Catalog Insert
- Kalpana Malladi
- Mohammed Iqbal
- John Brinckwirth
On this Page
Overview
Known Issue
In Snaplex version 4.38, pipelines using the Catalog Insert Snap no longer populate the Data Catalog tables in Manager with metadata.
Workaround: Do not use Snaplex version 4.38 to run pipelines using the Catalog Insert Snap.
The Catalog Insert Snap enables you to enrich your metadata catalog by inserting metadata into the catalog tables.
Expected Input and Output
- Expected Input: A document containing metadata to be written into the metadata catalog. This document should have a field named schema with the document schema.
- Expected Output: A document containing status messages on the result of the insert operation.
- Expected Upstream Snaps: Required. Any Snap that offers document data. Examples: Parquet Writer and Mapper.
- Expected Downstream Snaps: Any Snap that accepts document data in its input view. Examples: Mapper and File Writer.
Prerequisites
Write access to the SnapLogic data catalog.
Configuring Accounts
Accounts are not used with this Snap.
Configuring Views
Input | This Snap has exactly one document input view. |
|---|---|
| Output | This Snap has at most one document output view. |
| Error | This Snap has at most one document error view. |
Support for Ultra Pipelines
- Does not work in Ultra Pipelines.
Snap Settings
| Label | Required. The name for the Snap. Modify this to be more specific, especially if there are more than one of the same Snap in the pipeline. |
|---|---|
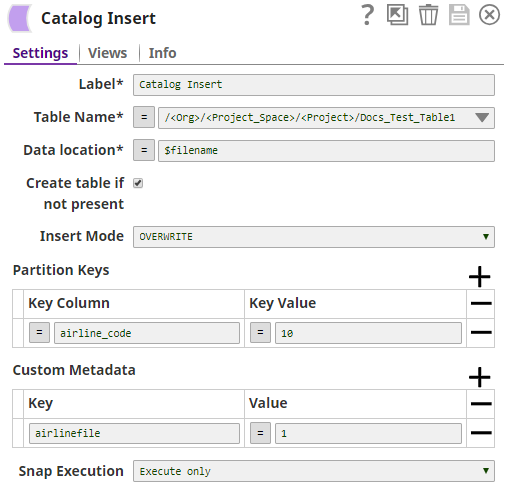
| Table Name | Required. The location and name of the table that you want to update. You can either enter this information manually or you can select the table from the suggestible drop-down. Example: /<Org>/<Project_Space>/<Project>/<Table_Name> Default value: None |
| Data location | Required. The location of the file whose metadata you want to insert. This is typically a location in AWS S3, and can either be specified as a URL string, a pipeline parameter, or an upstream parameter. Example: parquetesting1.parquet Default value: None |
| Create table if not present | Enables you to specify whether the table should be automatically created if not already present. Select this check box to create the table. Selecting this option creates a table with all columns of type STRING. Default value: Not selected |
| Insert Mode | Required. Available insert modes when loading data into table.
|
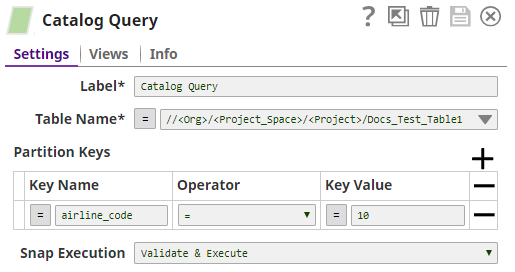
| Partition Keys | The partition keys for which you want to insert the metadata. You list these out by specifying Key Column and Key Value combinations to identify the precise row and column from which to create a partition Default value: None |
| Key Column | The name of the column that contains the value that you want to use to specify the partition. Example: airline_code Default value: None |
| Key Value | The value in the column listed in the Key Column field that you want to use to specify the partition. Example: 10 Default value: None |
| Custom Metadata | Enables you to specify the custom metadata values in Key and Value pairs. Default value: None. |
| Key | Enables you to add a key that you want to associate with the new metadata you want to add. Example: airline_region Default value: None |
| Value | Enables you to add the value that you want to associate with the key as part of the new metadata that you want to upload. Example: APAC Default value: None. |
Snap execution | Select one of the three modes in which the Snap executes. Available options are:
|
Example
Inserting and Querying Custom Metadata from the Flight Metadata Table
The Pipeline in this zipped example, MetadataCatalog_Insert_Read_Example.zip, demonstrates how you can:
- Use the Catalog Insert Snap to update metadata tables.
- Use the Catalog Query Snap to read the updated metadata information.
In this example:
- We import a file containing the metadata.
- We create a parquet file using the data in the imported file
- We insert metadata that meets specific requirements into a partition in the target table.
- We read the newly-inserted metadata using the Catalog Query Snap.
The Pipeline is designed as follows:
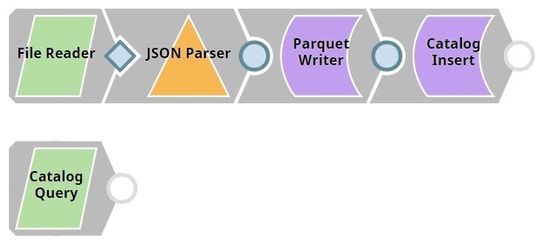
The File Reader Snap read flight statistics and the JSON Parser Snap parses the data into a JSON file.
The Parquet Writer Snap creates a Parquet file with the data of the JSON file, in an S3 database.
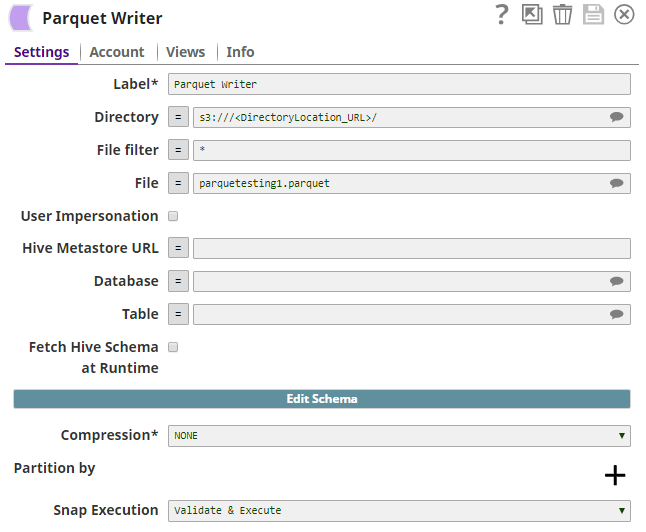
The output of the Parquet Writer Snap includes the schema of the file. This is the metadata that must be included into the catalog.
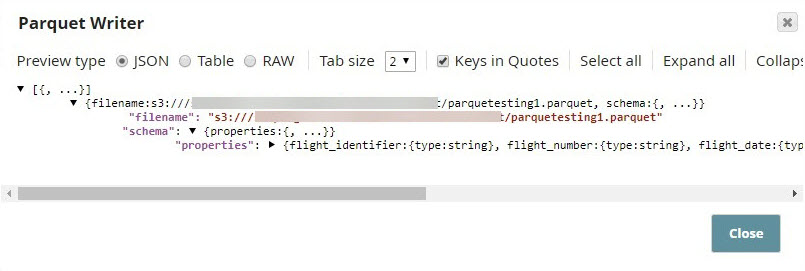
The Catalog Insert Snap picks up the schema from the Parquet file and associates it with a specific partition in the target table. It also adds a custom property to the partition.
Once the Snap completes execution, the table is inserted into the metadata catalog and you can view the table in the SnapLogic Manager.
To view the table, navigate to the Project where you have created the Pipeline, click the Table tab, and then click the new table created after executing the Pipeline. This displays the table. Click Show schema to view the metadata.
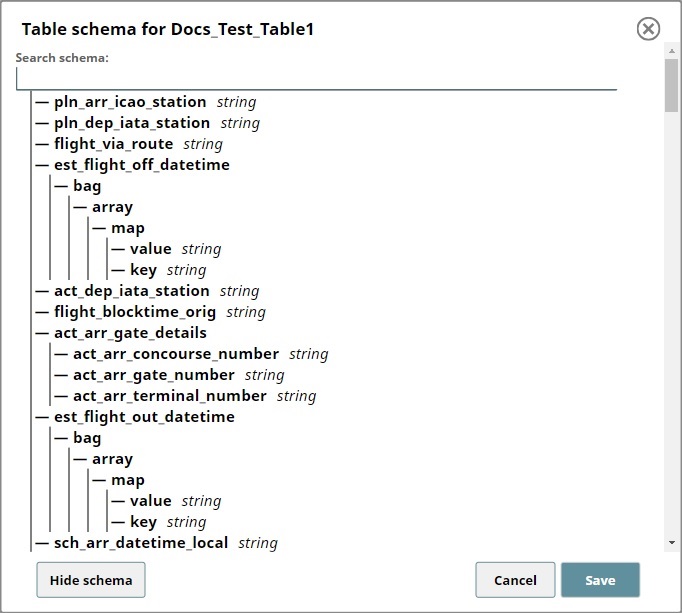
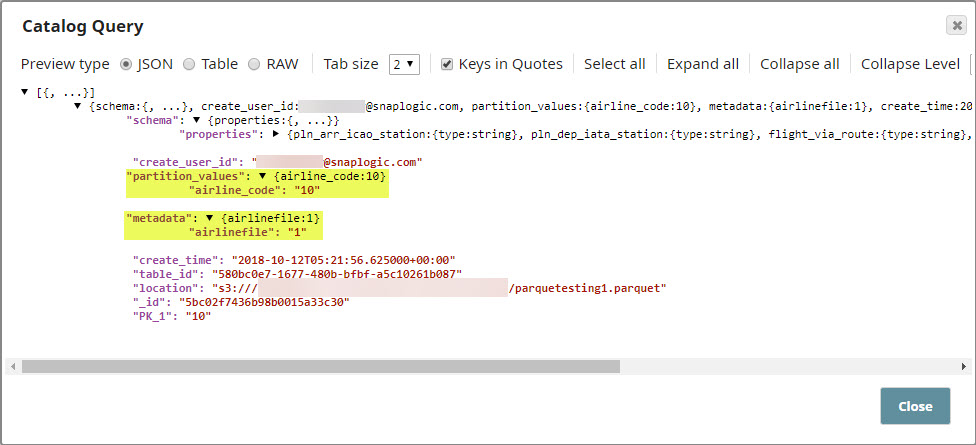
The Schema view does not display the custom metadata that you inserted into the partition. Use the Catalog Query Snap to view all the updates made by the Catalog Insert Snap.
Download this ZIP file.
Working with the Sample ZIP File
This ZIP file contains two files:
- Metadata_Catalog_Insert_Read.slp
- AllDataTypes.json
To import this Pipeline:
- Download the ZIP file and extract its contents into a local directory.
- Import the Metadata_Catalog_Insert_Read.SLP Pipeline into a SnapLogic project.
- Open the Pipeline and click the File Reader Snap.
- In the File Reader Settings popup, use the
 button to import and read the AllDataTypes.json file.
button to import and read the AllDataTypes.json file. - Your Pipeline and test data are now ready. Review the other steps listed out in this example before validating or executing this Pipeline.
Downloads
Important steps to successfully reuse Pipelines
- Download and import the pipeline into the SnapLogic application.
- Configure Snap accounts as applicable.
- Provide pipeline parameters as applicable.
Snap Pack History
Have feedback? Email documentation@snaplogic.com | Ask a question in the SnapLogic Community
© 2017-2025 SnapLogic, Inc.