Teradata Execute
- Kalpana Malladi
- Aparna Tayi (Unlicensed)
- Gouri Bhagchandani (Deactivated)
In this article
Snap type | Write | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
Description | This Snap allows you to execute a Teradata statement/query. This Snap works only with single queries. You can drop your database with it, so be cautious. Valid JSON paths that are defined in the where clause for queries/statements will be substituted with values from an incoming document. Documents will be written to the error view if the document is missing a value to be substituted into the query/statement. If a select query is executed, the query's results are merged into the incoming document and any existing keys will have their values overwritten. On the other hand, the original document is written if there are no results from the query. The Teradata Execute Snap is for simple DML (SELECT, INSERT, UPDATE, DELETE) type statements. | ||||||||||
| Prerequisites | None | ||||||||||
| Support and limitations | Works in Ultra Tasks. | ||||||||||
| Behavior Change |
If you have any existing Pipelines that are mapped with status key or previous description then those Pipelines will fail. So, you might need to revisit your Pipeline design. | ||||||||||
| Account | This Snap uses account references created on the Accounts page of SnapLogic Manager to handle access to this endpoint. See Configuring Teradata Database Accounts for information on setting up this type of account. | ||||||||||
| Views |
| ||||||||||
Settings | |||||||||||
Label* | Specify the name for the Snap. You can modify this to be more specific, especially if you have more than one of the same Snap in your Pipeline. Default Value: Teradata Execute | ||||||||||
SQL statement* | Specify the SQL statement to execute on the server. There are two possible scenarios that you encounter when working with SQL statements in SnapLogic. You must understand the following scenarios to successfully execute your SQL statements: Scenarios to successfully execute your SQL statements Scenario 1: Executing SQL statements without expressions
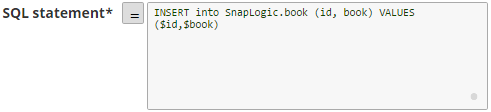
For example:
Additionally, the JSON path is allowed only in the WHERE clause. If the SQL statement starts with SELECT (case-insensitive), the Snap regards it as a select-type query and executes once per input document. If not, it regards it as write-type query and executes in batch mode. Scenario 2: Executing SQL queries with expressions
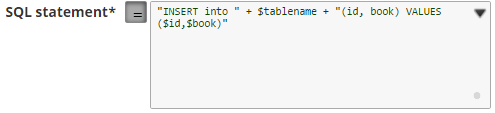
Table name and column names must not be provided as bind parameters. Only values can be provided as bind parameters. For example:
We recommend you to add a single query in the SQL Statement field.
Single quotes in values must be escaped Any relational database (RDBMS) treats single quotes ( For example:
Default Value: [None] | ||||||||||
| Query type | Select the type of query for your SQL statement (Read or Write). When Auto is selected, the Snap tries to determine the query type automatically. Default Value: Auto | ||||||||||
| Query band | Specify the name-value pairs to use in the session's generated query band statement. The query band is passed to the Teradata database as a list of name-value pairs separated by semi-colons. Default Value: N/A | ||||||||||
Pass through | Select this checkbox to pass the input document to the output view under the key 'original'. This property applies only to the Execute Snaps with SELECT statement. Default Value: Selected | ||||||||||
Ignore empty result | Select this checkbox to ignore empty result; no document will be written to the output view when a SELECT operation does not produce any result. Default Value: Not selected | ||||||||||
Number of retries | Specify the maximum number of reconnection attempts that the Snap must perform, in case of connection failure or timeout. Default Value: 0 | ||||||||||
Retry interval (seconds) | Enter in seconds the duration for which the Snap must wait between two reconnection attempts, until the number of retries is reached. Default Value: 1 | ||||||||||
Auto commit | Select one of the options for this property to override the state of the Auto commit property on the account. The Auto commit at the Snap-level has three values: True, False, and Use account setting. The expected functionality for these modes are:
Default Value: Use account setting 'Auto commit' may be enabled for certain use cases if PostgreSQL jdbc driver is used in either Redshift, PostgreSQL or generic JDBC Snap. But the JDBC driver may cause out of memory issues when Select statements are executed. In those cases, “Auto commit" in Snap property should be set to ‘False’ and the Fetch size in the “Account setting" can be increased for optimal performance. Behavior of DML Queries in Database Execute Snap when auto-commit is false DDL queries used in the Database Execute Snap will be committed by the Database itself, regardless of the Auto-commit setting. When Auto commit is set to false for the DML queries, the commit is called at the end of the Snap's execution. The Auto commit needs to be true in a scenario where the downstream Snap does depend on the data processed on an Upstream Database Execute Snap containing a DML query. When the Auto commit is set to the Use account setting on the Snap, the account level commit needs to be enabled. | ||||||||||
| Advanced options | Select the option ‘Timestamp with microsecond precision’ to support the microsecond precision for TIMESTAMP data type. The SELECT query for TIMESTAMP columns produces string values with microsecond precision in the output documents. Default Value: None | ||||||||||
Snap execution | Select one of the three modes in which the Snap executes. Available options are:
| ||||||||||
Troubleshooting
| Error | Reason | Resolution |
|---|---|---|
| A syntax error was found in the QUERY_BAND. | Check that the query band is in the form specified in the Query band field above. For example, if you used |
Example
In this example, we shall execute various commands using the Teradata Execute Snap. This pipeline creates a table, inserts the data into the table and reads the data using the respective execute commands (CREATE, INSERT and SELECT).
.png?version=1&modificationDate=1489644645122&cacheVersion=1&api=v2)
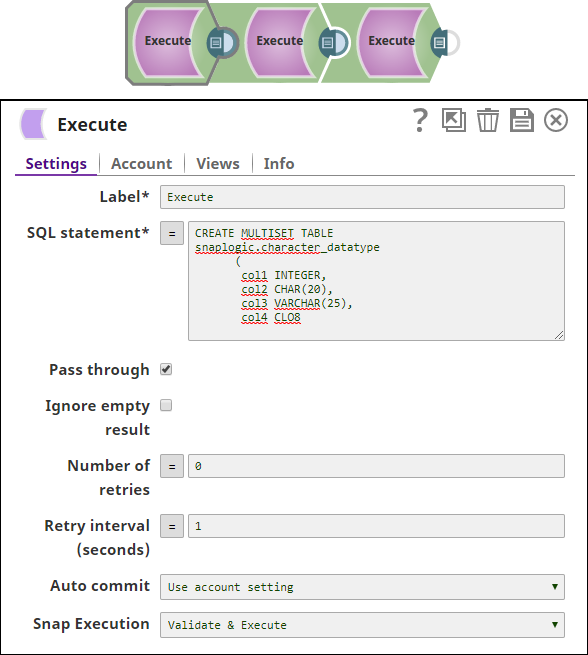
1. Create a table, Snaplogic.character_datatype under the schema name Snaplogic. The table has 4 columns: INTEGER, CHAR, VARCHAR and CLOB .
2. Insert the required data into the table Snaplogic.character_datatype using the Teradata Execute Snap.
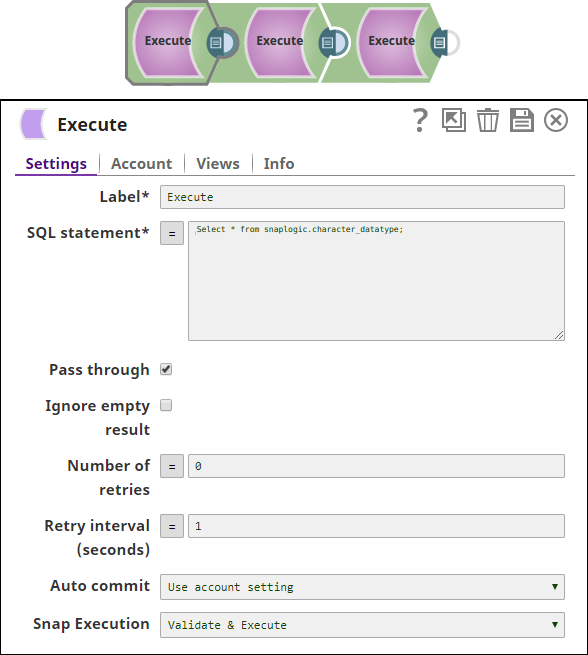
3. We use the Teradata Execute Snap again and select the data from the table Snaplogic.character_datatype1 using the SELECT command.
Successful execution of the Pipeline displays the following preview:
.png?version=1&modificationDate=1489644905603&cacheVersion=1&api=v2&width=1000&height=505)
Snap Pack History
Have feedback? Email documentation@snaplogic.com | Ask a question in the SnapLogic Community
© 2017-2025 SnapLogic, Inc.