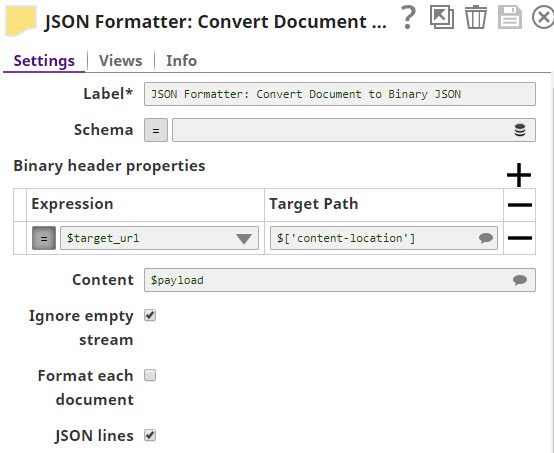
You can use this Snap to read JSON document data from its input view, format and write it as JSON binary data to its output view. This is a Transform Snap type.A schema file can also be attached to the Snap that allows it to share the schema with upstream Snaps like the Mapper Snap.
Prerequisites
None.
Support for Ultra Pipelines
Works in Ultra Tasks if Format each document is selected.
Limitations and Known Issues
None.
Snap Views
Type
Format
Number of views
Examples of upstream/downstream Snaps
Description
Input
Document
Min:1
Max:1
JSON Generator
JSON document data to be formatted
Output
Binary
Min:1
Max:1
Group by Fields
Mapper
JSON binary data stream.
Error
Binary
Error handling is a generic way to handle errors without losing data or failing the Snap execution. You can handle the errors that the Snap might encounter while running the Pipeline by choosing one of the following options from theWhen errors occurlist under theViewstab. The available options are:
Stop Pipeline Execution: Stops the current pipeline execution when the Snap encounters an error.
Discard Error Data and Continue: Ignores the error, discards that record, and continues with the rest of the records.
Route Error Data to Error View: Routes the error data to an error view without stopping the Snap execution.
Suggestion icon (): Indicates a list that is dynamically populated based on the configuration.
Expression icon (): Indicates whether the value is an expression (if enabled) or a static value (if disabled). Learn more about Using Expressions in SnapLogic.
Add icon ( ): Indicates that you can add fields in the field set.
Remove icon (): Indicates that you can remove fields from the field set.
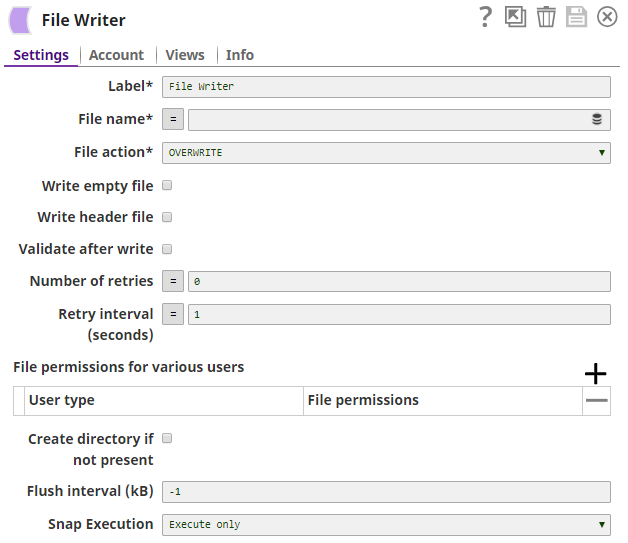
Specify the name for the Snap. You can modify this to be more specific, especially if you have more than one of the same Snap in your Pipeline.
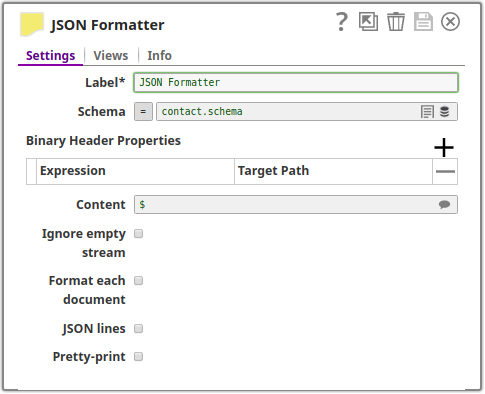
Schema
DefaultValue: None Example: contact.schema
String/Expression
Upload the JSON schema files, especially when the formatted JSON has to follow a certain schema. This is particularly useful when used with the Mapper Snap, the schema from the JSON Formatter Snap will be back-propagated to the Mapper Snap. This is a suggestible property, click on the browse button to select file from your project folder.
The pipeline should be validated once when the schema file has been uploaded in order for the schema to be visible in the upstream Snap.
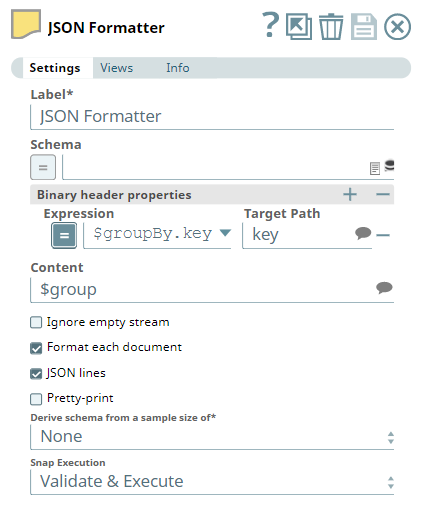
Binary header properties
Use this field set to add properties to the binary document's header. The properties in the header of a binary document can be accessed in expression properties of downstream Snaps. For example, a 'content-location' property added to the header in this Snap can be referenced in the file name property of a File Writer snap with the expression: $['content-location']. When this Snap is configured to output a single binary document, the headers are computed from the first input document. When the "Format each document" option is enabled, the headers are computed separately for each binary output.
Expression
Default Value: None
String/Expression
Specify the function to be used to transform the data such as combine, concat or flatten.
Target Path
Default Value: None Example: $person.firstname to write the field 'firstname' of the 'person' object.
String/Suggestion
Specify the target JSON path where the value from the expression will be written.
Content
Default Value: $
String/Suggestion
Specify the input object or field whose data must be written to the output stream. For example, $group, $payload or $emp_salary. Use $ to write the entire data.
Select this checkbox to ignore empty stream when no document is received at the input view throughout the Pipeline execution. Deselect this checkbox to enable the Snap to write an empty array to the output stream.
Format each document
Default Value:Deselected
Checkbox
Select this checkbox to enable the Snap to create one binary output stream for every document on its input view. Deselect this checkbox to write one binary output stream for all documents on its input view which are enclosed by a JSON array element [ .. ]. See the example: Using JSON Formatter Snap to render outputs from Group By Snaps, for a simple but less-frequent scenario.
For Data Groups in Input View
Select this checkbox along with JSON lines checkbox and set the Content field to $group to output one document per group with member in the group as a separate JSON line.
JSON lines
Default Value: Deselected
Checkbox
Select this checkbox to enable the Snap to write all documents to a single output file, with each document appearing as a single line followed by a new line. This field cannot be used with Pretty-printcheck box. See the example: Using JSON Formatter Snap to render outputs from Group By Snaps, for a simple but less-frequent scenario.
For Data Groups in Input View
Select this check box along with Format each document check box and set the Content field to $group to output one document per group with each member in the group as a separate JSON line.
Pretty-print
Default Value: Deselected
Checkbox
Select this checkbox to format the output to make it more readable/printable.
Derive Schema from a Sample Size of*
Default Value:
Dropdown list
Select the size of the number of initial input documents to be used when deriving the schema to be added to the binary output header. The sizing that you choose depends on the uniformity of the source schema. For example, if the schema is uniform across the documents, then choose Small. If the schema differs from document to document, then choose a larger size (Medium or Large) to attain a more accurate sampling of your schema. The performance impact on the Pipeline execution/validation is greater, the larger the sample size is. If you select None, then the schema is not sampled.
Support Type Extensions
Default Value: Deselected
Checkbox
Select this checkbox to enable the Snap to format/parse the Snaplogic-specific syntax indicating objects of the special types,such as byte arrays and date objects in JSON. For more information, see the Input Schema Types example.
Snap Execution
Default Value: Validate & Execute Example: Execute only
Dropdown list
Select one of the three modes in which the Snap executes. Available options are:
Validate & Execute: Performs limited execution of the Snap, and generates a data preview during Pipeline validation. Subsequently, performs full execution of the Snap (unlimited records) during Pipeline runtime.
Execute only: Performs full execution of the Snap during Pipeline execution without generating preview data.
Disabled: Disables the Snap and all Snaps that are downstream from it.
Examples
Render outputs from Group By Snaps
This example demonstrates how to render groups data from upstream Snaps such as Group By Fields Snap.
In a scenario where the JSON Formatter Snap needs to format data groups, you can enhance the Snap's output to format each group as a separate document, where each line is a member of the group.
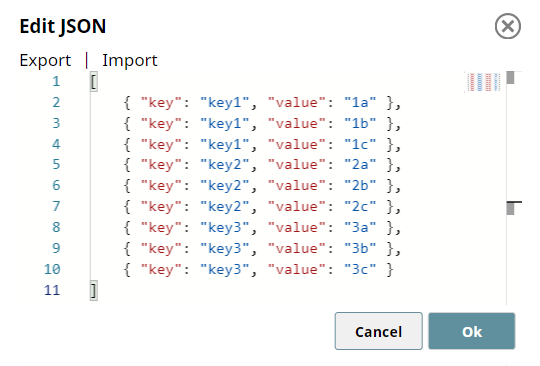
Configure the JSON Generator Snap to pass the raw JSON content to be formatted.
JSON Generator Snap
Output (JSON content to be formatted)
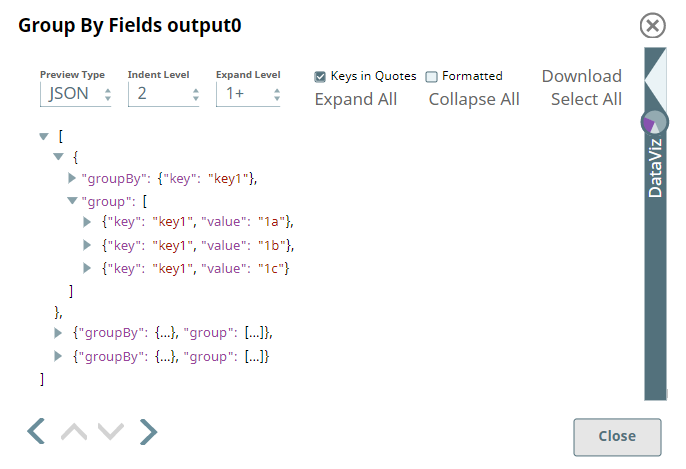
The Group By Fields Snap is set to group the incoming data by $key with the Target field as $group.
Group By Fields Snap
Output (Raw JSON rendered into groups)
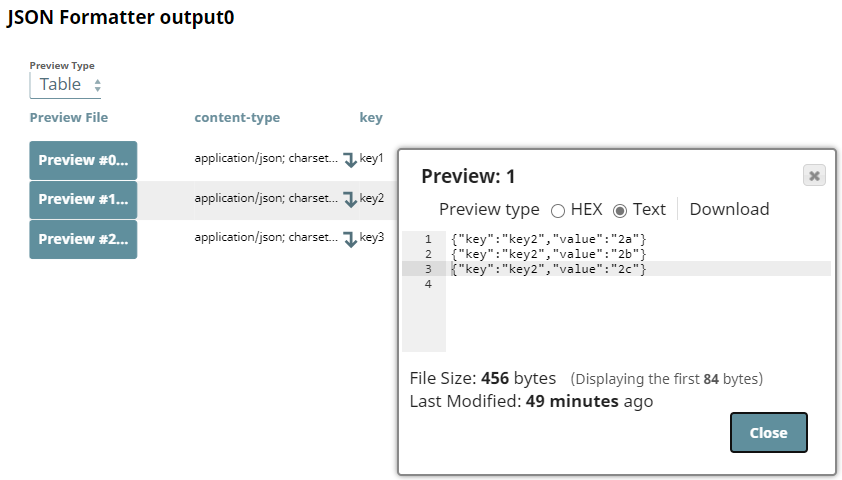
Notice that the incoming data is grouped by key in this output.
JSON Formatter Snap
Output (one document per group and one line per group member)
When the JSON Formatter Snap received data groups, we can select the fields JSON lines and Format each document checkboxes in unison and the Snap formats the content as multiple documents – one per group (key1, key 2 and key3 in this example) with one line for each element in these groups.
Using the sample Pipeline shown above, generate a JSON document using the JSON Generator Snap.
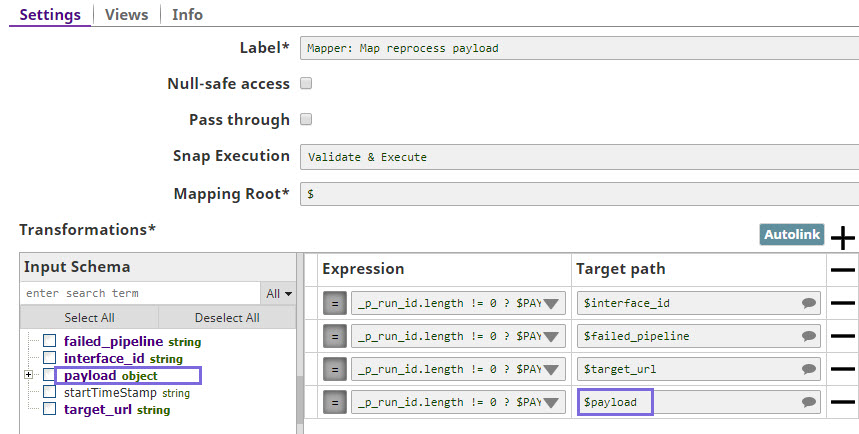
In the Mapper Snap, map the input fields: interface_id, failed_pipeline, target_url, and payload to the required output fields.
In in the JSON Formatter Snap, in the Content field under Settings select $payload as the object to be included in the output.
Select the JSON lines check box to ensure each record appears as a separate line in the output file.
Provide the name of the file to write to in the File Writer Snap and save it.
Validate and execute the Pipeline.
Current behavior
Old behavior
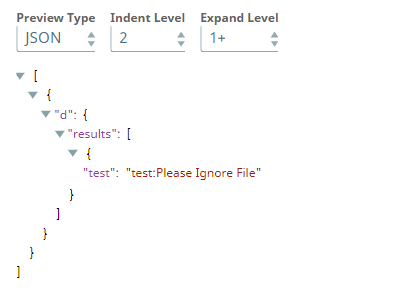
With Patch transform8670 onwards, the JSON Formatter Snap correctly acknowledges the Content field, irrespective of the JSON lines check box selection. So, in this example, the output would contain only the specified object’s data ($payload):
Prior to Patch transform8670, the JSON Formatter Snap would ignore the value in the Content field and write the entire input data to the output file if the JSON lines check box was selected, as shown in the image below:
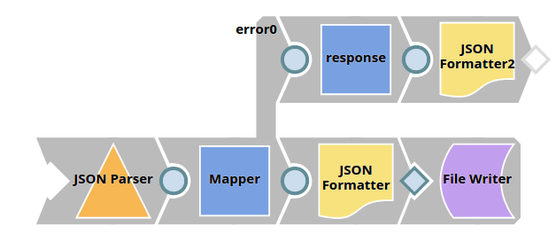
Pass the Execution Status Code through Binary Header Properties of the JSON Formatter Snap
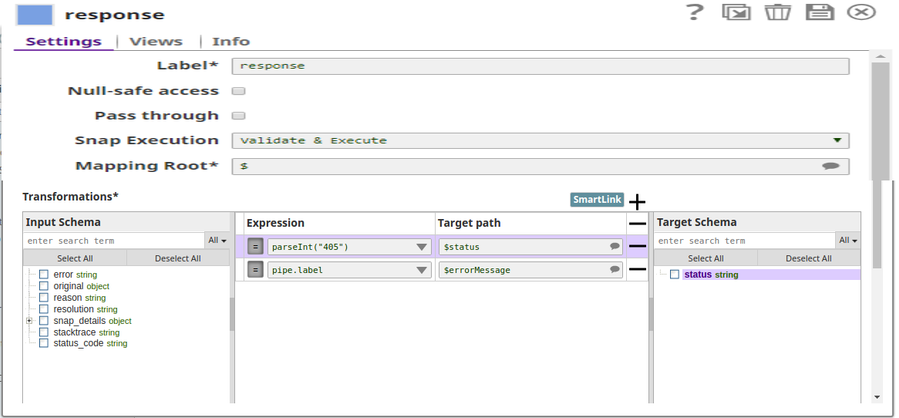
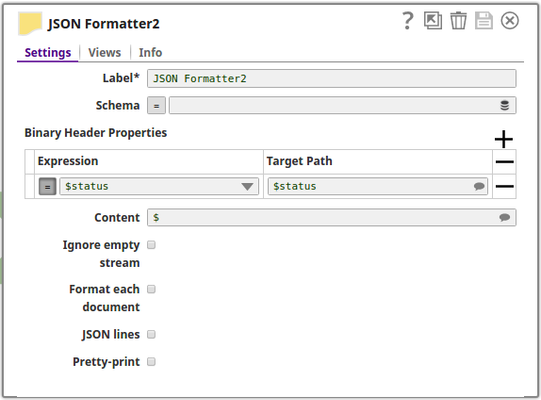
In this pipeline, the pipeline execution status is routed to the error view, which is redirected to reflect on the browser using the Binary Header Properties of the JSON Formatter Snap. This allows us to view the status on the browser same as on the output view of the triggered pipeline.
This workaround of using the Binary Header properties is mainly useful when the user wants to view the exact execution status of the triggered task which may or may not be consistent with the status code otherwise reflected on the browser.
The JSON Formatter Snap passes the actual status code to the browser via the Binary Header Properties:
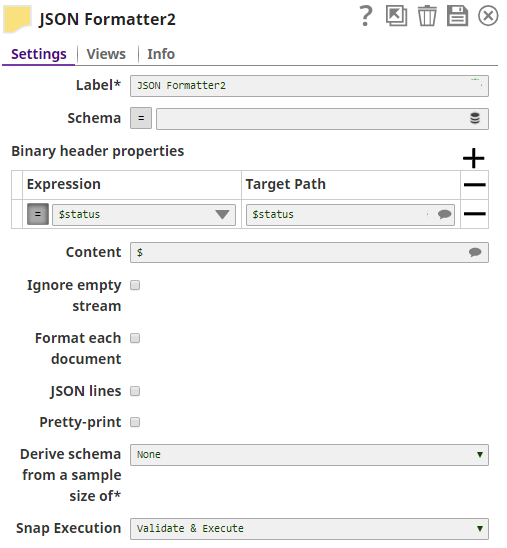
The status code (405) as retrieved from the pipeline is mapped to the response:
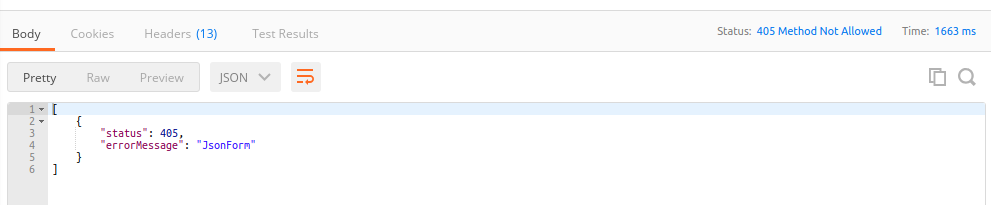
The JSON Formatter Snap passes the actual status code to the browser via the Binary Header Properties:
The status code(405)as reflected on the browser (Postman):
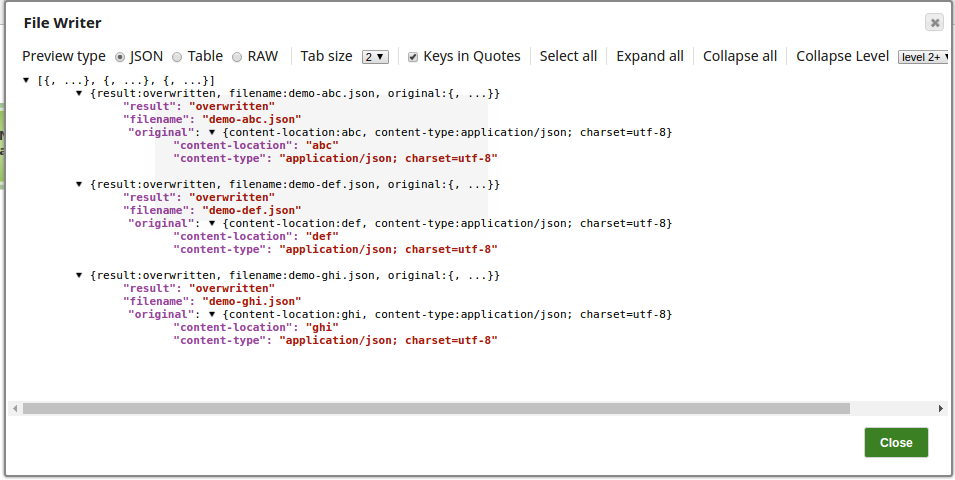
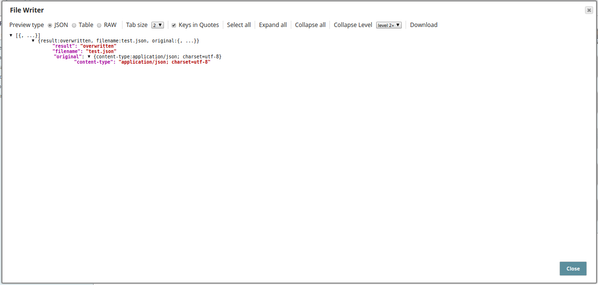
Create a File with Header Value in a Specific Location
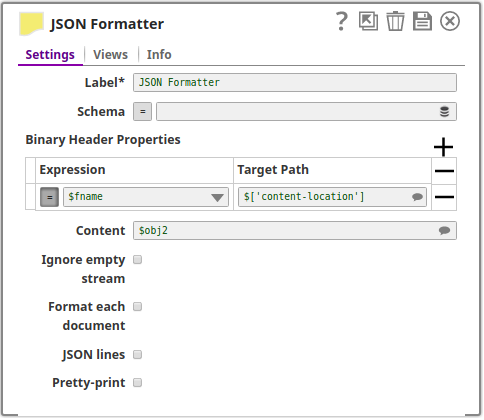
In this pipeline, the JSON Formatter Snap, creates a file with a header value on a specified location. The metadata is passed to the File Writer Snap using the Binary Header and the Content properties on the JSON Formatter Snap.
The JSON Generator Snap passes the values for the file and the records to be created.
The JSON Formatter Snap passes the metadata to the File Writer Snap.
The File Writer Snap creates the file "demo-" + $['content-location'] + ".json" on a specified content location.
The successful execution of the pipeline displays the below output preview:
Note the file headers created on the sldb location, and the files names as demo-abc.json and so on.
Schema Suggest to Upstream Snap
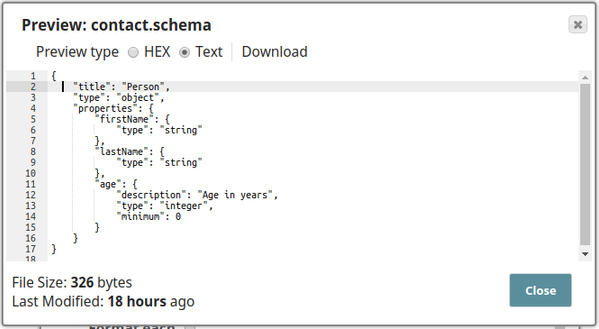
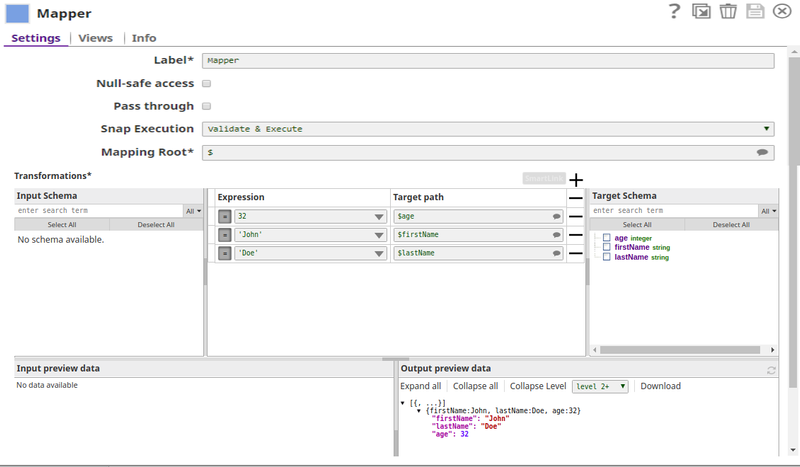
In the example pipeline, Basic Use Case_JSON Formatter Schema Property, the Mapper Snap is used to write employee data into a file. The input data has to cater to a specified JSON schema, to enable this the Schema property is configured with a schema file. this allows the user to see the schema of the target file in the Mapper Snap.
The JSON Formatter Snap is configured in the following manner, the schema file contact.schema is uploaded in the Schema property:
The schema defined in the contact.schema file is shown below:
Below is the Mapper Snap's configuration, note the Target Schema and the Output preview data sections where the schema of the target file and the mapped data are shown:
When executed the input record from the Mapper will be mapped to the specified path based on the target schema and written into the target file.
Exported pipeline is available in the Downloads section below.
Updated the Apache POI (Poor Obfuscation Implementation) library from 4.1.2v to 5.2.5v in the Excel Parser Snap to fix the null pointer exception issue.
February 2025
main29887
Stable
Updated and certified against the current SnapLogic Platform release.
November 2024
439patches29700
Latest
Improved Join Snap’s resource management to detect output stream closure failures, throwing an exception at the debug log level for better diagnostics.
November 2024
439patches29416
Latest
Minimized the possibility of out-of-memoryerrors and the memory leak issue in the Join Snap.
November 2024
439patches29078
Latest
Fixed an issue with the CSV Parser Snap that introduced unexpected characters into the records and output data because of incorrect handling of the delimiter.
November 2024
main29029
Stable
Updated and certified against the current SnapLogic Platform release.
August 2024
438patches28073
Latest
Fixed an issue with the JSON Generator and XML Generator Snaps that caused unexpected output displaying '__at__' and '__h__' instead of '@' and '-' respectively because the Snap could not update them to their original values after the Velocity library upgrade.
August 2024
438patches27959
Latest
Fixed an issue with the Sort where the Snap could not sort files larger than 52 MB. This fix applies to Join Snap also.
August 2024
main27765
Stable
Upgraded the org.json.json library from v20090211 to v20240303, which is fully backward compatible.
May 2024
437patches26643
Latest
Fixed an issue with the Sort Snap that displayed an error when estimating the size of the input document provided by the upstream S3 Browser Snap.
Fixed an issue with the Parquet Formatter Snap that was unable to route errors to the error view.
May 2024
437patches26453
Latest
Added expression support to the Skip lines field in the CSV Parser Snap to enable passing pipeline parameters and upstream values.
Fixed an issue with the XML Parser Snap that caused an error when using the Splitter option in the Snap settings.
May 2024
main26341
Stable
Added Parquet Parser and Parquet Formatter Snaps to the Transform Snap Pack:
Parquet Parser: Reads the binary Parquet data and writes document data to the output.
Parquet Formatter: Reads the document data and writes it to the output in binary Parquet format.
Enhanced the JSON Splitter Snap to capture metadata and lineage information from the input document.
February 2024
436patches25564
Latest
Fixed an issue with theJSON FormatterSnap that generated incorrect schema.
February 2024
436patches25292
Latest
Fixed an out-of-memory error issue with the Aggregate Snap. This Snap no longer performs the presort for the input documents.
If the input documents areunsorted and GROUP-BY fields are used, you must use the Sort Snap upstream of the Aggregate Snap to presort the input document stream and set the Sorted stream field Ascending or Descending to prevent the out-of-memory error. However, if the total size of input documents is expected to be relatively small compared to the available memory, then Sort Snap is not required upstream.
Updated and certified against the current SnapLogic Platform release.
November 2023
435patches24802
Latest
Fixed an issue with the Excel Parser Snap that caused a null pointer exception when the input data was an Excel file that did not contain a StylesTable.
November 2023
435patches24481
Latest
Fixed an issue with the Aggregate Snap where the Snap was unable to produce the desired number of output documents when the input was unsorted and the GROUP-BY fields field set was used.
November 2023
435patches24094
Latest
Fixed a deserialization issue for a unique function in the Aggregate Snap.
November 2023
main23721
Stable
Updated and certified against the current SnapLogic Platform release.
August 2023
434patches23076
Latest
Fixed an issue with the Binary to Document Snap where an empty input document with Ignore Empty Stream selected caused the Snap to stop executing.
August 2023
434patches23034
Latest
Fixed an issue with the Transform Snap Pack that caused an error when the input file was a binary JSON file that contained a string value of more than 20,000,000 characters.
Fixed a memory issue with the Aggregate Snap that occurred when using GROUP-BYfields.
August 2023
434patches22705
Latest
Fixed an issue with the JSON Splitter Snap that caused the pipeline to terminate with excessive memory usage on the Snaplex node after the 4.33 GA upgrade. The Snap now consumes less memory.
August 2023
main22460
Stable
Updated and certified against the current SnapLogic Platform release.
May 2023
433patches22431
Latest
Fixed an issue with the Excel Multi Sheet Formatter Snap that caused it to produce binary output data when there was no input document and Ignore empty stream was selected.
Introduced the following new Snaps:
GeoJSON Parser: Parses geospatial data from binary data input and outputs the contents as a GeoJSON document downstream.
WKT Parser: Parses geospatial data from binary data input and outputs the contents as a WKT (Well Known Text) document downstream.
May 2023
433patches21779
Latest
The Decrypt Field and Encrypt Field Snaps now support CTR (Counter mode) for the AES (Advanced Encryption Standard) block cipher algorithm.
May 2023
433patches21586
Latest
The Decrypt Field Snap now supports the decryption of various encrypted fields on providing a valid decryption key.
Fixed an issue with the AutoPrep Snap where dates could potentially be rendered in a currency format because currency format options were displayed for the DOB column.
May 2023
433patches21196
Latest
Enhanced the In-Memory Lookup Snap with the following new fields to improve memory management and help reduce the possibility of out-of-memory failures:
Minimum memory (MB)
Out-of-memory timeout (minutes)
These new fields replace the Maximum memory % field.
May 2023
main21015
Stable
Upgraded with the latest SnapLogic Platform release.
February 2023
432patches20535
Latest
Fixed an issue with the Encrypt Field Snap, where the Snap failed to support an RSA public key to encrypt a message or field. Now the Snap supports the RSA public key to encrypt the message.
The Pipeline Execution Statistics of the Join Snap now has a status message that displays the parameters - Free disk space, Available memory, and Average document size.
The internal sort buffer size is reduced to a minimum of 10MB when the available memory in the node becomes lower than 500MB to avoid the out-of-memory crash.
The internal sort buffer size is restored to its original size when the available memory becomes larger than 2GB.
We have improved the readability of the error message for the out of disk space on node error. The updated error message now provides clearer information and guidance for users, as shown below: Reason: Insufficient free disk space available to stage sort data into temporary files. Resolution: Increase the amount of free disk space and try again.
February 2023
432patches20250
Latest
Fixed an issue with the JSON Splitter Snap that was causing errors when using multiple repeated dots in the JSON Path.
The Sort Snap includes the following improvements:
The Maximum memory % field is revised to Maximum memory.
The Maximum memory unit (new dropdown list) enables you to choose a unit, percentage (%), or MB for better memory control.
February 2023
432patches20151
Stable/Latest
Fixed an issue that occurred with the JSON Splitter Snap when used in an Ultra pipeline. The request was acknowledged before it was processed by the downstream Snaps, which caused a 400 Bad Request response.
February 2023
432patches20062
Stable/Latest
Fixed the behavior of the JSON Splitter Snap for some use cases where its behavior was not backward compatible with the 4.31 GA version. These cases involved certain uses of either the Include scalar parents feature or the Include Paths feature.
February 2023
432patches19974
Stable/Latest
Fixed the "Json Splitter expects a list" error by restoring the JSON Splitter Snap's previous behavior of handling the case where the document element referenced by the JSON Path to Split field is an object instead of a list or array.
Review your pipelines where this error occurred to check your assumptions about the input to the JSON Splitter and whether the value referenced by the JSON Path to Split field will always be a list. If the input is provided by an XML-based or SOAP-based Snap like the Workday or NetSuite Snaps, a result set or child collection that’s an array when there's more than one result or child will be an object when there's only one result or child. In these cases, we recommend using a Mapper Snap and the sl.ensureArray() function to ensure that the value being split by the JSON Splitter is always an array (even for the single element cases).
February 2023
432patches19918
Stable/Latest
Fixed an issue with the CSV Formatter Snap where the Unicode character delimiters using [0-9a-f] did not work.
Fixed an issue with the JSON Splitter Snap that was generating null values for empty input data.
February 2023
main19844
Stable
Upgraded with the latest SnapLogic Platform release.
The Transform Join Snap now doesn’t fail with the Null Pointer Exception when you configure the Sorted streams field with Ascending.
November 2022
431patches19359
Latest
The JSON Splitter Snap includes memory improvements and a new Exclude List from Output Documents checkbox. This checkbox enables you to prevent the list that is split from getting included in output documents, and this also improves memory usage.
The Mapper Snap now has a Sorted checkbox in the Input Schema and Target Schema panels, which allows you to sort the input and target schemas. When unchecked, the Snap unsorts the input and the target schema.
October 2022
430patches18800
Latest
The Sort and Join Snaps now have improved memory management, allowing used memory to be released when the Snap stops processing.
The AutoPrep feature now includes the following new transformation options that enable you to:
Change the field data type from Data type menu.
Format dates and date Strings.
Rename a field.
Mask sensitive data using an MD5, SHA-1, SHA-256, or SHA-512 algorithm.
The data in the Preview data pane format is easier to read and the buttons have been changed to improve usability.
The CSV Parser Snap now parses data with empty values in the columns when using a multi-character delimiter.
September 2022
430patches18119
Latest
The Transcoder Snap used in a low-latency feed Ultra Pipeline now acknowledges the requests correctly.
September 2022
430patches17802
Latest
The Avro Parser Snap now displays the decimal number correctly in the output view if the column’s logical type is defined as a decimal.
September 2022
430patches17737
Stable/Latest
AutoPrep now enables you to handle empty or null values.
September 2022
430patches17643
Latest
The CSV Parser and CSV Formatter Snaps now support either \ or \\ for a single backslash delimiter which were failing earlier.
September 2022
430patches17589
Latest
The CSV Formatter Snap does not hang when running in specific situations involving multibyte characters in a long field. If you notice the CSV Formatter Snap is hung, we recommend that you update to the 430patches17589 version and restart your Snaplex.
August 2022
main17386
Stable
New Snap Application: The Auto Prep Snap provides a data preparation application where you can flatten structured data, include and exclude data fields, and change data types before forwarding the data for further processing.
The Hide whitespace option in the CSV Generator and JSON Generator Snaps allows you to hide the rendering of whitespace as symbols (dot or underscore) in the output that you may have in the CSV or JSON input documents.
The Render whitespace checkbox in the Mapper Snap enables or disables the rendering of whitespace in the input document. When a value in the Expression field has blank spaces (leading, trailing, or spaces in the middle of a string), the spaces are rendered as symbols (dot “.” or underscore “_”) in the output on selecting this checkbox.
The Excel Parser Snap includes the Custom Locale dropdown list that allows selecting a user-defined locale for formatting numbers..
The Selected fields inthe Pivot Snap allow you to define fields to be unpivoted so that the remaining fields are automatically pivoted.
The XML Generator Snap includes examples on how to escape single (') and double quotes (“) when used with elements or attributes.
4.29 Patch
429patches16990
Latest
Fixed an issue with the Aggregate Snap where the Snap failed to validate (after first successful validation) while using a field that may contain a date for MIN and MAX functions. The Snap now supports DATE-type fields.
Enhanced the Pivot Snap with the Treat selected fields as static checkbox that enables the Snap to treat the selected fields as static to preserve the structure of the selected fields while all other fields are pivoted.
4.29 Patch
429patches16923
Latest
Enhanced the CSV Formatter and CSV Parser Snaps to support multiple characters or strings as delimiters.
Fixed an issue with the Join Snap where the Snap displayed an incorrect error if the Left path or Right path fields were expression-enabled or if you have specified properties other than the field name and irrespective of whether the Sorted streams field is Unsorted or not. For example, "$first + '2' . Now, the Snap runs properly if the Left path or Right path was expression enabled and you have specified properties other than the field name and the Sorted streams field is Sorted or Unsorted. The Snap now displays a proper error that is more informative, in case there is a problem while executing this Snap.
Fixed an issue with CSV Parser Snap where the Snap failed when more than six characters are used as delimiters. Now, the Snap executes properly when you use more than six characters as delimiters.
4.29 Patch
429patches16521
Latest
Removed the default value for the Root element field in the XML Formatter Snap.
Fixed an issue with the Transcoder Snap where the Input character-set field was not displaying the suggestions properly.
4.29 Patch
429patches16026
Latest
Enhanced the Excel Parser Snap with the Custom Locale dropdown list that allows you to select a user-defined locale to format numbers as per the selected locale.
4.29
main15993
Stable
Fixed an issue with CSV Formatter and CSV Generator Snaps that displayed an incorrect error when one or more header values in the CSV file were missing. This error is now routed to the error view.
Fixed an issue with the CSV Parser Snap, where the Snap stopped indefinitely while processing certain inputs.
Fixed an issue with the CSV Formatter Snap, where the escape character selected was not used.
Updated the CSV library used in the CSV Generator, CSV Parser, and CSV Formatter Snaps. This library update enforces values for each column in a parsed CSV header.
Enhanced the XML FormatterSnap with theOutput Character Setfield. You can select the character set you want for your binary output. For example, UTF-8 or ISO860.
4.28 patch
428patches14370
Latest
Fixed an issue with the XML Generator Snap, where the Snap failed with an invalid UTF-8 sequence error when running on the Windows Snaplex.
4.28
main14627
Stable
Upgraded with the latest SnapLogic Platform release.
4.27 Patch
427patches12966
Latest
Enhanced the Avro Formatter Snap to display meaningful error message while processing invalid and null values from the input.
4.27
main12989
Stable and Latest
Fixed an issue in the Group by Fields Snap that caused the Snap to abort with an error when executed with zero input documents.
4.27
main12833
Stable
Added dynamic memory management to theGroup By FieldsSnap, which can activate with the following settings:
Memory Sensitivity: The Snap's response to the memory changes.
Min Part Size: The minimum part size that you want the Snap to split larger groups into multiple parts.
Enhanced the JSON Formatter, JSON Generator, and JSON Parser Snaps with the Support Type Extensionscheckbox. On selecting this checkbox, the Snap supports SnapLogic-specific syntax for representing non-standard data types such as byte arrays and date objects in JSON.
Convert numeric string to number: Sets the behavior of the Snap when a value in the input document is a numeric string. This checkbox supports the conversion of numeric values to string values.
Translate date and time types: Sets the behavior of the Snap when a value in the input document is a date and datetime type. This checkbox supports translating date and time types to Excel date numeric type with date format style.
4.26 Patch
426patches12086
Latest
Fixed an issue with theJoinSnap, where it exhausted the memory while buffering millions of objects.
4.26 Patch
426patches11780
Latest
Fixed an issue in the XML Formatter Snap, where theMap input to first repeating element in XSD checkbox is selected, while no XSD is specified for mapping the input.
4.26 Patch
426patches11725
Latest
Fixed an issue with the JoinSnap where the upstream document flow of the right view is blocked by the left view, which hung the Join Snap.
4.26
main11181
Stable
Enhanced the JSON Splitter Snap with a new field Show Null Values for Include Paths that enables the Snap to show key-value entries of the null values for the objects added to the Include Paths field in the output document.
Enhanced the Join Snap with a new field Available Memory Threshold (%) that enables the Snap to keep all the Right-input view documents with the same join-path values in memory until the join operation is done for the specific join-path values.
4.25 Patch
425patches10663
Latest
Fixed an issue in the CSV Formatter Snap,where even if theIgnore empty streamcheckbox is not enabled, the Snap did not produce an empty binary stream output in case there is no input document.
4.25 Patch
425patches10152
Latest
Replaced the Strict XSD output field with Map input to first repeating element in XSD field in the XML Formatter Snap. If selected, the Snap ignores the root element from the XSD file.
Enhanced the CSV Parser Snap with a new checkbox Preserve Surrounding Spaces that enables you to preserve the surrounding spaces for the values that are non-quoted.
4.25 Patch
425patches9815
Latest
Fixed a ClassCastExceptionerror in the Avro Parser Snap and handling of themap, fixed, enum, and bytes data types in theAvro Formatter and Avro Parser Snaps.
4.25 Patch
425patches9749
Latest
Enhanced XML Parser Snap to recognize input headers when defining inbound schema.
4.25 Patch
425patches9638
-
Latest
Reverts the Join Snap to the 4.24 release behavior. This is in response to an issue encountered in the Join Snap in the 4.25 release version (main9554), which can result in incorrect outputs from all Join Types. 425patches9638 is the default version for both stable and latest Transform Snap Pack versions for orgs that are on the 4.25 release version. No action is required by customers to receive this update and no impact is anticipated.
4.25
main9554
Stable
Enhanced the Group By N Snap with the following settings:
Memory Sensitivity: The Snap'sresponse to the memory changes.
Group Size:The maximum number of input documents to be grouped into a single output document.
Min Group Size: The minimum number of input documents to be grouped into a single output document.
4.24 Patch
424patches8938
Latest
Fixed the timestamp issue in the JSON Formatter Snap that changed the time zone offset to include colon by default after upgrading to 4.24.
Fixed the null pointer exception at runtime in the Fixed Width Parser Snap by setting the Trim column data field to false for empty columns.
Enhances the Group By N Snap to process the records efficiently by adding the FlushTimeout field that enables the Snap to flush a partial group of records if the time specified in this field passes with no new input.
4.24
main8556
Stable
Upgraded with the latest SnapLogic Platform release.
4.23 Patch
423patches7958
Latest
Fixes an issue in theJSON Splitter Snap by logging an error when the matcher does not find a pattern.
4.23 Patch
423patches7898
Latest
Fixes an issue in the In-Memory Lookup Snap to correctly handle the Join path in the format like $['join path'].
Fixes an issue in the XSLT Snap, wherein null binary header values are now converted to blank strings when injecting them as parameters in the stylesheet.
4.23 Patch
423patches7792
Latest
Fixes an issue in the XML Formatter Snap when it fails to convert input JSON data, with JSON property having a special character as its prefix, to XML format by sorting the elements.
4.23 Patch
423patches7753
Latest
Fixes an issue with the JSON Splitter Snap's behavior in Ultra Pipelines that prevents processed requests to be acknowledged and removed from the FeedMaster queue, resulting in retries of requests that are already processed successfully.
4.23
main7430
Stable
Enhances the JSON FormatterSnap to render groups output from upstream (Group by) Snaps with one document per group and a new line per group element.You can now select the Format each documentandJSON lines check boxes simultaneously.
4.22 Patch
422patches6395
Latest
Fixes the JSON Splitter Snap data corruption issue by copying the data in JSON Splitter Snap before sending it to other downstream Snaps.
4.22 Patch
422patches6505
Latest
Fixes the XML Generator Snap issue reflecting empty tags and extra space by removing the extra space in the XML output.
4.22
main6403
Latest
Upgraded with the latest SnapLogic Platform release.
4.21 Patch
421patches5901
Latest
Enhances the JSON Generator Snap to include pass-through functionality where the Snap embeds the upstream input document under the original field of the output document along with other records.
4.21 Patch
421patches5848
Latest
Fixes the Sort Snap that fails while performing sorting, displaying a NoClassDefFoundError.
Fixes the Excel Formatter Snap that fails to create an empty worksheet when you do not select the Ignore Empty Stream checkbox.
4.21
snapsmrc542
-
Stable
Adds support in the Mapper Snap to display schemas with complex nesting. For example, if Snaps downstream from the
4.20 Patch
transform8792
-
Latest
Resolves the NoClassDefFoundError in the Join Snap on Windows Snaplex instances.
4.20 Patch
transform8788
-
Latest
Resolves the NullPointerException in the Join Snap on Windows Snaplex instances.
4.20 Patch
transform8760
-
Latest
Fixes an issue with the CSV Parser Snap wherein the Snap fails when it is configured in the new Form UI if the Contains headers and Validate headers fields are not selected but empty rows exist in the Column names field.
Fixes the JSON Formatter Snap to filter the input data based on the value specified in the Content field in the Snap settings when the JSON lines field is also selected. Previously, the Snap was writing the entire input data to the output file.
The JSON Formatter Snap output now includes only those fields from the input file that are specified in the Content field under Settings.
If your Pipelines use the JSON Formatter Snap with the JSON lines field selected, they may fail to execute correctlyif the Content field mentions a specific object or field but the downstream Snap is expecting the entire data. Hence, for backward compatibility, you must review the entries in the Content field based on the desired output, as follows:
Enter $ to include all the fields in the output. OR
Enter or select the specific fields to restrict the output to.
The behavior of the Snap when the JSON lines field is not selected is correct and remains unchanged.
Fixes an issue in the XML Generator Snap due to which the custom XML data in the Edit XML field got ignored when inbound schema and root XML element were also provided, and instead, the output was generated from upstream data. For Pipelines with a standalone XML Generator Snap, a "Premature end of file"error was displayed.
XML Generator Snap behavior might break existing Pipelines
The XML Generator Snap now gives precedence to any custom XML data that is provided over data coming from upstream Snaps,to generate the output.
Existing Pipelines using the XML Generator Snap may fail in the following scenarios. Use the resolution provided to update the Snap settings based on the XML data you want to pass to downstream Snaps.
Breaking Scenario
Resolution
Downstream Snaps expect XML output from upstream Snaps, but custom XML data exists in the XML Generator Snap.
To use custom XML data, ensure that the Inbound schema and XML root element are specified and custom XML data is entered using the Edit XML option.
To use data from upstream Snaps, ensure that theInbound schemaand XML root element fieldsare blank and no custom XML data exists in the XML editor.
In the XML Generator Snap settings, the XML root element and Inbound schema are specified but no custom XML data is provided. This will generate a validation error.
In the XML Generator Snap settings, custom XML data is provided and Validate XML checkbox is selected, but XML root element and Inbound schema are not specified. This will generate a validation error.
4.20 Patch
transform8738
-
Latest
Fixes the error that occurs while transforming an XML document into a string or while using the Excel Formatter Snap by retaining only one version of the Saxon library – net.sf.Saxon: Saxon-HE:9.6.0-10 across the Transform Snap Pack.
Fixes null handling in the Aggregate Snap whereby changing the order of entries in the Aggregate fields fieldset results in different outputs when the input documents contain one or more null values.
Fixes the issue with the Excel Parser Snap whereby the Snap does not parse the date and time correctly for custom date formats.
4.20
snapsmrc535
-
Stable
Upgraded with the latest SnapLogic Platform release.
4.19 Patch
transform8280
-
Latest
Fixed an issue with the Excel Parser Snap wherein the Snap incorrectly outputs Unformatted General Number format.
4.19
snaprsmrc528
-
Stable
The output of the AVG function in the Aggregate Snap now rounds up all numeric values that have more than 16 digits.
4.18 Patch
transform8199
-
Latest
Fixed an issue with the Excel Multi Sheet Formatter Snap wherein the Snap fails to create sheets in the expected order.
4.18 Patch
transform7994
-
Latest
Added a field, Round dates, to the Excel Parser Snap which enables you to round numeric excel data values to the closest second.
4.18 Patch
transform7780
-
Latest
Fixed an issue with the Excel Parser Snap by upgrading Apache POI to version 3.14, wherein the Snap is unable to parse an excel file with custom namespaces.
Fixed an issue with the Excel Parser Snap wherein the Snap converts real numbers to two decimal places when formatted for currency. A new property Cell formatting now supports unformatted outputs.
4.18 Patch
transform7741
-
Latest
Fixed an issue with the Sort and Join Snaps wherein the platform removes all temp files at the end of Pipeline execution.
4.18 Patch
transform7711
-
Latest
Fixed an issue with the XML Parser Snap wherein a class cast exception occurs when the Snap is configured with a Splitter and Namespace Context.
4.18
snapsmrc523
-
Stable
Enhanced the sort feature of the Sort Snap to support specifying sort order at the field level. Added two new fields,Sort PathandSort Order, to theSort pathsproperty; renamed the Sort order property to Sort order (Global).
Enhanced the Group Size property of the Group by N Snap to be expression enabled and removed the upper bound threshold (of 10000).
4.17 Patch
Transform7431
-
Latest
Added a new field, Ignore empty stream, to the Avro Formatter Snap that writes an empty array in the output in case of no input documents.
4.17 Patch
Transform7417
-
Latest
Added a new field, Format as canonical XML, to the XSLT Snap that enables canonical XML formatting.
4.17 Patch
ALL7402
-
Latest
Pushed automatic rebuild of the latest version of each Snap Pack to SnapLogic UAT and Elastic servers.
4.17
snapsmrc515
-
Stable
Added the Derive schema from the sample size menu option to the JSON Formatter Snap, whereby you select the sampling size of the schema from the data source.
Added the capability to select either document (previously supported) or binary data (new) for your input and output views to the Mapper Snap.
Added the Snap Execution field to all Standard-mode Snaps. In some Snaps, this field replaces the existing Execute during the preview check box.
4.16 Patch
transform7093
-
Latest
Fixed an issue with the XSLT Snap failure by enhancing the Saxon version.
4.16 Patch
transform6962
-
Latest
Added a new property, Escape special characters, to the XML Generator Snap that enables you to escape XML special characters in template variable values.
Added a new property, Header size error policy, to the CSV Formatter and CSV Parser Snaps. The property enables you to handle header size errors.
4.16 Patch
transform6869
-
Latest
Fixed an issue with the XML Parser Snap wherein XSD with annotations were incorrectly interpreted.
4.16
snapsmrc508
-
Stable
Upgraded with the latest SnapLogic Platform release.
4.15 Patch
transform6736
-
Latest
Fixed an issue wherein the XML Generator Snap was unable to escape some of the special characters.
4.15 Patch
transform6680
-
Latest
Fixed an issue with the Excel Parser Snap wherein headers were not parsed properly and header columns were also maintained in an incorrect order.
4.15 Patch
transform6402
-
Latest
Fixed an issue with an object type in the Fixed Width Formatter Snap.
4.15 Patch
transform6386
-
Latest
Fixed an issue with the Fixed Width Parser Snap wherein Turkish characters caused incorrect parsing of data on Windows plex.
4.15 Patch
transform6321
-
Latest
Fixed an issue with the XML Parser Snap wherein the Snap failed to get data types from XSD.
4.15 Patch
transform6265
-
Latest
Fixed an issue with the XML Parser wherein XML validation was failing if the XSD contained xsd:include.
4.15
snapsmrc500
-
Stable
Added a new property, Binary header properties, to the Document to binary Snap that enables you to specify the properties to add to the binary document's header.
4.14 Patch
transform6098
-
Latest
Fixed an issue wherein the XML Parser Snap was not maintaining the datatype mentioned in the XSD file.
4.14 Patch
transform6080
-
Latest
Fixed an issue with the Avro Formatter Snap wherein the Snap was failing for a complex JSON input.
4.14 Patch
MULTIPLE5732
-
Latest
Fixed an issue with S3 file reads getting aborted intermittently because of incomplete consumption of input stream.
4.14 Patch
transform5684
-
Latest
Fixed the JSON Parser Snap that causes the File Reader Snap to fail to read S3 file intermittently with an AbortException error.
4.14
snapsmrc490
-
Stable
Upgraded with the latest SnapLogic Platform release.
4.13 Patch
transform5411
-
Latest
Fixed an issue in the CSV Formatter Snap where the output showed extra values that were not provided in the input.
4.13
snapsmrc486
-
Stable
Upgraded with the latest SnapLogic Platform release.
4.12 Patch
transform5005
-
Latest
Fixed an issue with the Excel Parser Snap that drops columns when the value is null at the end of the row.
4.12 Patch
transform4913
-
Latest
Fixed an issue in the Excel Formatter Snap, wherein opening an output stream prematurely causes the Box Write Snap to fail. Excel Formatter now awaits the first input document, before opening an output stream.
4.12 Patch
transform4747
-
Latest
Fixed an issue that caused the Join Snap to go out of memory.
4.12
snapsmrc480
-
Stable
Improved performance for both Aggregate and Join Snaps.
Added Select All and Deselect All buttons to the Mapper table
4.11 Patch
transform4558
-
Latest
Enforced UTF-8 character encoding for the Fixed Width Formatter Snap.
4.11 Patch
transform4343
-
Latest
Enhanced enum labels on the Binary to Document and the Document to Binary Snaps for the Encode or Decode property with DOCUMENT and NONE options.
4.11 Patch
transform4361
-
Latest
Fixed a sorting issue with the Join and Sort Snaps where the end of the file was not detected correctly.
4.11 Patch
transform4281
-
Latest
Added support on the Kryo serialization for UUID and other types to the Sort, Join and In-Memory Lookup Snaps.
4.11
snapsmrc465
-
-
Updated the JSON Formatter Snap with Binary Header and Content properties to allow the Snap to pass through binary header data.
Enhanced the In-memory Lookup Snap for Performance Optimization.
Enhanced the Sort Snap for Performance Optimization.
Updated the Excel Parser with will Insert null columns property to insert 'null' on missing columns at end.
4.10 Patch
transform4058
-
-
Addressed an issue with the Excel Parser Snap that failed with out of memory when using large input Data (eg. 191 MB).
4.10 Patch
transform3956
-
-
Conditional Snap: fixed an issue with the "Null-safe access" Snap Setting not being respected for return values.
4.10
snapsmrc414
-
-
CSV Parser Snap updated with Ignore empty stream property to support passing the empty data.
XML Formatter Snap updated with Max schema levels property to support the outbound schema XSD containing import statements.
Addressed spelling errors in messages across the Snap Pack.
4.9.0 Patch
transform3343
-
-
Join Snap - All input documents from all input views should be consumed before the end of Snap execution.
4.9.0 Patch
transform3281
-
-
Made all four output views in Diff snap as mandatory.
4.9.0 Patch
transform3264
-
-
Made all four output views in Diff snap as mandatory.
4.9.0 Patch
transform3220
-
-
CSV Parser Snap - A new Snap property Ignore empty data with true default is added
4.9.0 Patch
transform3019
-
-
Addressed an issue with the transform2989 build.
4.9.0 Patch
transform2989
-
-
Addressed an issue with Excel Parser not displaying the most recent cached value for vlookups containing missing external references.
4.9.0
-
-
Introduced Encrypt Field and Decrypt Field Snaps.
4.8.0 Patch
transform2956
-
-
[CSVParser] Fixed an issue where an empty Quote Character config field was defaulting to the unicode quote character U+0000 (null). This caused issues if the input CSV had U+0000 characters in it.
4.8.0 Patch
transform2848
-
-
Addressed an issue with Excel Multi sheet Formatter creating unreadable data on the output view when there is no input document.
Addressed an issue with CSV Formatter Snap failing on empty input data.
Addressed an issue with an upstream Script Snap throwing a NoClassDefFoundError in the Sort Snap.
4.8.0 Patch
transform2768
-
-
Addressed an issue with CSV Parser causing a spike in CPU usage.
4.8.0 Patch
transform2736
-
-
Addressed an issue with Excel Formatter dropping the first record when Ignore empty stream is selected.
4.8.0
-
-
Updated the CSV Formatter Snap with Newline property. This lets you select newline characters as a line break.
CSV Formatter Snap: Snap-aware error handling policy enabled for Spark mode. This ensures the error handling specified on the Snap is used.
Mapper: Snap-aware error handling policy enabled for Spark mode. This ensures the error handling specified on the Snap is used.
4.7.0 Patch
transform2549
-
-
Addressed an issue with Excel Formatter altering decimal numbers to text.
4.7.0 Patch
transform2344
-
-
Resolved an issue with validation of pipelines taking more time than executing a pipeline when a large amount of data is used.
4.7.0 Patch
transform2335
-
-
Resolved an issue with XML Parser failing with error: 'Maximum attribute size (524288) exceeded'.
4.7.0 Patch
transform2206
-
-
Resolved an issue with JSON Generator failing with an "Invalid UTF-8 middle byte 0x70" error on Windows.
4.7.0
-
-
Updated Sort Snap with the property Maximum memory %. (Also released as a patch to 4.6.0)
Updated JSON Formatter Snap with the JSON lines field, an option that outputs each document fully in a single line followed by a newline.
Updated the JSON Splitter Snap with Json Path property.
Updated the Excel Parser Snap with the new field, Header row.
4.6.0 Patch
transform2018
Resolved an issue where Excel Parser did not reliably set header row when "contains headers" is checked
4.6.0 Patch
transform1905
Resolved an issue in Sort Snap where buffer size should not be fixed for optimal performance
4.6.0 Patch
transform1901
In-Memory Lookup Snap: Resolved an issue where the internal lookup table size was fixed at 1GB.
New property "Maximum memory %" allows users to use larger memory for optimal performance.
4.6.0 Patch
transform1871
Resolved a performance issue in Excel Multi Sheet Formatter.
4.6.0
The following Snaps now support error view in Spark mode: Aggregate, CSV Parser, JSON Parser, Join, Unique.
Added an option to enable output readability. The newly added option is Pretty-print.
Resolved an issue in Excel Formatter Snap that formatted decimal numbers as text in the output XLS file.
Resolved an issue in XML Generator Snap that expired the internal cache after 50 minutes.
Resolved an issue in Join Snap that caused unexpected failures while performing join or duplicated column values.
Resolved an issue in Sort Snap that caused unexpected results when provided with multiple sort paths.
You can now expand/collapse all nodes of a schema tree by holding the Shift key while clicking on the plus (+) sign.
Schemas with less than 1000 entries will now auto-expand when searching/filtering.
4.5.1
XML Formatter is enhanced to transform an XML output to canonical XML. For more information, see XML Formatter.
Join Snap is updated to support a new join type, Merge. For more information, see Join.
Fixed an error in XML Parser Snap that caused the Snap to fail for a valid specification, a hierarchy with an XPath expression.
Fixed an error in CSV Parser Snap that causes the skip lines option to not take effect in Spark mode.
Fixed an error in Join Snap that caused unintended values in the output document if one of the inputs has zero documents.
Fixed an error that throws incorrect resolution for a failure when a Join Snap has unconnected input views.
Fixed an error in Sort Snap that occurred because the upstream Snap was producing Long instead of Big integer.
Fixed an error in Sort Snap to ensure appropriate error handling.
Fixed an error in Join Snap, in Ultra mode, that that caused execution failure due to lineage information.
The version of the Join Snap deprecated in 4.4.1 is no longer available in the catalog.
CSV Parser Snap is updated to ensure appropriate parsing of input data. The Snaps that worked prior to 4.4.1 were failing in the 4.4.2 version. This has been rectified.
Resolved an issue with the Mapper Snap that occurred while evaluating an expression and reporting its error.
Resolved an issue with CSV Formatter adding extra data to output when used in Spark mode.
Resolved an issue with CSV Parser Snap that occurred when the second input view did not contain a header.
Resolved an issue with the Mapper Snap that occurred while evaluating an expression and reporting its error.
4.4.1
NEW! Excel Multi Sheet Formatter
NEW! In-Memory Lookup
Deprecated: The Join Snap has been deprecated and is labeled as such. Existing pipelines using this Join Snap (which is now deprecated) will continue to function as-is without any issues, including pipeline execution or while pipeline deployment across orgs. This Snap will continue to be supported for two Platform Level (x.x) Sprints, which is approximately six months. After that point, no bug fixes will be applied to the Snap. It is recommended to move to use the new Snaps (Join and In-Memory Lookup), which together have significant performance and efficiency benefits.
Name change: The Multi-Join Snap has been renamed to Join.
Aggregate: Resolved an issue with Sum and Avg Functions not returning correct output in Spark mode.
CSV Parser: A second optional input view was enabled to add the ability to associate an external schema file.
CSV Formatter: A new property, Quote mode, specifies how the quote character should be used in formatting the CSV data.
JSON Formatter: Resolved an issue with the Ignore Empty Streams option not working.
JSON Parser: Resolved an issue with error handling when an empty file is passed in an Ultra task.
Resolved an issue with XSLT Snap incorrectly completing successfully when a truncated XML document was passed.
ZipFile Read:
Resolved an issue with Content-length, content-location showing differently for different protocols.
Resolved an issue with spaces in file and folder names displaying as "%20".
4.4
NEW! Pivot Snap
Resolved an issue with JSON Splitter modifying documents that were already sent out.
Spark support added to the Aggregate, CSV Formatter, CSV Parser, Mapper, Sort, and Unique Snaps.
4.3.2
NEW! Group By Fields and Group By N Snaps added.
Behavior change: CSV Formatter: Expression support added to Delimiter and Quote Character properties. You will need to toggle on the expression button to use an expression in this field.
Behavior change: CSV Parser: Expression support added to Delimiter, Quote Character, and Escape Character properties. You will need to toggle on the expression button to use an expression in this field.
Resolved an issue with Encrypt and Compress showing 352 bytes of data when CSV Formatter has Ignore empty stream enabled.
Resolved an issue with Sequence Snap failing if trying to read parameters from upstream.
Resolved an issue with Sort Snap not failing with warning/error when incorrect (non-existent) field is referenced in the Sort path.
Resolved an issue with CSV Formatter failing with error Input length = 1.
(Data) removed from the Mapper Snap name.
Resolved an issue with Excel Parser Snap ignoring a column if it contained null values when selecting the Contains headers option.
Resolved an issue with Excel formatter truncating leading zero in string type.
Resolved an issue with Binary to Document Snap not routing the Content into the error view.
The Multi Join Snap has been pulled from the Snap catalog when in SnapReduce mode as it is not yet supported.
4.3.1
Addressed the following defects:
Defect: XML Generator failing with null pointer exception when simultaneous triggered task are executed
Defect: JSON Formatter Snap - fails to close JSON binary stream with closing bracket ']' when user stop the pipeline
4.3.0
Excel Parser now has an Evaluate formulas option. Select this option if the cell formulas are to be evaluated and results displayed instead of raw formulas.
Multi Join Snap
Enhanced to make the Left and Right path schema-aware.
Resolved an issue when attempting a join where one or both inputs are empty.
4.2.2
NEW! Multi Join Snap. This streaming supports joins of two or more sorted data streams.
Sequence Snap now supports pass through.
Resolved an issue where the Excel Parser Snap always returned the header from the first sheet for all sheets if the Excel file format was the older .xls format. Additionally, Improved the error message when the sheet given does not exists.
Sort Snap: Null greater option added to let you indicate if null values should be treated as greater than non-null values when sorted.
Resolved an issue with the Aggregate Snap failing with a null pointer exception.
August 7, 2015 (2015.25/4.2.1)
Resolved an issue in Excel Parser where Headers were not displayed properly if a few columns were blank.
Resolved a null pointer exception in the Aggregate Snap. The resolution included the addition of a new field, Sorted stream, where you designate whether or not the incoming date is sorted, as presorted data will allow the Snap to run more efficiently. The default value is Ascending for newly placed Aggregate Snaps; existing Aggregate Snaps will default to Unsorted for compatibility with previous functionality.
NEW! Transcoder Snap. Resolves an issue where preview of Snaps was not able to handle special characters.
Resolved an issue with XML Formatter including "Metadata" in the output.
June 27, 2015 (2015.22)
Sort Snap: performance improvements for sorting large amounts of records.
XML Formatter:
resolved an error where documents could not be converted to XML since the last Snap update.
resolved an exception found within this Snap.
JSON Splitter: resolved an issue with the Snap not honoring the Null-safe access option
Excel Parser: Headers were not displaying properly if a few columns are blank.
June 6, 2015 (2015.20)
CSV Parser: You can now select the character set in which your incoming CSV data is encoded.
CSV Formatter: You can now select the character set in which encode your CSV data. You can also select to writhe the BOM (ByteOrderMark) for the character set selected.
NEW!: Avro Parser and Formatter
Excel Parser Snap: resolved failure due to file size
XML Formatter:
resolved "Cannot read attribute: element has children or text" error
Additional property, Strict XSD Output was added to extract the root element name and the wrapper name from the XSD file.
May 2, 2015
Excel Parser: exception resolved
Join: bug fixes for certain datasets in excess of 1million rows
JSON Generator: enhanced error handling
Mapper (Data): bug fixes
Sequence Snap: enhanced error handling
Sort:bug fixes for certain datasets in excess of 1m rows
XML Parser: enhancements supporting empty documents
March 2015
CSV Formatter: Exception resolved when the quote character and delimiter were the same.
XML Formatter: The datetime output now outputs as UTC date/time
XML Parser: Examples added to the documentation.
January 2015
Binary to Document Snap: The optional property Ignore empty stream was added.
CSV Formatter: Performance enhancements
CSV Parser:
Quote character is no longer a required field.
Optional Header size error policy field added. This setting lets you decide how to handle the error. In the newly provided csv, the last record is too big. Existing pipelines with this Snap will default to Both as this was the previous behavior.
Excel Parser: Now writes bad records to the document error view if configured.
XML Parser
The splitting of an XML document functionality has been improved. You can provide the splitter expression (a path to the element you want to split an XML on) in the XML Parser Snap and it will split the document (regardless of the size of the original XML).
Performance improvements.
December 20, 2014
Join: a new version of the Join Snap has been created. The existing version will continue to work, but will be marked as Deprecated. Any future enhancements will be in the newer Join. The new Join will prefix top level attributes from the right with right_ and top level attributes from the left with left_.
CSV Parser & Formatter have been enhanced to utilize Unicode for delimiters.
Fixed Width Formatter: Now supports Null-safe access
Updates to XML Parser and XML Formatter
November 2014
Aggregate now provides 2 new functions: concat and unique_concat
October 18, 2014
XML Generator
XSD support added
Pass-through support added by default. The Snap will pass-through the input data if an input view is provided. This is not configurable.
Optional Ignore empty stream setting added to XML Formatter and Excel Formatter
Addressed an issue where Conditional Snap was unable to process null Return Value
Fall 2014
Mapper Snap
The Data Snap has been replaced by the Mapper Snap.
The functionality of the Mapper table was enhanced with the following:
Mapper enhanced to support Structure-mapping.
Performance enhancements now load the Mapper table sooner.
You can now map items by dragging an item from one schema to the other.
The Mapping root option now lets you process an array easier by setting this option to the top node of that array.
Mapper field highlight visibly indicates the mapping between input and output schemas.
Data preview of input and output data.
Moved XML & FixedWidth Snaps to Transform Snap Pack
August 2014
Fixed Width Parser enhanced to be able to skip any row based on a pattern.
CSV Parser now validates that the header field matches the declaration if Contains header is selected.
July/Summer 2014
Binary to Document (Beta), Document to Binary (Beta)
June 30, 2014
Addressed the following issues:
JSON Generator not streaming.
CSV Parser with empty skip lines field leads to null pointer exception during validation
CSV Formatter does not parse headers with space
XML Formatter: Snap fails converting document into XML
May 2014
NEW! CSV Generator Snap
NEW! Sequence Snap
NEW! Constant Snap
Conditional Snap updated with Null-safe access.
The Data Snap no longer needs an input. With no input view specified, it generates a downstream flow of one row.
April 2014
Aggregate Snap updated to handle aggregating Strings, Date, Time, and DateTime.
Excel Parser Snap enhanced to determine column names in a spreadsheet.
March 2014
NEW! Unique
JSON Splitter Snap was enhanced with an Include parent option, which includes the hierarchy of the list specified by the JSON path by adding it to each document.
Snaps like JSON Parser that have a JSON path expression now support pipeline parameter substitution in that expression.
Excel Parser Snap property labels updated for clarity. "Skip Lines" labels are replaced with Start Row and End Row.
January 2014
NEW! Microsoft Excel Formatter & Parser
UTF-16LE & UTF-16BE unicode support was added to the JSON Formatter & Parser and the CSV Formatter & Parser Snaps
December 2013
NEW! Fixed Width Formatter and Parser
CSV Parser now adds "field00x" to column names for tables with empty column names when Contains headers are false.
November 2013
NEW! Conditional
NEW! Diff
August 2013
NEW! Aggregate: The Aggregate Snap applies aggregate functions on input data with Group By support.
NEW! JSON Generator: Generates JSON as a document for the next Snap in the pipeline.
Join: The Join Snap was enhanced to support Outer joins.
July 2013
JSON Splitter: The JSON Splitter Snap splits a list of values into separate documents.
): Indicates a list that is dynamically populated based on the configuration.
): Indicates whether the value is an expression (if enabled) or a static value (if disabled). Learn more about Using Expressions in SnapLogic.
): Indicates that you can add fields in the field set.
): Indicates that you can remove fields from the field set.