Sample
- Ankur Parekh
- Mohammed Iqbal
- Lakshmi Manda
On this Page
Overview
The Sample Snap is a Flow type Snap that enables you to generate a sample dataset from the input dataset. This sampling is carried out based on one of the following algorithms and with a predefined pass through percentage. The algorithms available are:
- Linear Split
- Streamable Sampling
- Strict Sampling
- Stratified Sampling
- Weighted Stratified Sampling
These algorithms are explained in the Snap Settings section below.
A random seed can also be provided to generate the same sample set for a given seed value. You can also optimize the Snap's usage of node memory by configuring the maximum memory in percentage that the Snap can use to buffer the input dataset. If the memory utilization is exceeded, the Snap writes the dataset into a temporary local file. This helps you avoid timeout errors when executing the pipeline.
Input and Output
Expected input: The input document from which the sample dataset is to be generated. The Snap accepts both numeric and categorical data; the stratified sampling and weighted stratified sampling algorithms require datasets containing categorical fields.
Expected output:
- First output: Document output containing the sample dataset.
- Second output: Document output containing the dataset that is not present in the first output.
Expected upstream Snaps: Snaps that provide a document output stream containing the dataset. For example, CSV Generator or a combination of File Reader and CSV Parser.
Expected downstream Snaps: Snaps that accept a document input. For example, Mapper or a combination of JSON Parser and File Writer.
Prerequisites
A basic understanding of the sampling algorithms supported by the Snap is preferable.
Configuring Accounts
Accounts are not used with this Snap.
Configuring Views
Input | This Snap has exactly one document input view. |
|---|---|
| Output | This Snap has at most two document output views. |
| Error | This Snap has at most one document error view. |
Troubleshooting
None
Limitations and Known Issues
None
Modes
- Ultra Pipelines: Works with Ultra Pipelines only when Streamable Sampling is selected as the sampling algorithm.
Snap Settings
| Label | Required. The name for the Snap. Modify this to be more specific, especially if there are more than one of the same Snap in the pipeline. |
|---|---|
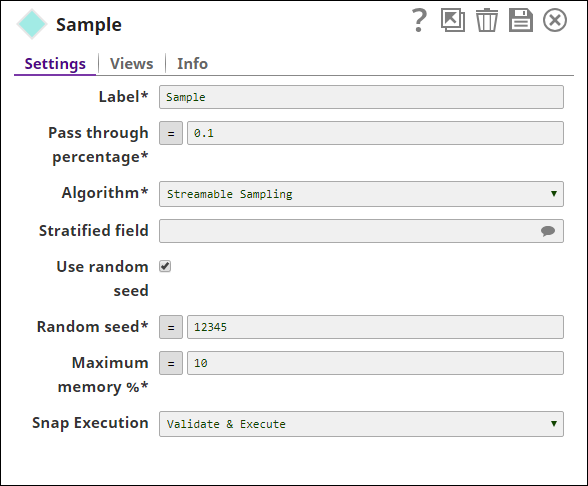
| Pass through percentage | Required. The number of records, as a percentage, that are to be passed through to the output. This value is treated differently based on the algorithm selected. Default value: 0.5 The number of records output by the Snap is determined by the pass through percentage as well as the total number of records present. If there are 100 records and the pass through percentage is 0.5 then 50 records are expected to be passed through. If there are 103 records and the pass through percentage is 0.5 then only 51 records are expected to be passed through. This varies further if the algorithm is stratified or weighted stratified, in those cases, the number of records per class is also factored. |
| Algorithm | Required. The sampling algorithm to be used. Choose from one of the following options in the drop-down menu:
Default value: Streamable Sampling If Stratified Sampling or Weighted Stratified Sampling is selected, the Stratified field property must also be configured. |
| Stratified field | Conditional. The field in the dataset containing classification information pertaining to the data. This is a suggestible property and lists all the fields in the incoming dataset. Select the field that is to be treated as the stratified field and the sampling is done based on this field. Example: Consider an employee record dataset containing fields such as Name, ID, Position, and Location. The fields Position, and Location help you classify the data, so the input in this property for this case is $Position or $Location. Default value: None |
| Use random seed | If selected, Random seed is applied to the randomizer in order to get reproducible results. Default value: Selected |
| Random seed | Conditional. This is required if the Use random seed property is selected. Number used as static seed for the randomizer. Default value: 12345 The result is different if the value specified in Maximum memory % or the JCC memory are different. |
| Maximum memory % | Required. The maximum portion of the node's memory, as a percentage, that can be utilized to buffer the incoming dataset. If this percentage is exceeded then the dataset is written to a temporary local file and then the sample generated from this temporary file. This configuration is useful in handling large datasets without over-utilization of the node memory. The minimum default memory to be used by the Snap is set at 100 MB. Default value: 10 |
Snap Execution | Select one of the following three modes in which the Snap executes:
Default Value: Execute only |
Temporary Files
During execution, data processing on Snaplex nodes occurs principally in-memory as streaming and is unencrypted. When larger datasets are processed that exceeds the available compute memory, the Snap writes Pipeline data to local storage as unencrypted to optimize the performance. These temporary files are deleted when the Snap/Pipeline execution completes. You can configure the temporary data's location in the Global properties table of the Snaplex's node properties, which can also help avoid Pipeline errors due to the unavailability of space. For more information, see Temporary Folder in Configuration Options.Example
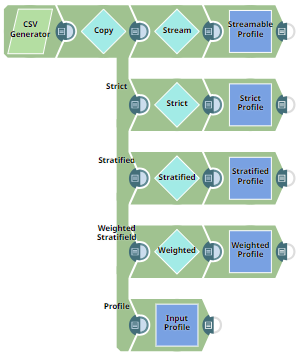
Data Sampling
This example demonstrates all sampling algorithms applied to a document. Each of the following sampling algorithms is demonstrated:
- Streamable Sampling
- Strict Sampling
- Stratified Sampling
- Weighted Stratified Sampling
Download this pipeline.
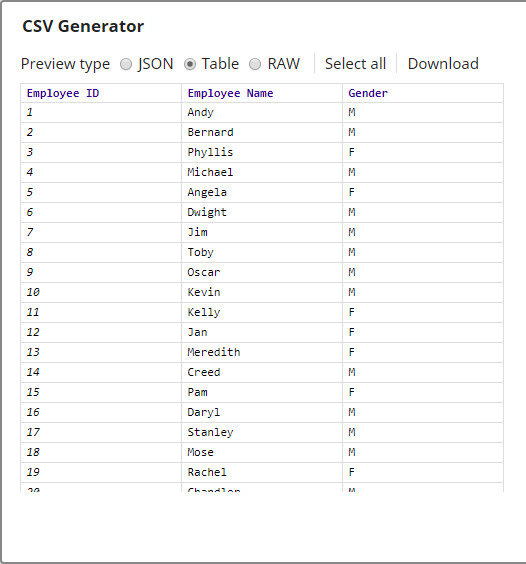
The input is a CSV document generated by the CSV Generator Snap. A preview of the output from the CSV Generator is as shown below:
This document is passed to the Copy Snap where it generates five document streams, four of these go into the Sample Snap, and one goes into a Profile Snap. The Profile Snap generates a statistical profile of the incoming document, in this case the input document for the Sample Snaps. A preview of the output from the Profile Snap is as shown below:
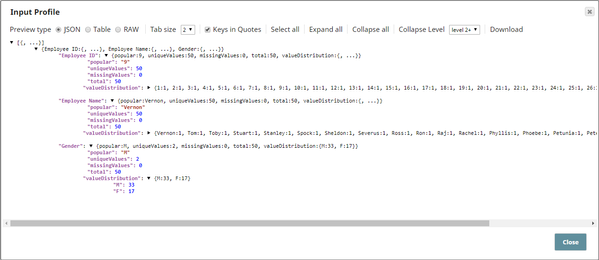
There are two aspects of the input document based on the Profile Snap's output:
- Total number of records: 50
- Number of classes: 2 (M, F)
- Number of M documents: 33
- Number of F documents: 17
This data is useful in understanding how the Sample Snap creates a sample dataset for each sampling algorithm selected.
Using the same pass-through percentage (50%), all four sampling algorithms are demonstrated here:
- Streamable Sampling: The Sample Snap is configured as shown below
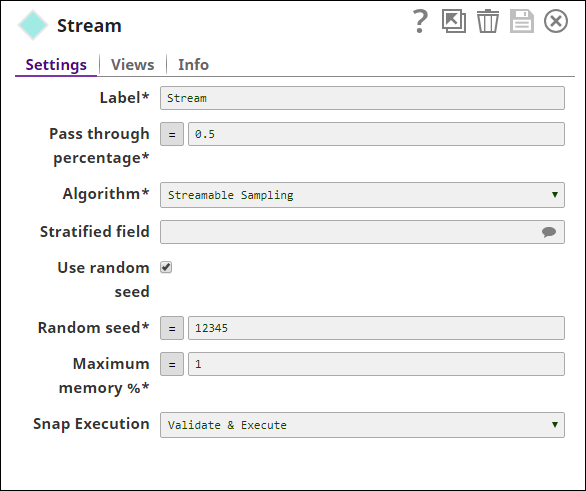
The output from the Snap is as shown below: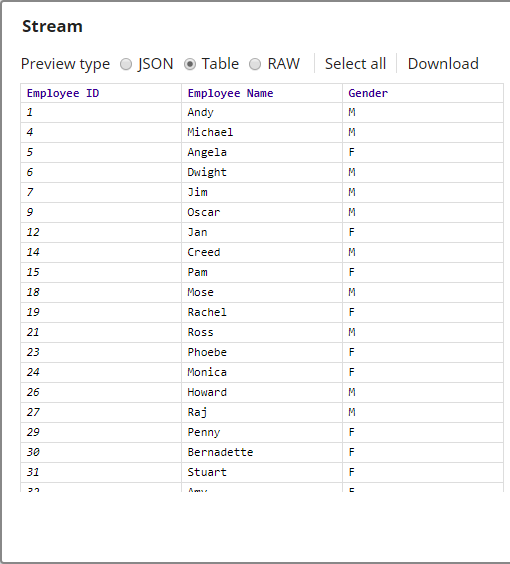
The downstream Profile Snap's output is useful in understanding the sample dataset's attributes: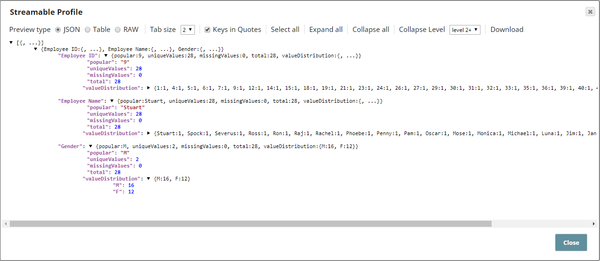
The total number of documents in the sample dataset is 28, close to the pass-through percentage. - Strict Sampling: The Sample Snap is configured as shown below:
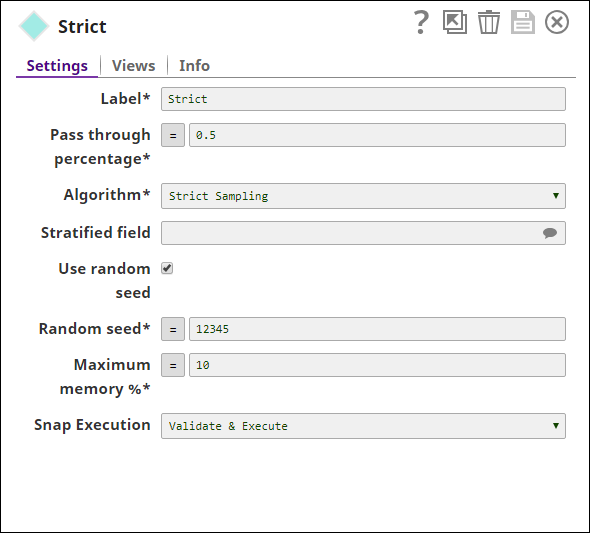
The output from the Snap is as shown below: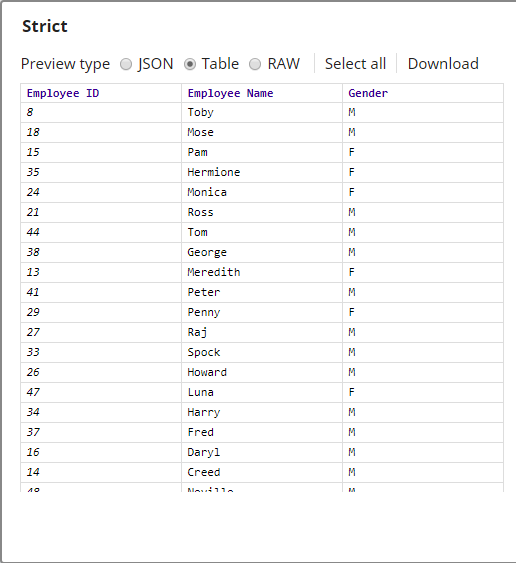
The downstream Profile Snap's output is useful in understanding the sample dataset's attributes: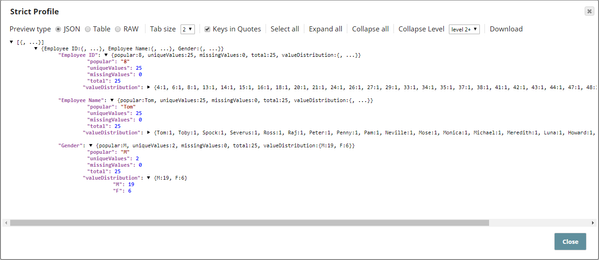
The total number of documents in the sample dataset is 25. Exactly the same as the pass-through percentage. - Stratified Sampling: The Sample Snap is configured as shown below:
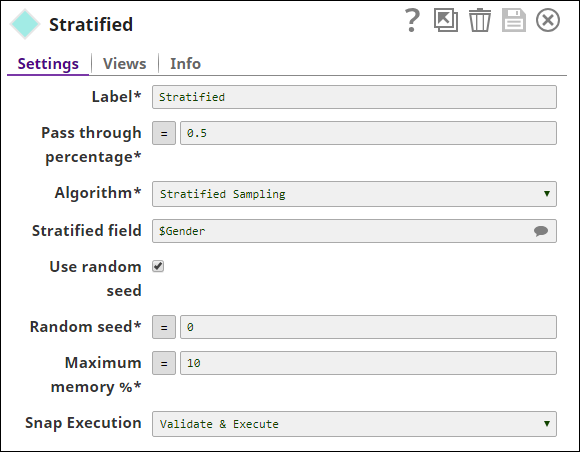
The $Gender field is specified as the stratified field. The Snap selects equal number of documents for each class of the stratified field while maintaining the pass-through percentage.
The output from the Snap is as shown below:
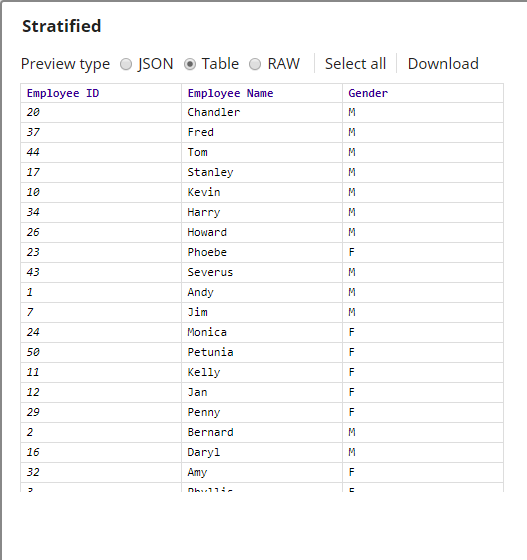
The downstream Profile Snap's output is useful in understanding the sample dataset's attributes: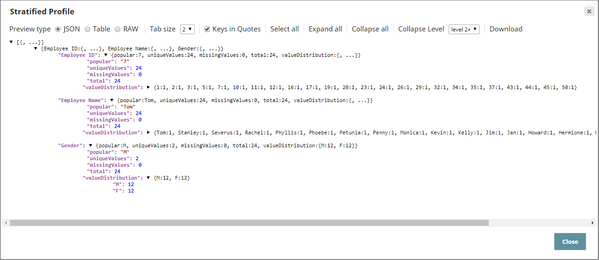
The total number of documents in the sample dataset is 24.- Weighted Stratified Sampling: The Sample Snap is configured as shown below:
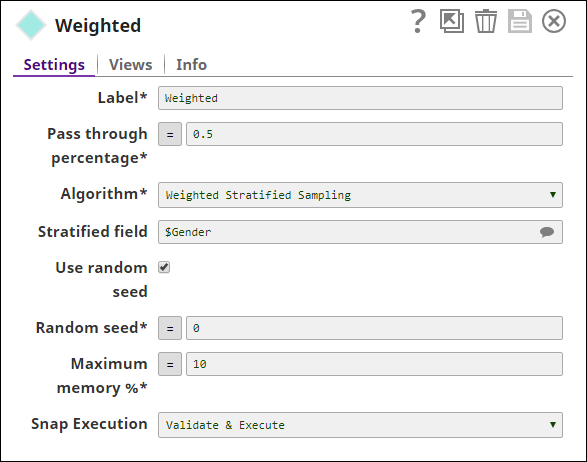
The $Gender field is specified as the stratified field. The Snap maintains the pass-through percentage while also maintaining the ratio of the classes.
The output from the Snap is as shown below: 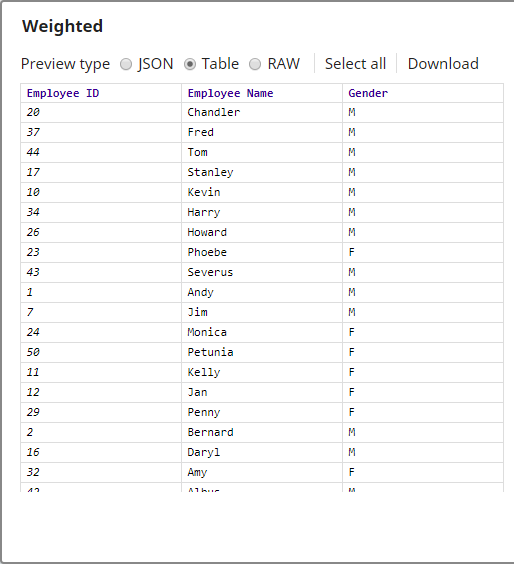
The downstream Profile Snap's output is useful in understanding the sample dataset's attributes: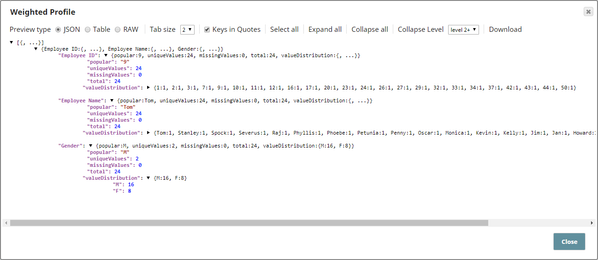
The total number of documents in the sample dataset is 24.
Download this pipeline.
Downloads
Important steps to successfully reuse Pipelines
- Download and import the pipeline into the SnapLogic application.
- Configure Snap accounts as applicable.
- Provide pipeline parameters as applicable.
Snap Pack History
Have feedback? Email documentation@snaplogic.com | Ask a question in the SnapLogic Community
© 2017-2024 SnapLogic, Inc.