Data Catalog Services
- John Brinckwirth
- Gouri Bhagchandani (Deactivated)
- Ankur Parekh
In this article
Overview
SnapLogic’s Data Catalog Service allows you to save, manage, and retrieve metadata about data stored in external file systems, such as S3. With this feature, you can query the actual source data, even without knowing its location.
The Data Catalog Service helps you do the following:
- Refactor your existing data as your business requirements change. You can reduce redundant data, migrate data, or restructure data to better support your current business needs.
- Use the data to make better business decisions. You can find patterns in the relationships between specific assets to gain insight into how your business is performing.
Ensure the viability and utility of data over time. You can determine how you can optimize the way you store and organize your data to keep it useful and relevant. For example, a review of your metadata can help you identify parts of your data that can be merged or deleted as appropriate.
The metadata tracked by Data Catalog Service includes the location of the source, the schema of the data, the format of each file, and any custom metadata tags associated with the data. This information is copied from Pipelines into Table Assets. When data is added to a data lake, the data is associated with its source's metadata, thereby simplifying the management and tracking of the raw data source files.
The Data Catalog Service provides controls to manage the Table Assets containing the metadata. Data integrators can use the Data Catalog Service with the Catalog Insert, Catalog Query, and Catalog Delete Snaps from the Data Catalog Snap Pack to interconnect, analyze, and enhance enterprise metadata. With these Snaps, you can build Pipelines that capture, ingest, conform, and refine large metadata within a single UI and then view the data in a table or in columns.
Known Issue
In Snaplex version 4.38, pipelines using the Catalog Insert Snap no longer populate the Data Catalog tables in Manager with metadata.
Workaround: Do not use Snaplex version 4.38 to run pipelines using the Catalog Insert Snap.
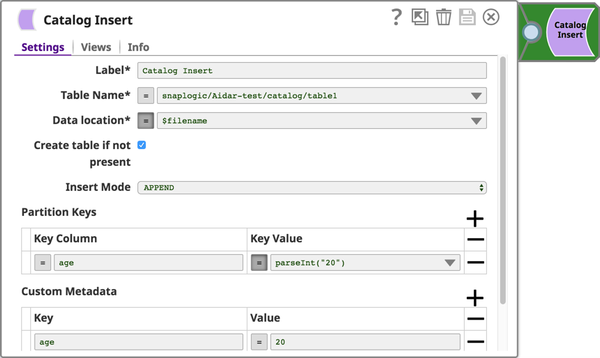
Tables can be partitioned with one or more partitioning keys.
Enhance the metadata by adding information to the table's description or to the table partition's comments. For example, add the project name in the table's description, or add the range of employee IDs in a comment for a table partition that contains the metadata for those employee records.
Data Catalog Snaps
Use the following Snaps to manage your metadata in Pipelines:
Catalog Insert: Create a Table Asset, if new, and insert metadata information into Table assets. You can also use this Snap to iteratively enrich your metadata catalog with additional details, ensuring that you have all the information you need to derive actionable insights from your data.
Catalog Query: Retrieve information from Table Assets that you either want to reuse or update and insert back into the catalog. For example, you could use a combination of the Catalog Query and Catalog Insert Snaps to retrieve metadata from one set of tables and create or enrich other tables in your catalog.
Catalog Delete: Delete tables or partitions from you catalog. For example, you might create new partitions in a Table and therefore need to delete older/previous partitions to avoid duplicating metadata.
Support and Limitations
- To read the table, the document must have a field called schema with the document schema.
- To search the Data Catalog, use the Catalog Query Snap.
Pipeline Example

This Pipeline queries a partition in the table, deletes the partition, generates a JSON document, and writes it to S3, inserting the metadata into the Table Asset in Manager.
Catalog Query Snap: Queries the Table to find the target partition.
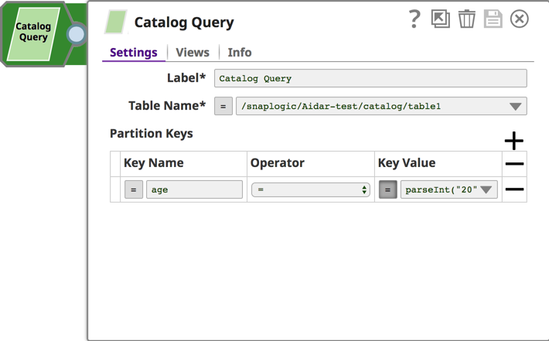
Catalog Delete Snap: Deletes the Table partition.
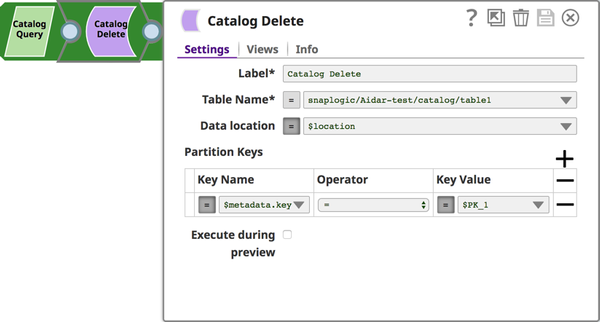
JSON Generator Snap: Generates a JSON document.
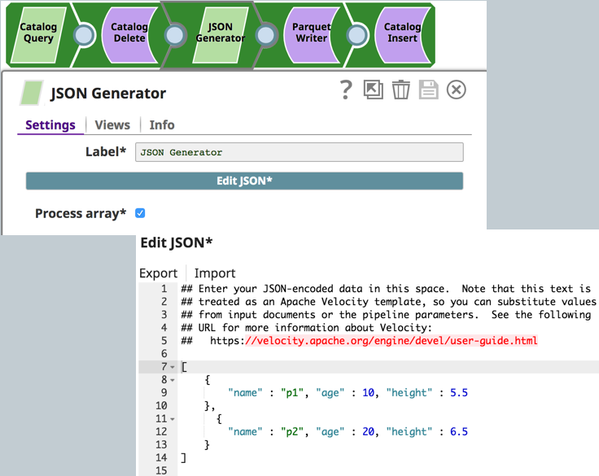
Parquet Writer Snap: Writes the JSON document to an S3 bucket.
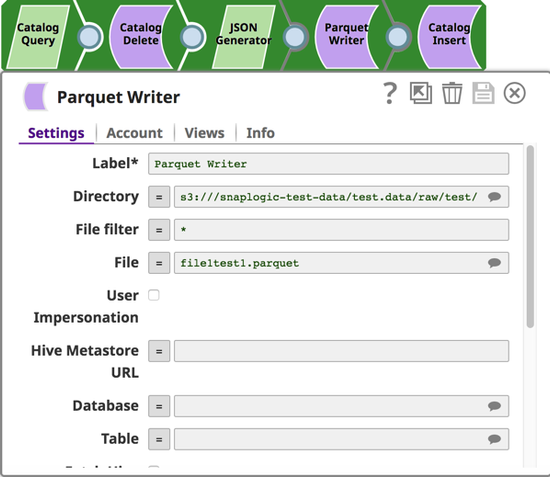
Catalog Insert Snap: Writes the metadata into the Table.
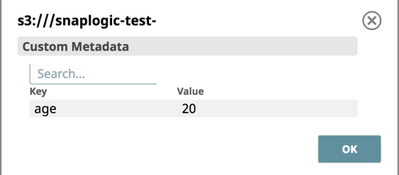
Viewing the Table in SnapLogic Manager:
a) You can check the result of the Pipeline by viewing the metadata for that Table.
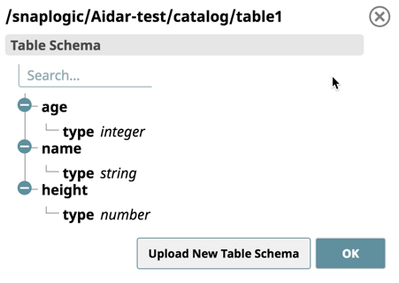
b) You can also view the Table schema for the partition, or upload a new schema for that Table, which contains all the fields in your source Table.
Download
Important steps to successfully reuse Pipelines
Have feedback? Email documentation@snaplogic.com | Ask a question in the SnapLogic Community
© 2017-2025 SnapLogic, Inc.