inputs:
- An unlabeled dataset for the data input
- The ML model trained on the labeled dataset for the model input
The Predictor Snap is configured as shown below:
Based on its configuration, the output from the Snap includes one class prediction per document. This output is as shown below:

Download this pipeline.
Additional Example
The following use case demonstrates a real-world scenario for using this Snap:
Downloads
Important steps to successfully reuse Pipelines
- Download and import the pipeline into the SnapLogic application.
- Configure Snap accounts as applicable.
- Provide pipeline parameters as applicable.
Snap Pack History
Have feedback? Email documentation@snaplogic.com | Ask a question in the SnapLogic Community
© 2017-2024 SnapLogic, Inc.