In this article
Overview
SnapLogic’s ELT Snap Pack is a full pushdown optimization (FPDO) solution that extracts, loads, and transform (ELT) data in the target database by building ELT Pipelines that parse SQL queries. As such, the ELT Pipeline generates and executes SQL on the target database. ELT Snaps help you to make data available to the enterprise in quick time; eliminating delays in transforming data for your specific purpose.
- Extract data from the source system (SaaS application)
- Load it into your Data Warehouse in its raw format
- Transform the data using the power of the cloud
Automating Data Integration with ELT
Articles in this section
Features
- Ease of Use
- SQL passed between Snaps; execution on CDW (cloud data warehouse)
- Visually build SQL Pipelines
- Selectively Preview Data
- Suggest capability
- Extensive transformation capabilities
- Load data using merge into
- Enhanced Connectivity
- Independent Snap Pack
- Accounts specific to each target database.
- Security
- Prevent SQL Injection
- Write transformed data to target databases hosted in the following cloud locations:
- AWS (For Snowflake, Redshift, and Databricks Lakehouse Platform (DLP))
- Microsoft Azure (For Snowflake, Azure Synapse, and Databricks Lakehouse Platform (DLP))
- Google Cloud Platform (For Snowflake and BigQuery)
You can also execute an ELT Pipeline from a standard-mode Pipeline by utilizing the Pipeline Execute Snap.
ELT Source-Target-Hosting Support Matrix
(Source) Data Storage | Cloud Data Warehouse (Target) | (Target) Cloud Host | ||||||
|---|---|---|---|---|---|---|---|---|
AWS Simple Storage Service (S3) | Microsoft Azure | Azure External Location | Google Cloud Storage | Amazon AWS | Microsoft Azure | Google Cloud Platform (GCP) | ||
| Azure | Blob Storage | ADLS Gen2 | ||||||
| ✔ | ✔ | ✖ | ✖ | ✔ | Snowflake | ✔ | ✔ | ✔ |
| ✔ | ✖ | ✖ | ✖ | ✖ | Redshift | ✔ | ✖ | ✖ |
| ✖ | ✖ | ✔ * | ✔ * | ✖ | Azure Synapse | ✖ | ✔ | ✖ |
| ✔ | ✖ | ✔ | ✔ | ✖ | Databricks Lakehouse Platform (DLP) | ✔ | ✔ | ✖ |
| ✖ | ✖ | ✖ | ✖ | ✔ | Google BigQuery | ✖ | ✖ | ✔ |
*ELT Snap Pack supports Azure Blob Storage and ADLS Gen2 as the external (source) locations for loading and transforming data into Azure Synapse.
See ELT Database Account for more details.
Supported JDBC JAR Versions
You can configure your ELT Database Account to automatically use an appropriate JDBC JAR file for connecting to your target CDW and performing the load and transform operations.
| Supported CDW | Certified JDBC JAR File |
|---|---|
| Azure Synapse | mssql-jdbc-8.4.1.jre8.jar |
| BigQuery | SimbaJDBCDriverforGoogleBigQuery42_1.2.19.1023.zip |
| Databricks Lakehouse Platform (DLP) | SimbaSparkJDBC42-2.6.17.1021.jar |
| Redshift | redshift-jdbc42-1.2.43.1067.jar |
| Snowflake | snowflake-jdbc-3.12.16.jar |
Using Alternate JDBC JAR File Versions
We recommend you to let the ELT Snaps use the listed JAR file versions. However, you may use a different JAR file version of your choice.
Known Issues
When your Databricks Lakehouse Platform instance uses Databricks Runtime Version 8.4 or lower, ELT operations involving large amounts of data might fail due to the smaller memory capacity of 536870912 bytes (512MB) allocated by default. This issue does not occur if you are using Databricks Runtime Version 9.0.
In case of Databricks Lakehouse Platform (DLP), when you specify a CSV file to load data from and select the Load Action as Alter Table in the ELT Load Snap, the Snap fails with the error
Database encountered an error during Bulk Load process.When you configure an ELT Merge Into Snap to perform an Update or Delete operation or an ELT Execute Snap with a MERGE INTO statement that performs Update or Delete operation on a Databricks Lakehouse Platform cluster, it may return an error if multiple source rows attempt to update or delete the same target row. To prevent such errors, you need to preprocess the source table to have only unique rows.
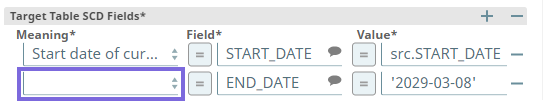
While using the SQL Expressions and Functions Supported for ELT to define the field values in ELT Snaps and accounts:
DO NOT use regular JavaScript expressions (supported in the Standard-mode Snaps and not in the above list).
DO NOT prefix variable names with $ symbol.
The Help icon
that leads to the SnapLogic documentation site is disabled by default for unsaved Snaps. Save the Snap to enable the Help icon.
- The Snaps - ELT Load, ELT Merge-Into, ELT Insert-Select and ELT Select, display the Schema Name field suggestions from all databases that the Snap account user can access, instead of the database selected in the Snap account or the Snap Settings.
ELT Transform Snap displays incorrect data types (string instead of the actual data type) for column names populated in its Input schema section.
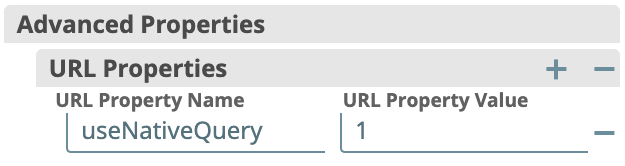
- ELT Pipelines targeting a Databricks Lakehouse Platform (DLP) instance might fail due to a very long or complex SQL query that they build. As a workaround, you can set an advanced (URL) property useNativeQuery to 1 in your ELT Database Account configuration as shown below:
- In any of the supported target databases, this Snap does not appropriately identify nor render column references beginning with an _ (underscore) inside SQL queries/statements that use the following constructs and contexts (the Snap works as expected in all other scenarios):
WHEREclause (ELT Filter Snap)WHENclauseONcondition (ELT Join, ELT Merge Into Snaps)HAVINGclauseQUALIFYclause- Insert expressions (column names and values in ELT Insert Select, ELT Load, and ELT Merge Into Snaps)
- Update expressions list (column names and values in ELT Merge Into Snap)
- Secondary
ANDcondition Inside SQL query editor (ELT Select and ELT Execute Snaps)
Workaround
As a workaround while using these SQL query constructs, you can:
- Precede this Snap with an ELT Transform Snap to re-map the '_' column references to suitable column names (that do not begin with an _ ) and reference the new column names in the next Snap, as needed.
- In case of Databricks Lakehouse Platform where CSV files do not have a header (column names), a simple query like
SELECT * FROM CSV.`/mnt/csv1.csv`returns default names such as _c0, _c1, _c2 for the columns which this Snap cannot interpret. To avoid this scenario, you can:- Write the data in the CSV file to a DLP table beforehand, as in:
CREATE TABLE csvdatatable (a1 int, b1 int,…) USING CSV `/mnt/csv1.csv`where a1, b1, and so on are the new column names. - Then, read the data from this new table (with column names a1, b1, and so on) using a simple SELECT statement.
- Write the data in the CSV file to a DLP table beforehand, as in:
- In case of Databricks Lakehouse Platform, all ELT Snaps' preview data (during validation) contains a value with precision higher than that of the actual floating point value (float data type) stored in the Delta. For example, 24.123404659344 instead of 24.1234. However, the Snap reflects the exact values during Pipeline executions.
Snap Pack History
Release | Snap Pack Version | Date | Type | Updates |
|---|---|---|---|---|
| 4.27 | main12833 | Stable |
| |
| 4.26-Patch | 426patches12534 | Latest |
| |
| 4.26-Patch | 426patches12021 | Latest |
| |
| 4.26-Patch | 426patches11646 | Latest |
| |
| 4.26-Patch | 426patches11323 | Latest |
| |
| 4.26-Patch | 426patches11262 | Latest |
| |
| 4.26 | main11181 | Stable |
| |
| 4.25-Patch | 425patches10017 | Latest |
| |
| 4.25-Patch | 425patches9725 | Latest |
| |
| 4.25 | main9554 | Stable |
| |
| 4.24-Patch | 424patches8793 | Latest |
No changes are needed to your existing Pipelines.
Behavior Change The behavior of ELT Load Snap for Load Action during Pipeline validation across the supported databases is as follows: Append rows to existing table: Does not append the data from the source files into the target table. Overwrite existing table: Does not overwrite the data. Drop and Create table: Does not drop the target table even if it exists, but the Snap creates a new target table if a table does not exist. Alter table: Does not modify the schema of the target table. | |
| 4.24 | main8556 | Stable |
Updates the Snap Pack with the following features:
| |
| 4.23 | main7430 | Stable | Introduces the following Snaps:
| |
4.22 | main6403 | Stable | Introduces the ELT Snap Pack that provides you with the Extract, Load, and Transform (ELT) capabilities. Use the following Snaps to build SQL queries that are executed in the Snowflake database:
|