Key New Features
IIP Redesign: Features a new display across Designer, Manager, and Dashboard. The redesign includes changes to icons, toolbars, and menus.
AutoSync: Moves data easily from your source systems to cloud data warehouse endpoints. You can access AutoSync by clicking the Designer tab dropdown in the IIP main page. AutoSync is a subscription feature. Contact your CSM or customer support at support@snaplogic.com to subscribe to this feature.
AutoPrep: Provides suggestions for handling null or empty values.
Move SnapLogic Assets from one version to another in the same API container or to a version in a different API.
Specify the SnapLogic Assets to include when creating an API from existing Assets.
Select to generate an Ultra or Triggered Task when creating an API version using Design First.
Data Automation: Introduced the ELT Create View Snap.
Studio: Metrics charts for monitoring trends over time and troubleshooting.
Dot Releases
Platform
Date of Update | Snaplex Build | Update |
|---|---|---|
main-13879 - 4.30.1.1 Patch 2 (Recommended) | We strongly recommend that you use this version for your Snaplexes even if you are currently on a prior 4.30 Snaplex version.
| |
main-13393 4.30 Patch 1 | Runtime metrics no longer cause slow performance. |
Snaps
Snap Pack | Date of Update | Snap Pack Version | Updates |
|---|---|---|---|
| 430patches18149 | The PostgreSQL Account and Google AlloyDB Account now reads the NaN values in the Numeric column when used with the latest JDBC JAR driver. | |
| 430patches18079 | The RabbitMQ Consumer and RabbitMQ Producer Snaps now display an informative error message when you do not provide the Queue type attribute in the Quorum queue or provide conflicting Queue types for Classic and Quorum queues. | |
| 430patches18305 | The September 2022 patch release covers multiple enhancements across different Snaps in the Databricks Snap Pack. The complete list is available in the Snaps-->Enhancements section of the Release Notes. | |
| 430patches17796 | ||
| 430patches18196 | The September 2022 patch release covers multiple enhancements across different Snaps in the ELT Snap Pack. The complete list is available in the Data Automation section of the Release Notes. | |
| 430patches18099 |
| |
| 430patches18223 | The MongoDB Update Snap in a low-latency feed Ultra Pipeline now correctly acknowledges the requests. | |
| 430patches18119 | The Transcoder Snap used in a low-latency feed Ultra Pipeline now correctly acknowledges the requests. | |
| 430patches18070 | The Pipeline Execute Snap with binary output that is used in a low-latency feed Ultra Pipeline now works as expected. The requests are now correctly acknowledged. | |
| 430patches17933 |
| |
| 430patches18036 | The Salesforce Read Snap now correctly parses the 2-byte UTF-8 characters in Windows OS in PK chunking mode. | |
| 430patches17802 | The Avro Parser Snap now displays the decimal number correctly in the output view if the column’s logical type is defined as a decimal. | |
| 430patches17872 | The Azure Directory Search Snap does not fetch duplicate records when the Group result checkbox is deselected. | |
| 430patches17962 | The Snowflake Bulk Load Snap now triggers the metadata query only once, even for invalid input, thereby improving the performance of the Snap. | |
| 430patches17894 | The Generic JDBC Snaps connecting to the DB2 database now take less time to execute, thereby improving the performance. | |
| 430patches17851 | The REST Post Snap now works without displaying any errors when the Show all headers checkbox is selected and the Content-type is text/xml or application/xml. | |
| 430patches17894 | The following Snaps now work as expected when the table name is dependent on an upstream input: | |
| 430patches17841 | Introduced the Google AlloyDB Snap Pack— a fully managed PostgresSQL-compatible database service that you can use for all your database workloads. This Snap Pack offers the following Snaps: | |
430patches17737 | AutoPrep enables you to handle empty or null values. |
Snaps
Enhancements
The name of the Databricks - Multi Execute Snap is simplified to Databricks - Execute Snap.
The Use Result Query checkbox in the Databricks - Execute Snap enables you to include in the Snap's output the result of running (during validation) each SQL statement specified in the Snap.
The Manage Queued Queries property in the Databricks Snap Pack enables you to decide whether a given Snap should continue or cancel executing the queued Databricks SQL queries.
The Retry mechanism for the Databricks Snap Pack enables the following Databricks Snaps to repeatedly perform the selected operations for the specified number of times when the Snap account connection fails or times out.
Databricks - Bulk Load (when the Source Type is Input View)
Databricks - Merge Into (when the Source Type is Input View)
The following fields are added to each Databricks Snap as part of this enhancement:
Number of Retries: The number of attempts the Snap should make to perform the selected operation when the Snap account connection fails or times out.
Retry Interval (seconds): The time interval in seconds between two consecutive retry attempts.
Known Issues
Databricks Snap Pack: Due to an issue with DLP, aborting a Databricks Pipeline validation (with preview data enabled) causes only those SQL statements that retrieve data using bind parameters to get aborted while all other static statements (that use values instead of bind parameters) persist. For example, select * from a_table where id = 10 will not be aborted while select * from test where id = ? gets aborted.
To avoid this issue, ensure that you always configure your Snap settings to use bind parameters inside its SQL queries.
Data Automation
New Snap
Introduced the ELT Create View Snap that enables you to create a new view when the view does not exist in the target database or drop the existing view and create a new view.
Enhancements
The ELT Insert-Select Snap is more flexible and easier to use, especially if the number of columns in your source data set is very large. You can choose to update values only in a subset of columns in the target table.
The ELT Execute Snap can retrieve and execute SQL queries from the upstream Snap's output when referenced in the SQL Statement Editor using the Expression language (with the Expression button enabled).
The ELT Load Snap can infer the schema from the source files in Amazon S3, ADLS Gen2, Microsoft Azure Blob Storage, or Google Cloud Storage location and use it to create, overwrite, and append the target table in your Snowflake instance with the source data. The source files can be in the AVRO, CSV, JSON, ORC, or PARQUET format. Learn more at Automatic Schema Inference with ELT Load Snap.
The Target Table Name in the following Snaps supports retrieving editable views with the table names from the selected target schema:
The pivot values in the ELT Pivot Snap turns dynamic when you select Enable dynamic pivot values. The following field settings are added as part of this dynamic pivot values feature:
Filter Predicate List: A fieldset to filter the predicate list of the pivot values.
Pivot Values Filter: Condition required to filter the pivot values.
Boolean Operator: Predicate condition type through AND or OR Boolean operators
Sort Order: Sorting order of the pivot values.
In the ELT Account, you can specify the type of Microsoft Azure external storage location (source)—an Azure Data Lake Gen2 or a Blob Storage—to access your source data using the Storage Integration type of authentication and load it to your target Snowflake instance.
Known Issues
Due to an issue with the Redshift COPY INTO SQL for PARQUET input files, the ELT Load Snap fails to perform ALTER TABLE actions before loading data from a PARQUET source file to the target table in Redshift. This issue does not occur when the source file is in CSV or another format.
Due to an issue with BigQuery table schema management (the time travel feature), an ALTER TABLE action (Add or Update column) that you attempt after deleting a column (DROP action) in your BigQuery target table causes the table to break and the Snap to fail.
As a workaround, you can consider either avoiding ALTER TABLE actions on your BigQuery instance using the Snap or creating (CREATE) a temporary copy of your table and deleting (DROP) it after you use it.
Due to an issue with Databricks Runtime Version 11 and above, the ELT Aggregate Snap fails to calculate the value for the linear regression aggregate function REGR_R2 for the target DLP instance and returns a cast exception. As a workaround, you can revert your Databricks Runtime Version to 10.5 or below.
ELT Pipelines built using an ELT SCD2 or an ELT Load Snap fail to perform the DROP AND CREATE TABLE and ALTER TABLE operations on Delta tables when working with a Databricks SQL persona on the AWS Cloud with the error
Operation not allowed: ALTER TABLE RENAME TO is not allowed for managed Delta tables on S3. However, the same action runs successfully with the Data Science and Engineering persona on the AWS Cloud.This is due to the limitation with the Databricks SQL Admin Console that does not allow adding the configuration parameter
spark.databricks.delta.alterTable.rename.enabledOnAWS trueto its SQL Warehouse Settings.
Due to an issue with the Redshift COPY INTO SQL for PARQUET input files, the ELT Load Snap fails to perform ALTER TABLE actions before loading data from a PARQUET source file to the target table in Redshift. This issue does not occur when the source file is in CSV or another format.
The ELT Load Snap cannot automatically infer schema from GZIP-compressed source files located in an ADLS Gen2 storage location for loading the data into Snowflake target tables.
Because BigQuery does not support Automatic Schema Inferencing (ASI) from source files in Amazon S3, the ELT Load Snap fails to produce the required output when you choose Drop and Create table as the Load Action and define the Target to Source Column Map in the Snap’s settings. However, the same configuration works fine for Pipeline validation purposes.
Snowflake does not support COPY statements that result in data transformation in any of the validation modes it allows. Therefore, the ELT Load Snap fails during Pipeline validation when the number of columns you define in the Target to Source Column Map field set is not the same as the number of columns in the target table. But the same Pipeline runs successfully because this limitation does not apply to Pipeline execution.
As a workaround for this limitation, ensure that you specify error_on_column_count_mismatch=false in the Format Option field under the File Format Option List field set.
While you specify an SQL statement in the SQL Statement Editor of an ELT Snap as an expression, the dynamic validation for the expression displays inline errors when there is more than one incoming document and without the
'__sql__'key to the current Snap, when you select Get Preview Data checkbox in the previous Snap, and when Preview Document Count in your user settings is set to a value more than 1.To prevent this error and similar ones, do not select the Get Preview Data checkbox in the previous Snap, set the Preview Document Count in your user settings to 1, or append a condition
where 1 = 0to the SQL statement with the Get Preview Data checkbox selected.
Due to a limitation in Snowflake in inferring the source files (and thereby the source schema) based on file name patterns in a Storage Integration-based session, the ELT Load Snap fails to load data into your Snowflake target instance based on any File Name Pattern that you specify. As a workaround, we recommend that you use the File List field set to define the source data file locations for the Snap to load the data.
If you are using Azure Active Directory password--based authentication on the older Snap Pack version, you could encounter an error while using ELT Pipelines in Azure Synapse. This is due to absence of the following two JAR files in the ELT Snap Pack. Add these two JAR files to the list that you want to use to resolve the issue:
MSAL4J (Microsoft Authentication Library for Java) during compile time.
Nimbusds oauth for runtime.
However, this error would not occur when you use the latest Snap Pack version
430patches18196.
IIP UI Redesigns
The UI for SnapLogic IIP is redesigned for the September release.
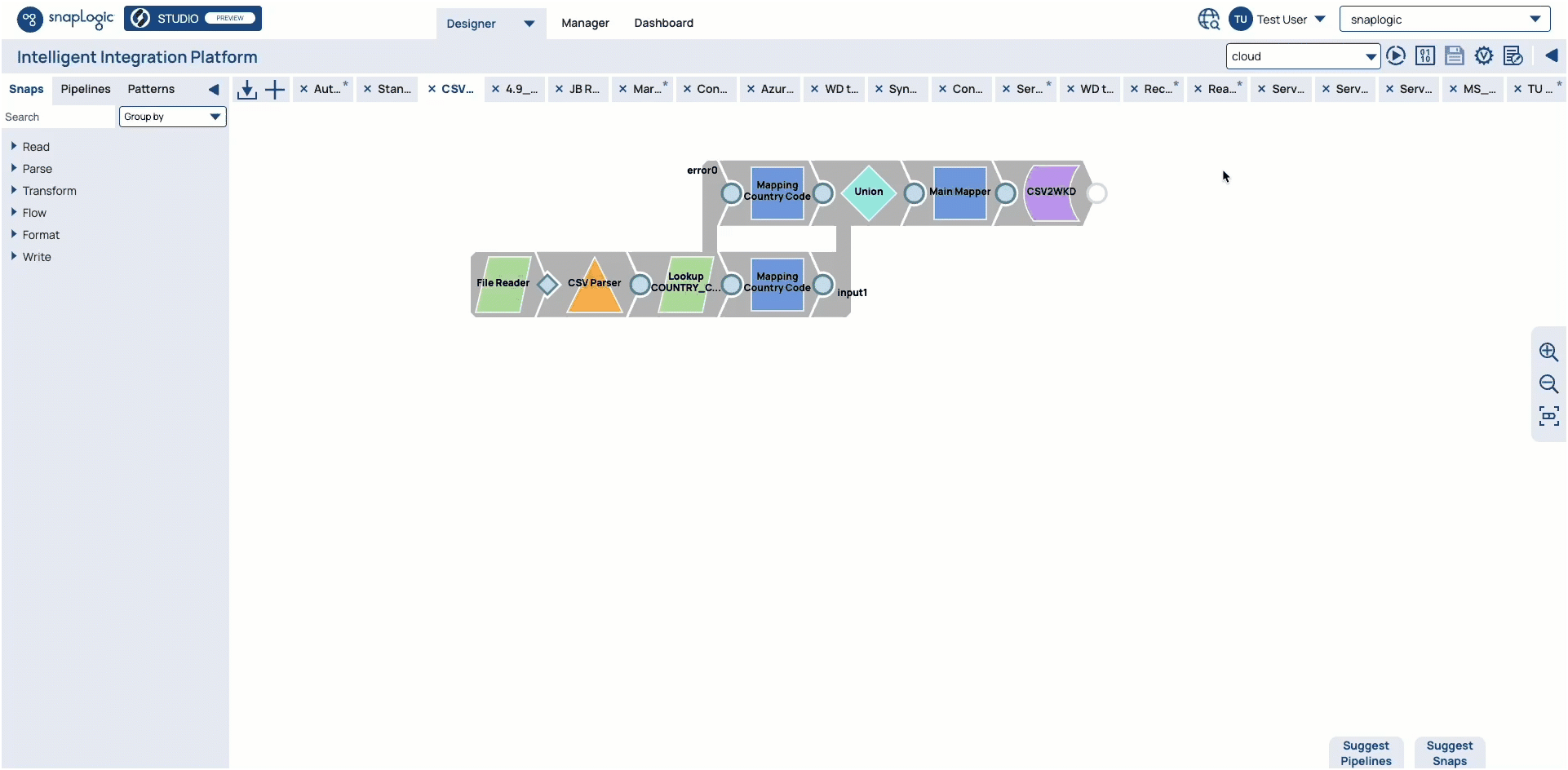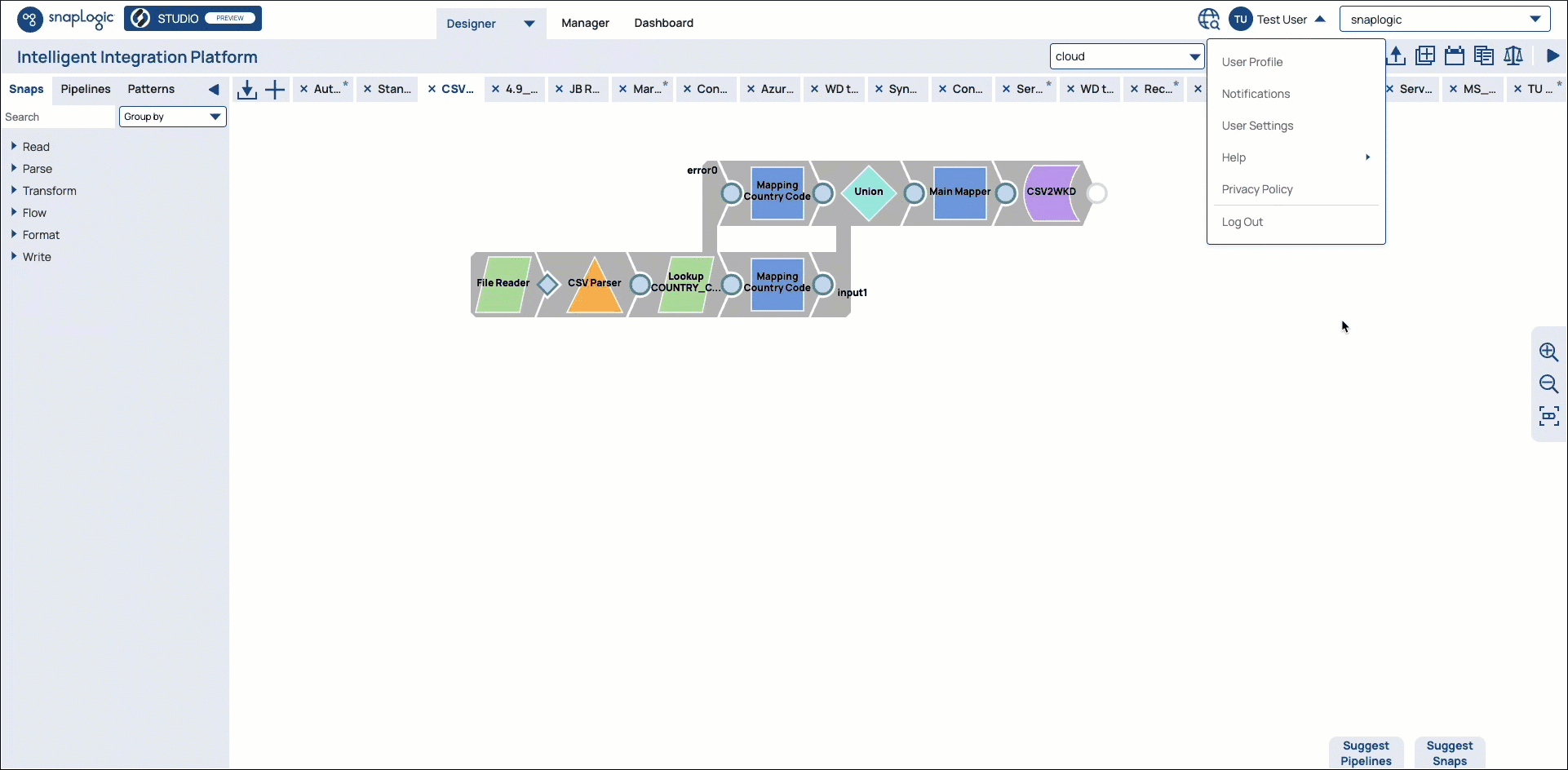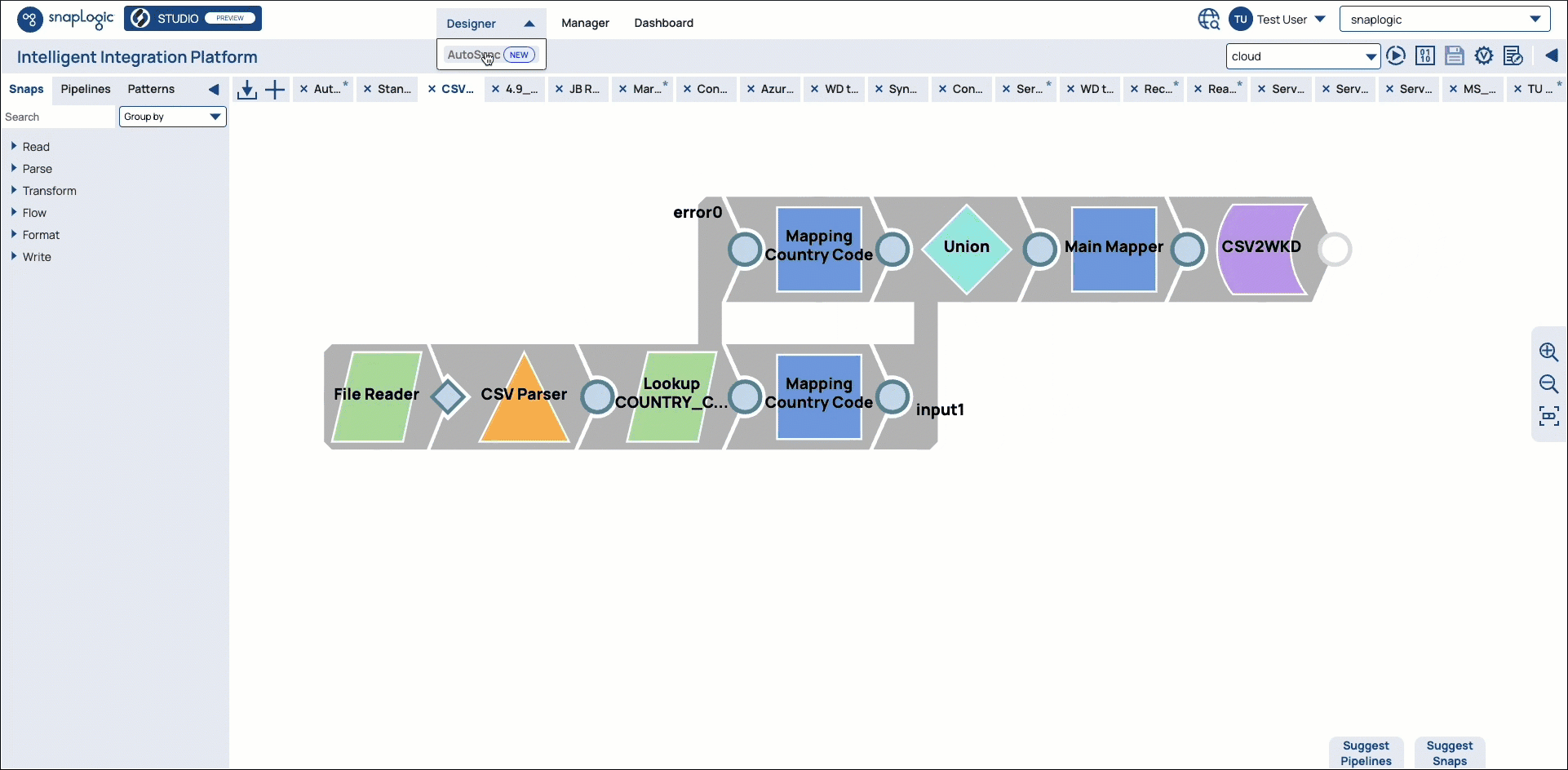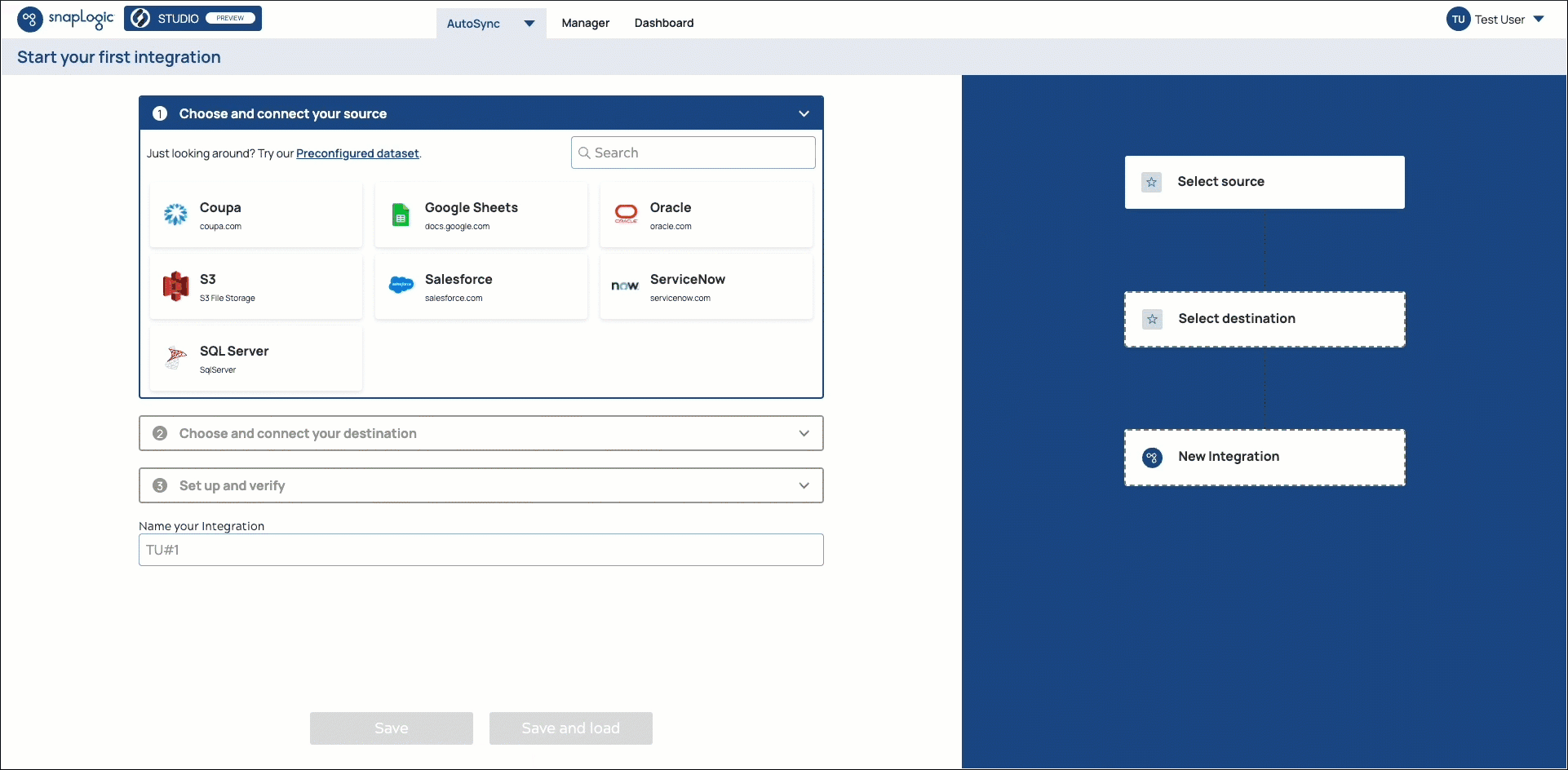
Note the following UI changes:
The Designer tab has a dropdown menu to launch the new SnapLogic AutoSync application.
A dropdown menu replaces the user profile toolbar. Clicking
 displays the menu with the following options:
displays the menu with the following options:User Profile: Click to view the details of your user profile.
Notification: This option displays a red dot if you have notifications. Click to view your notifications.
User Settings: Click to view the User Settings dialog.
Help: Click to see a menu of resources.
Privacy policy: Click to view the SnapLogic Cookie and Privacy Policy.
Logout: Click to log out of SnapLogic.
The Universal Search icon is changed from binoculars (
) to a globe () and is now located to the left of your user profile.The SnapLogic logo (
) replaces the grid icon ().The Designer toolbar displays icons for the following actions:
Execute Pipeline
Check Pipeline Statistics
Save Pipeline
Validate Pipeline
Edit Pipeline Properties
You can view the remaining icons by extending the toolbar. Note that the Move (![]() ) and Delete (
) and Delete (![]() ) actions are now only available in Manager.
) actions are now only available in Manager.
Unsaved Pipelines in Designer display an asterisk on the Pipeline name tab.
The right side of the Designer canvas provides controls to zoom in, zoom out, and zoom to fit.
The following table compares the new interactions with the old:
If you want to: | Before, you would: | Now: |
|---|---|---|
Change user settings | Use buttons near your profile | Use the dropdown menu next to your avatar |
Delete or move a Pipeline | Use buttons on the Designer toolbar | Use buttons on the Manager toolbar |
Search | Click | Click |
Switch between IIP and AutoSync | Click | To:
|
Access product documentation from the UI | Click | In the user profile dropdown menu, click Help > Product Documentation |

SnapLogic AutoSync
SnapLogic AutoSync is a data ingestion tool that simplifies the tasks of replicating and synchronizing data for data analysts and business analysts. Using AutoSync, you can quickly load data from your cloud apps into a cloud data warehouse using a simple, no-code, point-and-click user interface. AutoSync has the following features:
Syncs large amounts of data from various sources, faster and at regular intervals
Loads data to popular cloud data warehouses
Tracks data changes and schema changes, and performs incremental data loads
Stores historical data using Slowly Changing Dimension Type 2 (SCD2) so that data changes are not lost
Supports multiple data types
AutoSync integration is a simple three-step process: select, load, and integrate without any coding. You simply configure your source and destination endpoints and then load your data.
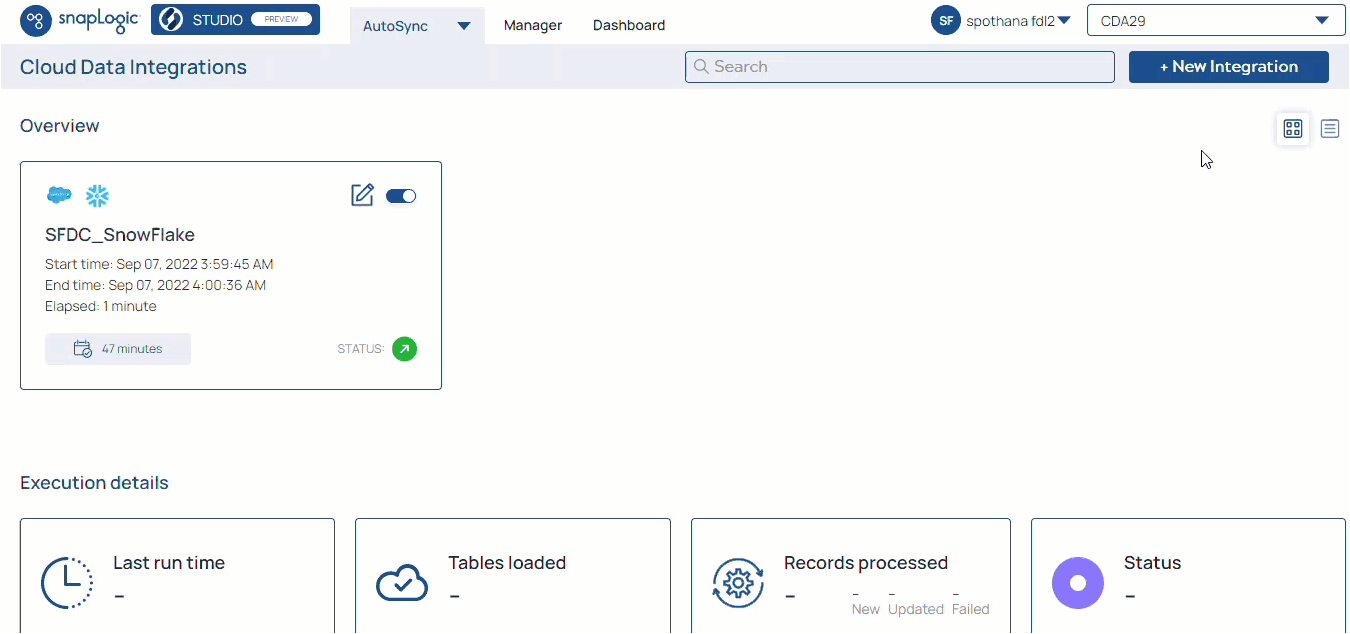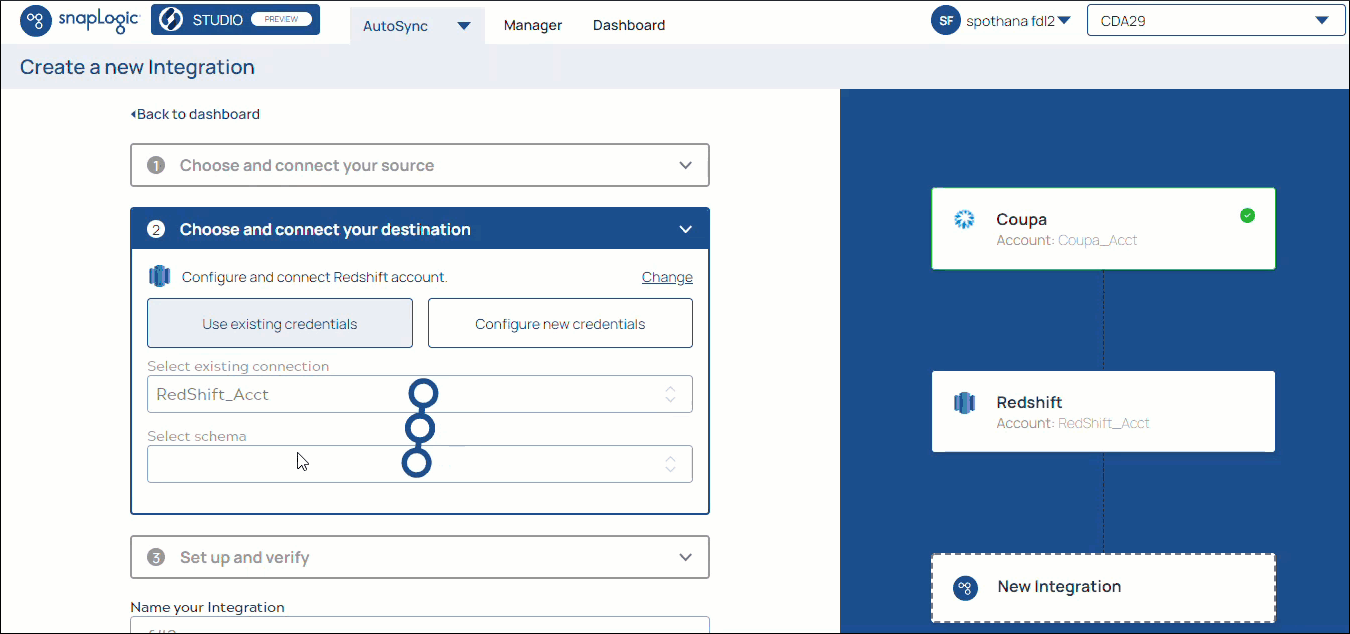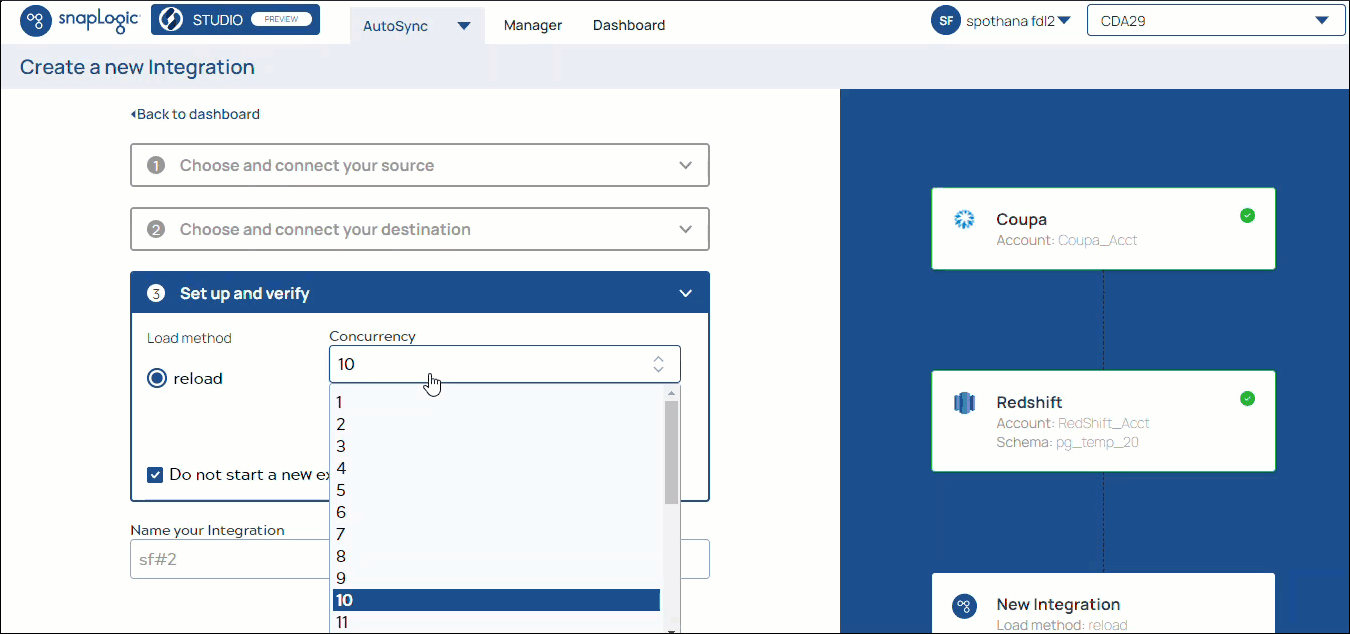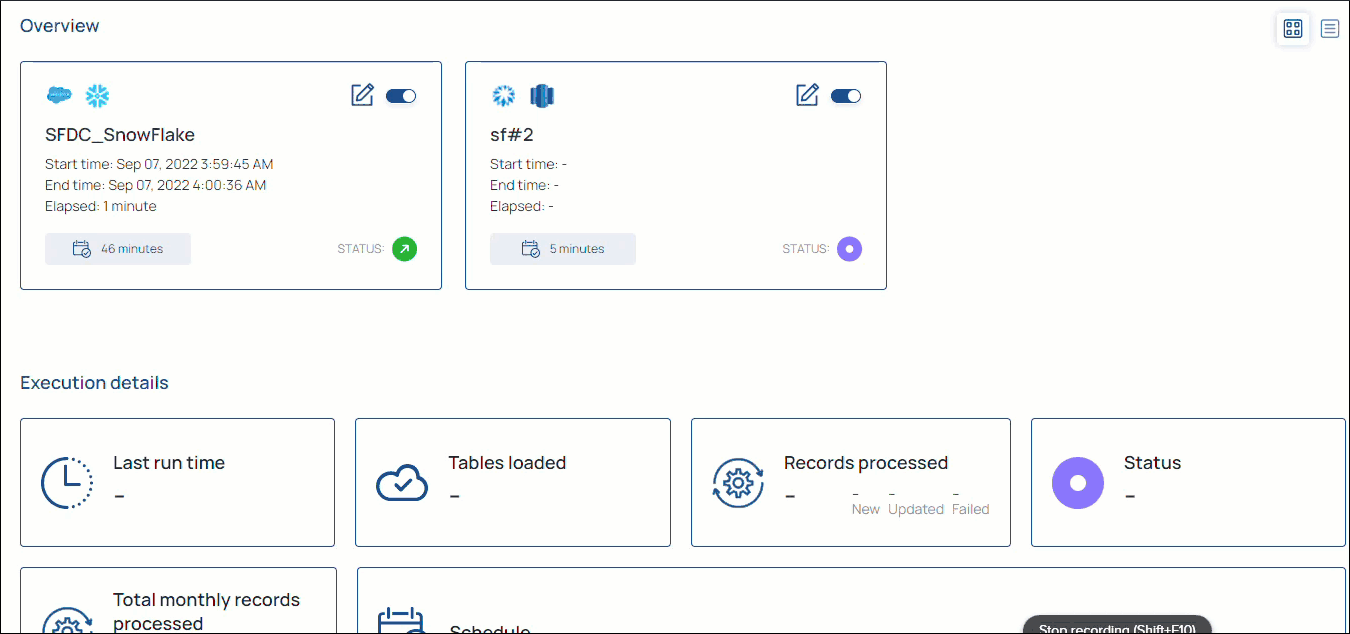
Known Issue
The upsert action in the Setup and Verify section of AutoSync is updating the data as Updated records for alternate executions, even when there is no change in the source data.
SnapLogic AutoPrep
AutoPrep enables you to perform simple data transformations without writing expressions. You can use AutoPrep to prepare data for analysis, reporting, and machine learning. AutoPrep supports the following:
Flattening leaf nodes of hierarchical data structures
Removing fields
Changing the data type of
String,Date,Integer,Number, andBooleanfieldsCreating rules to handle null and missing values:
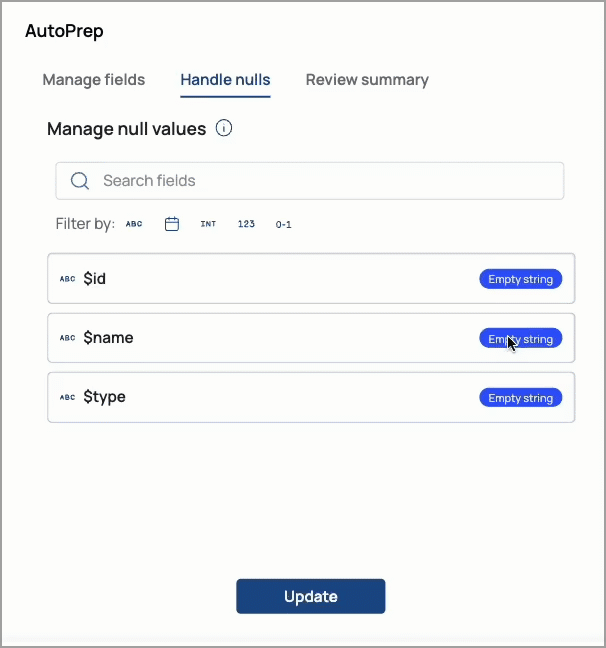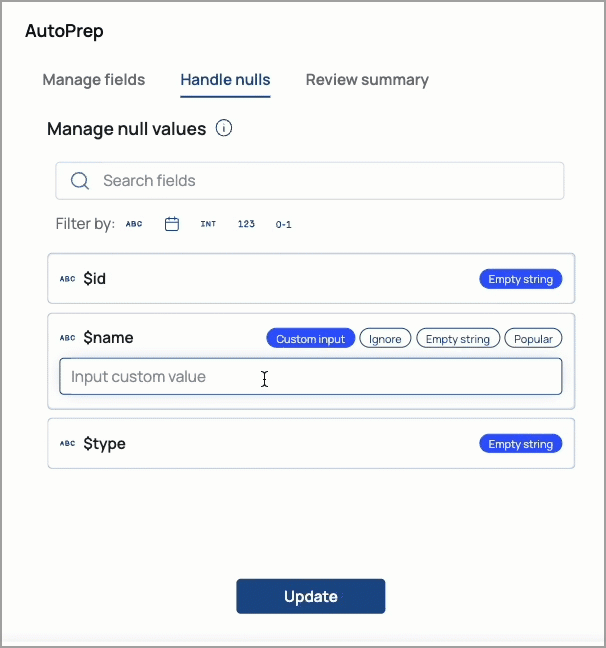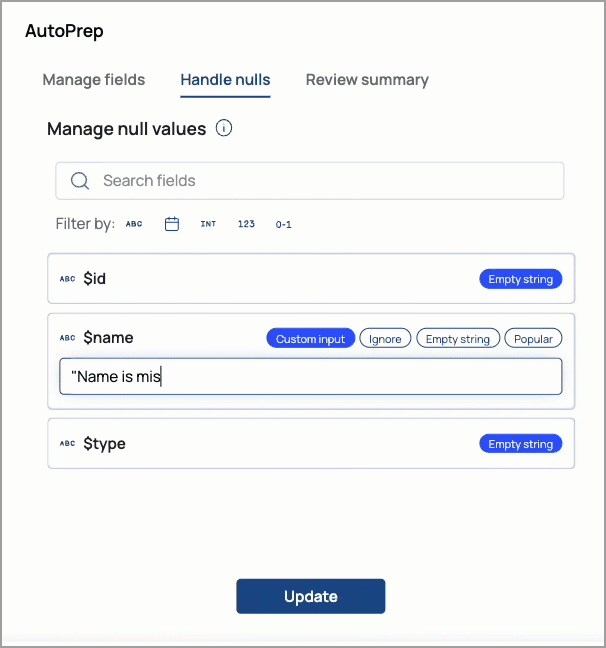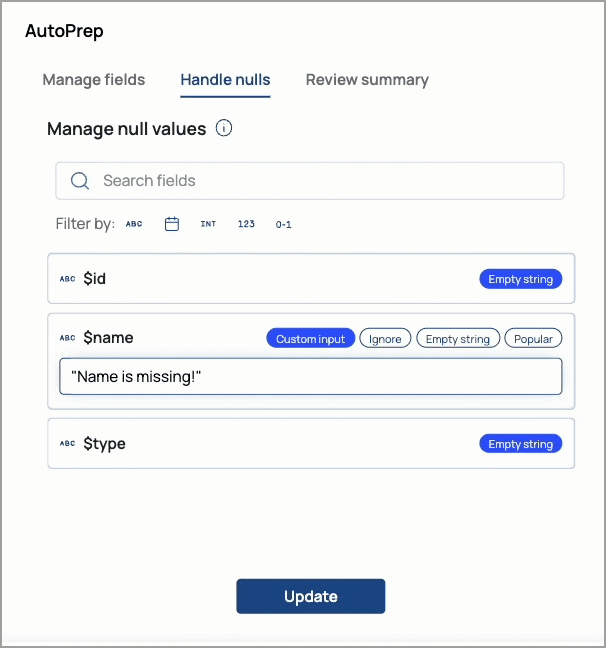
The following demonstrates the AutoPrep interface:
SnapLogic Studio (Preview)
This release includes a navigation change and a new Metrics page.
Navigation Change
You can no longer navigate to Flows from the IIP. Instead, open Studio, where you can access the classic IIP interface, AutoSync, or Flows from the dropdown menu:

Metrics Page
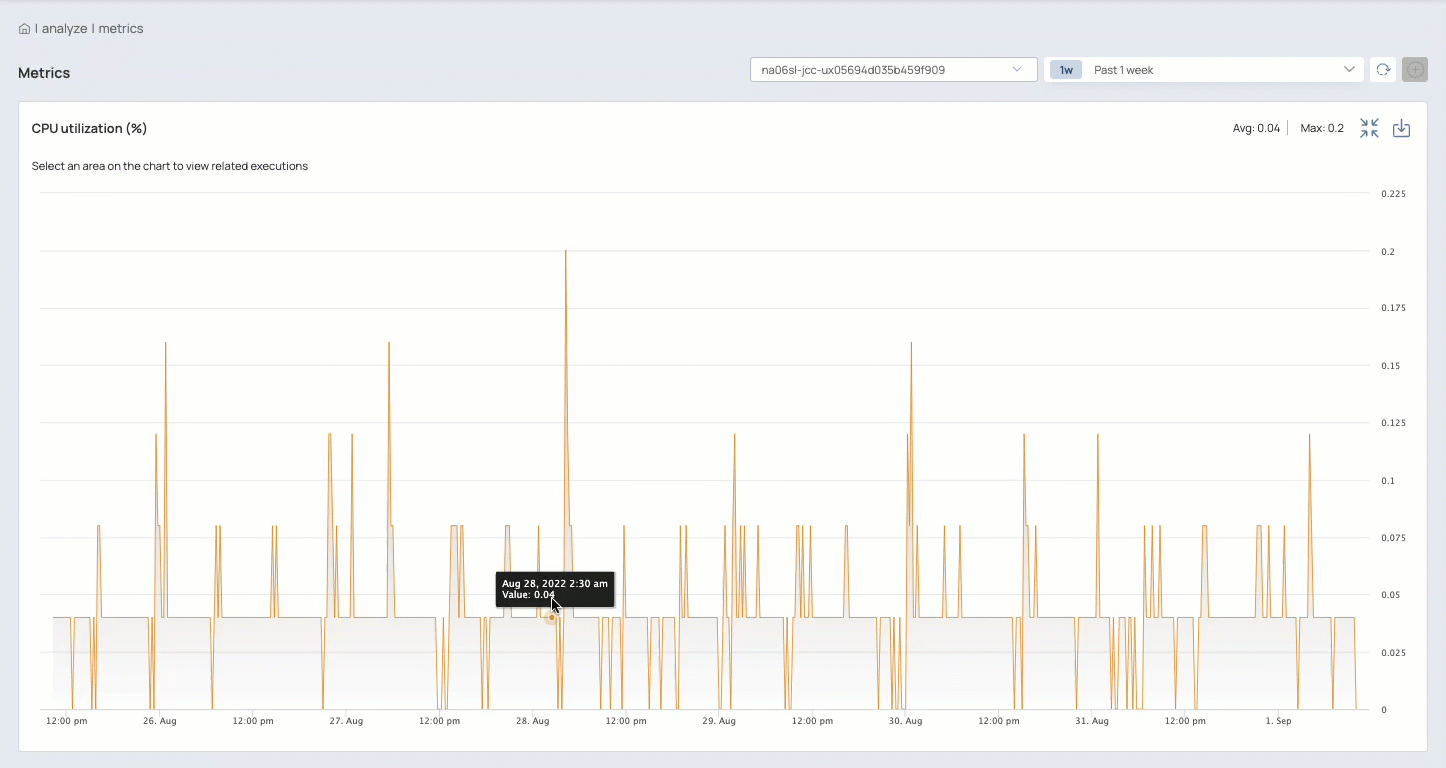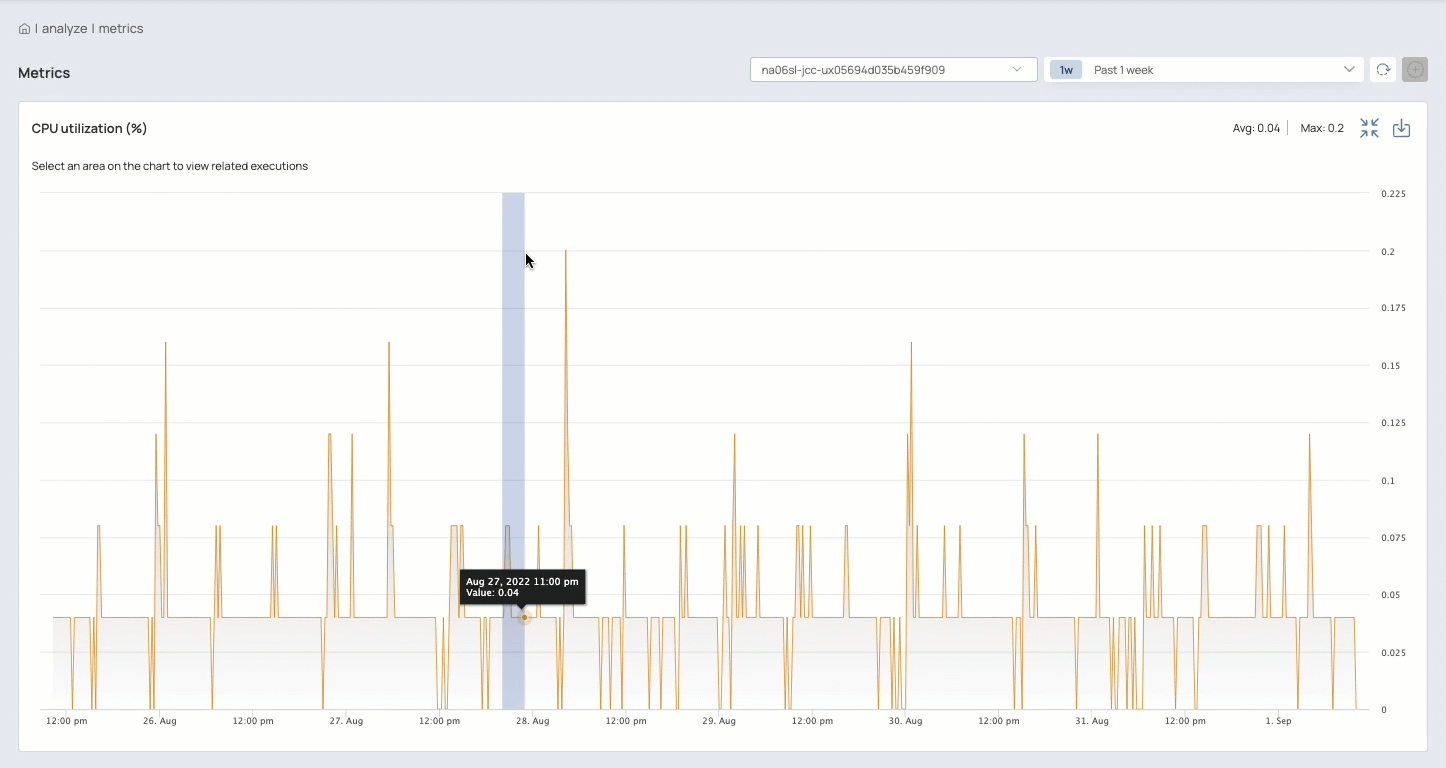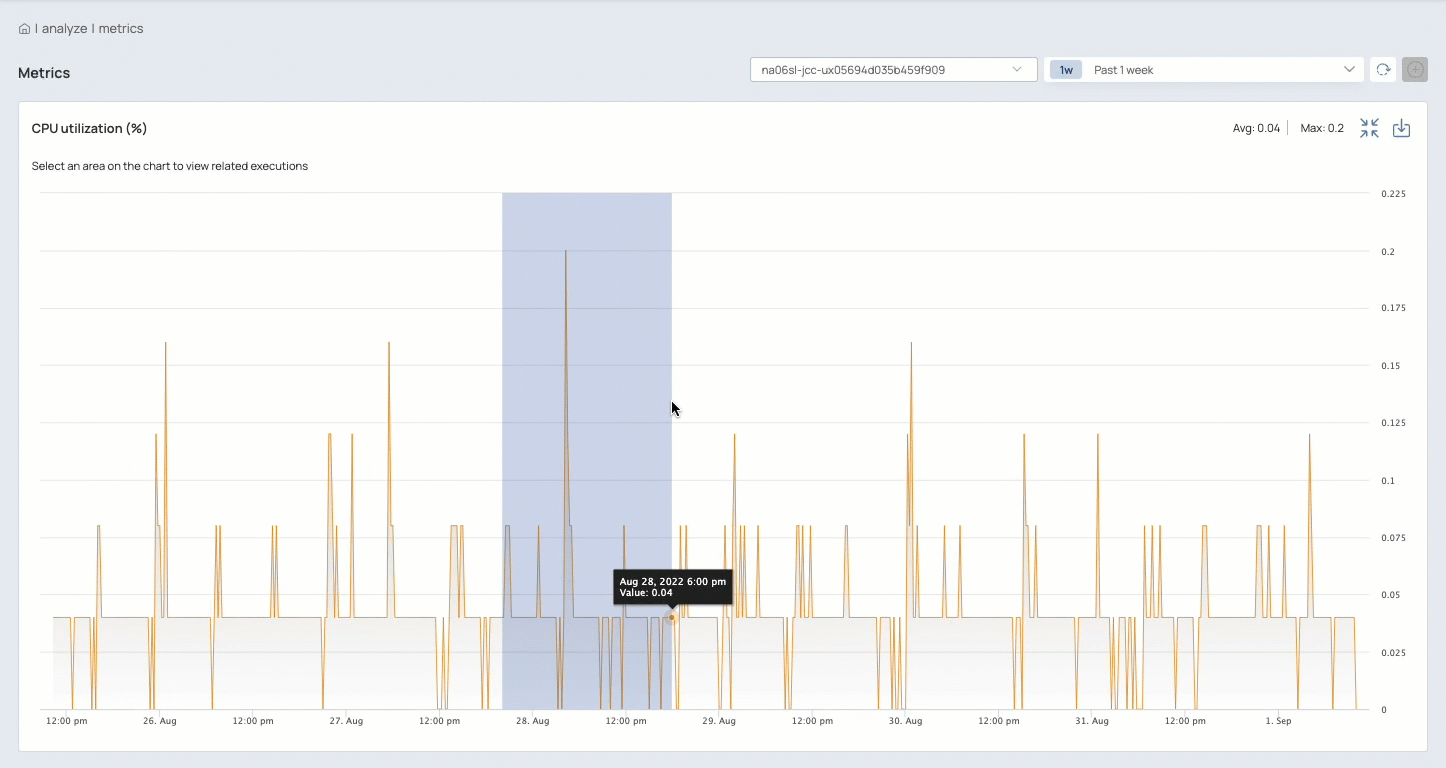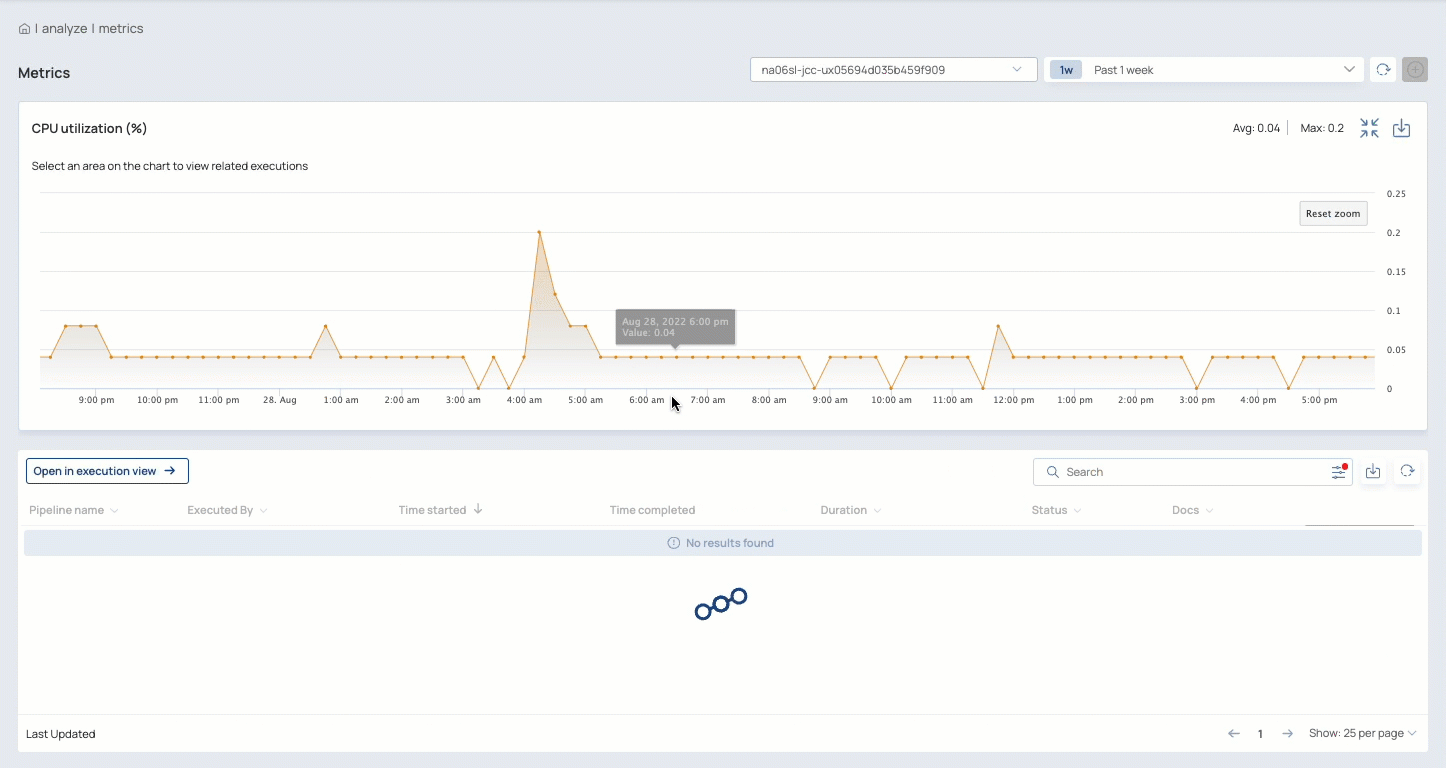
Charts on the Metrics page show trends in runtime behavior for a Snaplex node:
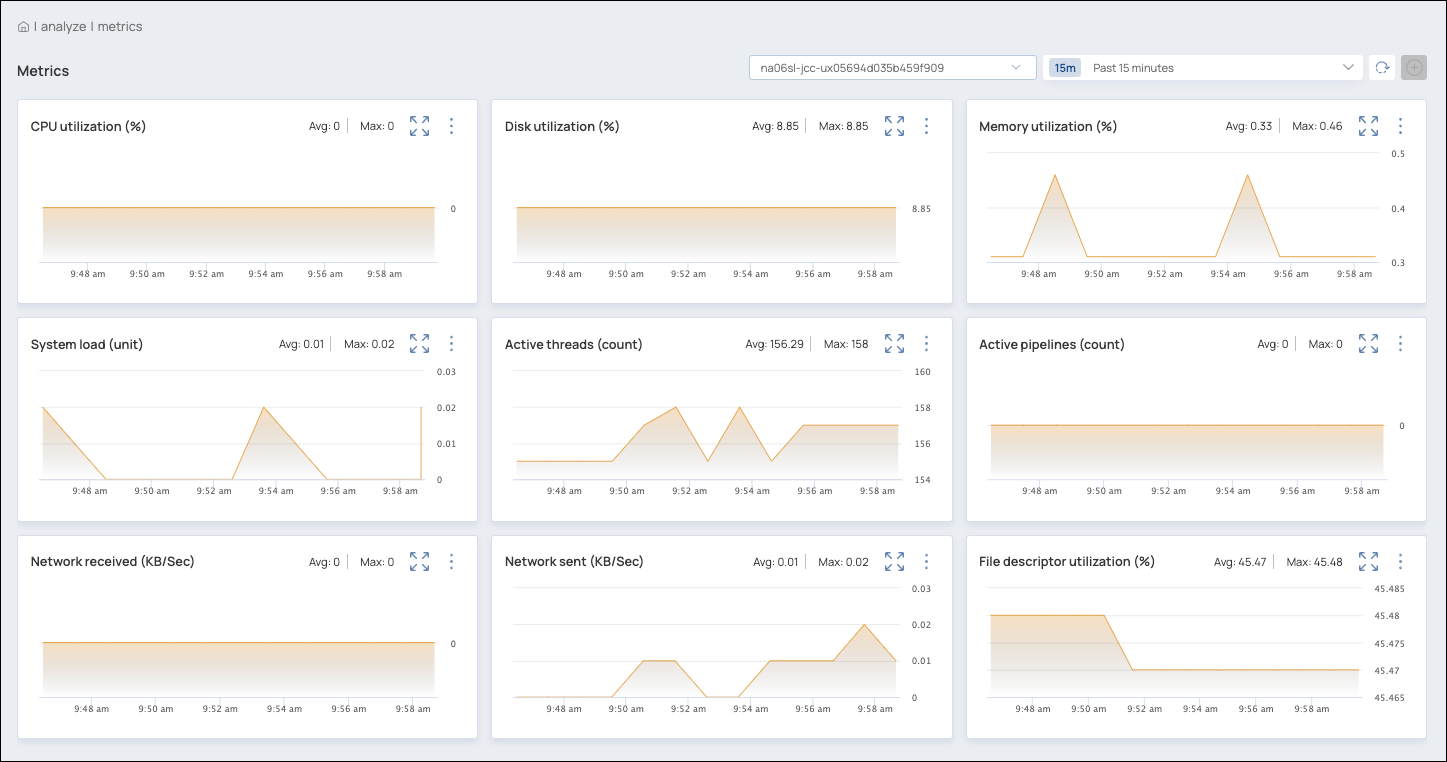
Use the Metrics page to:
Analyze the behavior of a Snaplex node
Improve Task scheduling by finding under-utilized and over-utilized time periods
Troubleshoot performance issues by identifying usage spikes
View trends and individual data points
Zoom in on charts to focus on a shorter time period:
Expand a chart to determine which Pipelines ran during a specific time period and view the execution details
Review Snap statistics, Pipeline logs, and Pipeline parameters
Download files reporting:
Chart values
Logs
Runtime details
Patterns Catalog
The following Patterns were added to the Studio Pattern Catalog:
File Transfer Between Two File Sharing Systems
Read Data From Salesforce and Write to SQS Producer
Read File From SnapLogic Database, Transform Data in Workday and Load to SQL Server
Read and Transform Data From Salesforce to Load in NetSuite and Reltio
Read and Write to Azure Blob Storage
Record Box files to Google Sheets
Record new CSV file in Box to Google Sheets
Regex Primer Pattern
Salesforce Accounts to Workday Organization
Salesforce Attachment to Box
Salesforce Case to ServiceNow Case
Tableau Ingest From Salesforce
Tableau Ingest From Workday
Upload Gmail Attachments to Box
Workday Action Based Write
Platform
The SnapLogic platform is live on Cloudflare as of . When launched, the SnapLogic UI automatically redirects to the specific Cloudflare CDN addresses. This change enhances the SnapLogic platform’s response time, security, and performance. To ensure continued access to the SnapLogic UI, only customers who restrict outbound IP addresses to a predefined list of IP addresses must extend their allowlist to add all the specific IP addresses. Learn more to understand how this impacts your organization.
You access the print functionality from the Export button on the Designer toolbar. When you print, an error can occur where a blank page displays instead of the Pipeline. No other values are displayed. If this happens, initiate the print again.
Enhancements
The storage capacity for Snaplexes managed by SnapLogic (also known as Cloudplexes) is increased to:
Extra-large node: 275 GB
Double extra-large node: 375 GB
Learn more about node sizing for Snaplexes managed by SnapLogic.
Fixed Issues
The following fixes apply to the SnapLogic Git Integration:
When checking out repositories, users will not see repositories they do not have permission to access.
You can rename a branch without deauthorizing the SnapLogic GitHub App.
API Management
Enhancements
Move the Assets in your API Versions from one version to another version. You can specify assets to move from one version to another version or a version of another API. You can also move assets from Projects in Manager to API versions.
Select the specific assets you want to include when you create an API from existing SnapLogic assets.
Known Issues
When you create an API or API version using the Design First method, any parameter in the specification with a default value that is not a string results in a bad request error.
Documentation Updates
Learn about the UAT process for testing features available in the latest SnapLogic release.
View the planned SnapLogic release dates for the remainder of 2022.