Important
Per the SnapLogic Release Process, all remaining Snaplex instances across Orgs are auto-upgraded to the recommended version at 9 p.m. PT on Thursday, . Orgs migrated to the current GA version prior to the auto-upgrade are not impacted.
The Snaplex upgrade process also upgrades the Java version to the latest version. After the upgrade, the Java version of your Cloudplex nodes might not be the same as your FeedMaster nodes. However, this does not impact the operations of your SnapLogic instance. We will be fixing this issue in a subsequent release.To use the new SnapLogic features and Snaps in the current GA release, ensure that your Snaplex nodes are upgraded to the recommended version.
This release includes stable versions of the monthly releases and patches deployed to SnapLogic after the current GA release, as listed in the Dot Releases sections of the corresponding Release Notes.
4.30 UAT Delta
SnapLogic Studio (Preview)
Enhancements
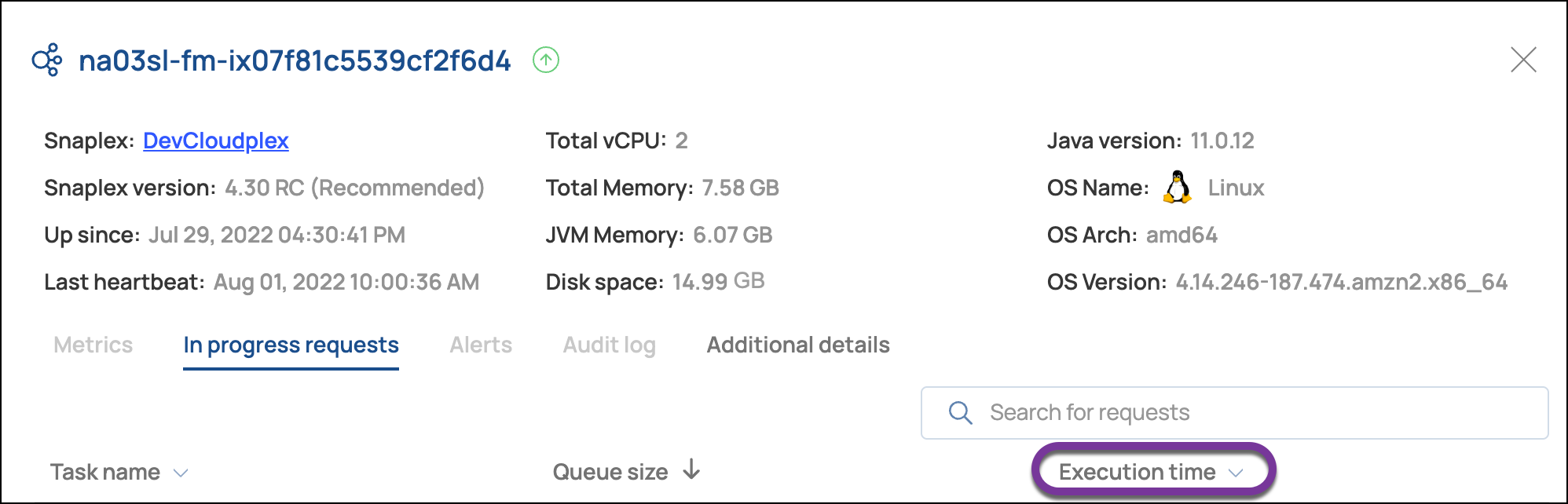
Execution Time for Requests
FeedMaster node details include the mean execution time for the last 1000 processed requests for active Ultra Tasks:
Behavior Change
The Snaplex type label for Customer managed was changed to Self managed. From the System overview you can click a Snaplex to view its details, as shown below:

Patterns Catalog
The following Patterns were added to the Studio Pattern Catalog:
Convert Salesforce Lead to Account, Contact, and Opportunity (Optional)
Create Box Folders for ServiceNow Service Requests
Create Microsoft Dynamics CRM Opportunity and Workday Invoice if Sale Occurs
Create Request Ticket in ServiceNow and Send Email
Create Request Ticket in ServiceNow When Employee Added in Workday
Creating a ServiceNow Incident From a JIRA Issue
Creating Users Within SnapLogic (Excel + REST)
Creating Users Within SnapLogic (JSON Generator + REST)
Create Users Within ServiceNow Through Workday Approval Process
CSV to Workday Tenant
Known Issues
TBD
Platform
The SnapLogic platform goes live on Cloudflare on . When launched, the SnapLogic UI will automatically redirect to the specific Cloudflare CDN addresses. This change enhances the SnapLogic platform’s response time, security, and performance. To ensure continued access to the SnapLogic UI, only customers who restrict outbound IP addresses to a predefined list of IP addresses must extend their allowlist to add all the specific IP addresses. Learn more to understand how this impacts your organization.
New Features
GitHub Enterprise Server
The SnapLogic Git Integration supports GitHub Enterprise Server (GHES). From the SnapLogic user interface, you can use GHES to track SnapLogic Projects, Files, Pipelines, Tasks, and Accounts. Similar to the Git Integration for GitHub, the GHES Integration enables you to manage your Project Assets across development, test, and production Orgs, to achieve continuous integration and development (CI/CD).
Using GHES Git Integration requires the following:
A subscription to the Git Integration for GHES.
Configuration of GHES.
Configuration of the network to support communication between SnapLogic and GHES.
Configuration of SnapLogic Org settings.
When the configuration is finished, each user logs in to SnapLogic to authorize and authenticate with their GHES account. After a Project is associated with a repository, the controls to check out, pull, add, delete, and commit are available for Project Assets. Learn more about the Git Integration and Enabling the Git Integration for GHES.
Secrets Management - HashiCorp Vault
Many organizations must comply with internal or external regulations for controlling access to sensitive information such as account credentials The SnapLogic Secrets Management feature allows organizations to use a third-party secrets manager to store credentials. Instead of entering credentials directly in SnapLogic Accounts and relying on SnapLogic to encrypt them, the Accounts contain only the information necessary to access the secrets manager. During validation and execution, Pipelines obtain the credentials directly from the secrets manager. With Secrets Management, secrets are never stored by the SnapLogic control plane or by Snaplex nodes. With the August 2022 Release, SnapLogic supports the HashiCorp Vault Cloud, Enterprise, and Open Source editions.
The high-level tasks required to use Secrets Management include the following:
Use of self-managed Snaplexes (Groundplexes) and a subscription to Secrets Management.
An administrator of the secrets manager must configure the storage for endpoint credentials, create authentication roles and access permissions, and generate secrets.
A Snaplex administrator must configure the Groundplex nodes with the token and the information required to communicate with the secrets manager.
In SnapLogic, a Pipeline designer or Org admin must configure the dynamic accounts to authenticate with the secrets manager.
Only SnapLogic dynamic accounts support Secrets Management.
Learn more about using HashiCorp Vault with SnapLogic.
Enhancements
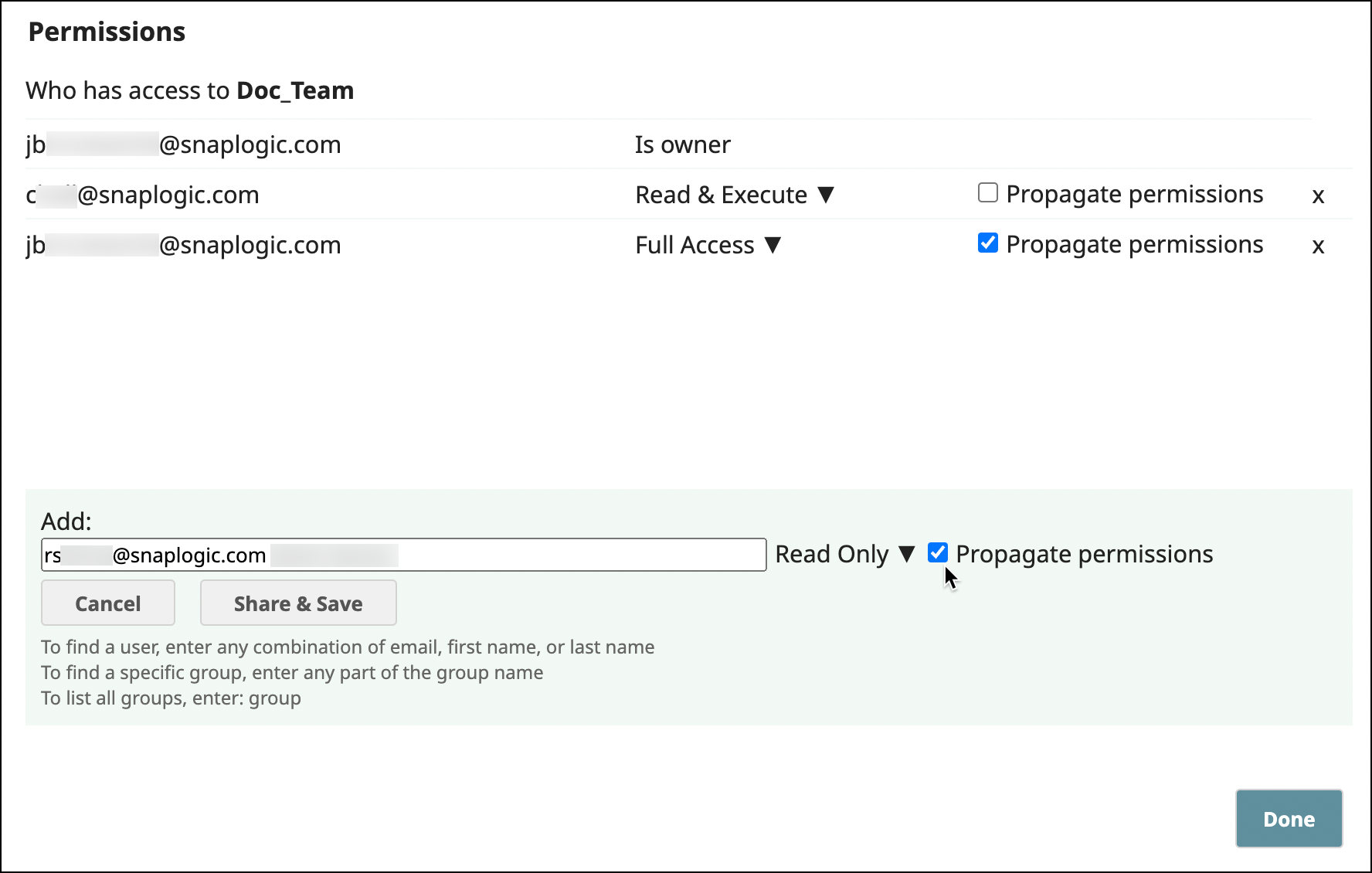
Propagate Project Space Permissions
When adding user or group permissions for a Project Space, Org admins can specify that those permissions should apply to all Projects. After you add propagated permissions, the user or group displays only in the Permissions dialog for the shared folder, not for the individual projects. Although they don’t show in the Permissions dialog for individual projects, they have the permission granted at the Project Space level.
Known Issues
TBD
API Management
New Features
New widget in the API Dashboard. In the API tab of the Dashboard, you can add the new Top Consumer by Requests widget to display metrics about consumers of your APIs. Learn more about API Insights.
Enhancements
SSO authentication for the Developer Portal. If a user logs in to SnapLogic through an SSO provider and the user navigates from the Portal Manager to the Org’s Developer Portal, the user is taken directly to the Developer Portal landing page without having to log in again. Learn more about setting up SSO in SnapLogic.
Known Issues
TBD
Snaps
Read about the Snap features and fixes deployed in the prior 4.29 Dot Releases which are part of the current GA version.
The Snap Catalog has a new category for custom Snaps developed by the SnapLogic Professional Services team. For more information on the custom Snaps and how you can subscribe them, contact your SnapLogic Customer Service Manager.
New Snap Packs and Snaps
Amazon S3: Introduces the S3 Snap Pack that allows you to manage objects in S3. This Snap Pack contains the following Snaps:
S3 Browser: Lists the attributes of S3 objects in the specified bucket matching the prefix.
S3 Copy: Sends a copy request to the S3 service to copy an S3 object from a source bucket to a target bucket.
S3 Delete: Removes an object from the specified bucket.
S3 Download: Downloads S3 objects from the S3 bucket.
S3 Upload: Uploads binary data to S3 objects.
S3 Presigned: Generates a presigned URL in the output document to access an S3 object.
S3 Account: Allows you to access resources on the S3 bucket.
Databricks: A new Snap Pack for Databricks Lakehouse Platform (Databricks or DLP) introduces the following Snaps:
Databricks - Select: Retrieves information from the target Databricks table.
Databricks - Insert: Inserts new rows of data in the target Databricks table.
Databricks - Delete: Deletes data from a target Databricks table.
Databricks - Bulk Load: Loads millions of rows of data in the target table with a single operation.
Databricks - Unload: Unloads data from a target Databricks table with a single operation.
Databricks - Merge Into: Updates millions of existing rows and inserts new rows in a target Databricks table with a single operation.
Databricks - Multi Execute: Runs multiple SQL statements on the target Databricks instance.
Google BigQuery: Introduces the following Snaps and accounts to manage datasets in Google BigQuery (GBQ):
BigQuery Dataset Create: Creates datasets in the GBQ.
BigQuery Dataset Delete: Removes datasets from the GBQ.
BigQuery Dataset List: Lists datasets from the GBQ.
BigQuery Table Delete: Removes tables from the GBQ.
BigQuery Table List: Lists tables that are read from the GBQ dataset.
Google Service Account JSON: Accesses the resources on GBQ using a JSON Key.
Google Sheet Subscribe: Enables you to subscribe to the specific spreadsheet for notifications of the changes in the Google Sheet.
Google Sheet Unsubscribe: Enables you to unsubscribe the specific spreadsheet.
Enhancements
Azure Active Directory
The Azure Active Directory Search Entries Snap includes a Display Properties field where you can specify the properties to display in the output for the user or group. To enable the Snap to return the attributes correctly in the output, you must specify the name as described in User profile attributes in Azure Active Directory B2C. Learn more about Properties for a user and Properties for a group.
Binary
The File Operation Snap now supports moving data from local node to Azure blob through the AZ Copy utility.
The Azure Storage Account includes the Request Size (MB) field to set the buffer limit before writing to Azure storage to enhance the performance.
The SSH Auth Account now supports dynamic values for the following fields that allow you to use Pipeline parameters.
Username
Private key
Key passphrase
The following Binary Snaps now partially support '?' character in the file names and file paths:
Dynamo DB
The DynamoDB Account now allows you pass the security token when making calls using the AWS Security Token field.
Eloqua
The Custom Object Metadata ID field in the Eloqua Create Snap allows you to specify an ID for creating custom object data. This conditional field appears only when you select Core object type as Custom Object Data.
Email
The Email Sender Snap supports the
file:///protocol for the Attachments field.
Google BigQuery
The Location field in the Google BigQuery Execute Snap lists all the locations in the suggestions.
Google Directory
The original payload is now passed to the error view in the Google Directory Insert Snap.
The original payload is now displayed under the original tag in the Google Directory Update Snap.
Google Sheets
The Allow empty rows checkbox in the Worksheet Reader Snap allows you to output empty rows. Select this checkbox to include empty rows between other rows that contain data.
The Worksheet Writer Snap now supports expressions for the Starting Cell Reference field. This Snap also includes a warning about potential overwriting of existing data for the Starting Cell Reference field when writing data in the same range of cells.
Hadoop
Extended the AWS S3 Dynamic Account support to ORC Reader and ORC Writer Snaps to support AWS Security Token Service (STS) using temporary credentials.
JDBC
Enhanced the Generic Database account to support dynamic values for Account properties, Advanced properties, and URL properties.
Kafka
Enhanced the Kafka Producer Snap with LZ4 and ZSTD Compression Types for compressing the messages that optimize Snap's performance.
Upgraded Kafka client libraries to Apache-Kafka Version 3.1.1 and Confluent-Kafka Version 7.1.1.
Enhanced the Kafka account, which is configured to connect to the Kafka Schema Registry, to use TLS v1.2 protocol instead of TLS that has security vulnerabilities.
MS Dynamics 365 for Sales
The Alternate Keys fieldset in the Dynamics 365 For Sales Update and Dynamics 365 For Sales Upsert Snaps now enable you to refer to entities by unique or nonunique combinations of columns.
OpenAPI
The OpenAPI Snap supports external files referenced in the OpenAPI specification field and includes the following new fields:
Pass through checkbox that allows you to pass input data to the output under
Originalkey.Trust all certificates checkbox that allows you to use self-signed certificates.
Enable URL Encoding checkbox that allows automatic URL encoding of the request path.
Oracle
Enhanced the Oracle - Merge and Oracle - Update Snaps with the Session parameters fieldset that provides National Language Support (NLS).
Postgres SQL
Enhanced the PostgreSQL Account and PostgreSQL Dynamic Account with SSH Tunneling configurations to encrypt the network connection between the client and the PostgreSQL Database server, thereby ensuring the secure network connection.
RabbitMQ
The RabbitMQ Consumer and RabbitMQ Producer Snaps can now consume messages from the quorum queue by setting the Argument key field as x-queue-type and Argument value as quorum to consume or publish messages from/to the quorum queue.
Redshift
The Redshift accounts support:
Expression enabler to pass values from Pipeline parameters.
Security Token for S3 bucket external staging.
REST
The REST Snaps (Delete, Get, Patch, Post, and Put) now enable you to set the cookie policy specifications using the Cookie Policy dropdown list. This field is case-insensitive.
The REST AWS Sig v4 Account supports:
AWS Security Token Service (STS) to use temporary credentials using the Security Token field.
Expression values for Access-key ID and Secret Key fields.
The REST Snaps now support auto-retry where the Snap retries automatically when the Snap encounters 429 HTTP status code -
Too Many Requestserror.Improved the performance of REST Snaps when the Snaps encountered errors due to Unauthorized (401) or Forbidden (403) statuses though the user credentials are available in the organization and the account type is OAuth2.
Salesforce
Updates in Salesforce Subscriber Snap:
Upgraded the Cometd version from 5.0.9 to the latest 7.0.6 version.
Simplified the logging that provides useful diagnostic information without logging any sensitive data.
The Snap design is enhanced to make the callbacks or listeners asynchronously by the Cometd API when there is a specific event, and the Snap responds accordingly.
The tracking of replay ID is improvised to process the most recent message so that Snap can send that replay ID if there is a need to resubscribe. If the server responds that the replay ID is invalid, Snap automatically sets the Replay ID value to -2 to get all available messages.
Made the Null Setting with Bulk API checkbox in the Salesforce Update, Salesforce Create, and Salesforce Upsert Snaps visible to format a null value.
Secrets Management for Dynamic Accounts
All the Dynamic Account types support Secrets Management, a SnapLogic add-on that allows you to store endpoint credentials in a third-party secrets manager. Orgs using Secrets Management provide the information necessary to retrieve the secrets in expression-enabled dynamic Account fields. During validation and execution, Pipelines obtain the credentials directly from the secrets manager. Learn more about Secrets Management.
Snowflake
The following Snowflake Accounts now support Key Pair Authentication.
Transform
New Snap Application: The Auto Prep Snap provides a data preparation application where you can flatten structured data, include and exclude data fields, and change data types before forwarding the data for further processing.
The Hide whitespace option in the CSV Generator and JSON Generator Snaps allows you to hide the rendering of whitespace as symbols (dot or underscore) in the output that you may have in the CSV or JSON input documents.
The Render whitespace checkbox in the Mapper Snap enables or disables the rendering of whitespace in the input document. When a value in the Expression field has blank spaces (leading, trailing, or spaces in the middle of a string), the spaces are rendered as symbols (dot “.” or underscore “_”) in the output on selecting this checkbox.
The Excel Parser Snap includes the Custom Locale dropdown list that allows you to select a user-defined locale to format numbers as per the selected locale.
The Selected fields in the Pivot Snap allow you to define fields to be unpivoted so that the remaining fields are automatically pivoted.
The XML Generator Snap includes examples on how to escape single (') and double quotes (“) when used with elements or attributes.
All Snaps with the JSON type output preview now include the Render whitespace checkbox, which enables or disables the rendering of whitespace in the output. When you select this checkbox, the Snap renders blank spaces as symbols dot “.” and tab spaces as underscore “_”.
The Snap Catalog has a new category for custom Snaps developed by the SnapLogic Professional Services team. To subscribe to Custom Snaps, or if you have questions regarding the Custom Snaps, contact your SnapLogic Customer Service Manager (CSM).
Deprecated
Microsoft SOAP-based API (Organization Service) and the WS-Trust Security Protocol are being deprecated. If your existing Dynamics CRM Pipelines use the Microsoft Dynamics CRM Snap Pack, contact support@snaplogic.com if you have issues.
Known Issues
When you add an input view to the Databricks - Delete Snap, ensure that you configure the Batch size as 1 in the Snap’s account configuration. For any other batch size, the Snap fails with the exception: Multi-batch parameter values are not supported for this query type.
Data Automation
SnapLogic’s Data Automation solution for cloud data platforms accelerates the movement of data from legacy systems, applications, and many other sources into the cloud data warehouse (CDW). This flexible solution delivers traditional ETL integrations to achieve complex transformations of data in-flight, as well as ELT capabilities to transform data in-place, such that data does not move out of the CDW. Coupled with comprehensive API management capabilities, SnapLogic’s Data Automation solution drives full end-to-end automation of data processes, accelerates the loading/transformation of data into the CDW, and ultimately streamlines business processes for quicker data-to-decision delivery.
ELT Snap Pack
The following enhancements are deployed to the SnapLogic production environment as a stable version of the ELT Snap Pack in this release (4.30 GA). The latest versions have been deployed in either June 2022 or July 2022 releases.
Enhancements
The ELT Load Snap can infer the schema from the source files located in S3 buckets and create, overwrite, and append the target table in your Redshift instance with the source data. It can infer the table schema from the data available in AVRO, CSV, JSON, ORC, and PARQUET files. Learn more at Automatic Schema Inference with ELT Load Snap.
The ELT Snap Pack supports the latest JDBC drivers across CDWs—Azure Synapse, BigQuery, DLP, Redshift, and Snowflake. See Configuring ELT Database Accounts or the respective Account page for the exact versions.
The Value List field in the ELT Pivot Snap provides dynamic suggestions.
The ELT Snowflake Account supports Key Pair Authentication on the cloud environment hosting your Snowflake instance.
You can configure S3 Bucket, Azure Storage, and DeltaLake Storage Gen2 mounts in the ELT DLP Account.
The end Snap SQL query in the ELT Insert Select Snap’s preview output displays the
CREATE TABLE...or theDELETE/DROP TABLEstatements to be run before the query that inserts/loads data into a new table in the Snowflake target CDW.The ELT Load Snap now seamlessly reads from a CSV file in S3 mount point on DBFS (DLP target instance) without causing the SQL exception—
[Simba][SparkJDBCDriver](500051) ERROR processing query/statement.The ELT Insert Select, ELT Merge Into, ELT Load, and the ELT SCD2 Snaps run successfully even when the specified target table does not exist. The Snaps now create a new target table if it does not exist during Pipeline validation.
The new table thus created will not be dropped in the event of a downstream Snap failure during validation.
The ELT SCD2 Snap:
Upon Pipeline validation, displays the final SQL query to be executed on the target CDW in its output preview.
Can replace an existing target table with a new table and load the SCD2 entries from the source table and files into it. Use the new Overwrite existing table option in the Target Table action field to perform this action.
Field names across the ELT Aggregate, ELT Cast Function, ELT String Function, and ELT Transform Snaps are normalized—to maintain consistency.
[This issue is fixed in the June 2022 Release] When you are enclosing the column names within backticks (
`<Column_Name>`) for creating a new target table in a DLP instance using the ELT Load Snap—typically to ensure that the column names are used verbatim—you may encounter the error:ERROR processing query/statement: no viable alternative at input 'FROM'(line X, pos XX). To prevent this error, edit the header in your source file to exclude any special characters, thereby avoiding the use of backticks in the target table column names.[This issue is fixed in the July 2022 Release]: The ELT Select Snap does not honor the LIMIT clause included to query a BigQuery instance, during Pipeline validation. However, this issue does not occur during Pipeline runtime.
[This issue is fixed in the July 2022 Release]: In the case of Azure Synapse, BigQuery, DLP, and Redshift CDWs, the SKEW function available in the General Aggregate Functions List of the ELT Aggregate Snap returns null instead of the actual division-by-zero exception for certain ranges of values (for example, for a series of exactly same values).
[This issue is fixed in the July 2022 Release]: In the case of BigQuery, the ELT Load Snap fails to load data from files in S3 or Redshift when you specify more than one individual file in the File List fieldset. This is due to the API restrictions in Google BigQuery for loading separate files/tables from S3 and Redshift. Alternatively, you can use the File Name Pattern field to load data from multiple files in S3 or Redshift to your BigQuery instance.
Use the File Name Pattern
We recommend that you use the File Name Pattern field to load data from S3 or Redshift, instead of specifying the individual file names and paths in the File List fieldset.
Known Issues
Due to an issue with DLP, aborting an ELT Pipeline validation (with preview data enabled) causes only those SQL statements that retrieve data using bind parameters to get aborted while all other static statements (that use values instead of bind parameters) persist.
For example,select * from a_table where id = 10will not be aborted whileselect * from test where id = ?gets aborted.
To avoid this issue, ensure that you always configure your Snap settings to use bind parameters inside its SQL queries.When loading data from a CSV file to a target DLP table, the header names in the file must exactly match the column names in the target table. Otherwise, the ELT Load Snap returns the error—
Column names should be the same in the target table and CSV fileand aborts the load operation.You cannot add a column to your BigQuery target table with a deleted column name using the ELT Load Snap, as BigQuery reserves deleted column names and data until the pre-configured time travel duration (from 2 through 7 days).
Due to an issue with the Simba Spark JDBC driver for DLP, you cannot insert a NULL value in the nullable columns of Boolean data type in your DLP instance using any of the write-type Snaps—ELT Load, ELT SCD2, ELT Insert Select, ELT Merge Into, and ELT Execute, when the target table schema is available.
The only workaround currently available for this issue is to upgrade your JDBC driver to databricks-jdbc-2.6.25-1.jar; use the corresponding JDBC driver class (
com.databricks.client.jdbc.Driver) and JDBC URL in your Snap account.
This latest JDBC driver for DLP uses a JDBC URL structure and driver class that is different from the Simba Spark JDBC driver.
The ELT Load Snap does not cause any NULL values in new columns added to the target table through the Alter table Load Action.
The ELT Merge Into Snap fails when you perform an UPDATE action in the (hash) distribution key column of an Azure Synapse table. The failure occurs because Azure Synapse does not support modifying values in a table (hash) distribution key column.
The ELT Math Function Snap fails during Pipeline execution even after successful validation against the Redshift CDW due to the incompatible or incorrect data types associated with the target table columns created during the Pipeline validation. To prevent this failure, we recommend that you manually delete the table created during validation before running the Pipeline.
If you have dropped one or more columns from your target table outside of the ELT Load Snap and then use this Snap to add these column(s) back and load data into the table, the Snap adds the new columns to the target table, but not the corresponding data from the source file.
When running without Sub-Query Pushdown Optimization (SPDO), ELT Pipelines that contain an ELT Aggregate Snap configured with one or more GROUP BY ROLLUP fields do not verify the column data types while inserting the Snap output values in the target table. This may lead to incorrect data written to the target table. However, as long as SPDO is on, the same Pipeline runs without this issue.
In the case of Azure Synapse, if you are configuring the Start_Date column as a Target Table Natural Key in the ELT SCD2 Snap, the Snap fails in each of the following scenarios:
The source table/file contains one or more null values.
The target table is empty.
The End date of current row or End date of historical row has a static value, for example: '2021-01-01'.
Behavior Changes
TBD