Atlassian uses cookies to improve your browsing experience, perform analytics and research, and conduct advertising. Accept all cookies to indicate that you agree to our use of cookies on your device. Atlassian cookies and tracking notice, (opens new window)
MySQL account settings have been shared across different MySQL Snaps and the batch size settings varies the performance for some of the Snaps. We recommend changing the batch size setting (within the account details) to 100k or 200k for only the MySQL Bulk Load Snap (these batch size settings for bulk load may vary based on the environment settings but this range should be ideal).
If you are using other MySQL Snaps along with MySQL Bulk Load Snap in the same pipeline, then use different accounts for each of these Snaps and increase the batch size setting for MySQL Bulk Load Snap (within the account details) as mentioned above.
The bulk load feature is disabled by default for MySQL 8.0 and higher versions. To use the MySQL Bulk Load Snap with MySQL v8 and higher, enable the server and the Snap as a client of the Bulk Load feature in the JDBC driver.
To enable the bulk load feature in the JDBC driver, perform the following actions:
In MySQL v8 or higher, add the following lines to my.cnf file and restart the server. [mysqld] local_infile=ON
If the my.cnf file does not exist, create one in the main directory of the server.
In MySQL Bulk Load Snap (r4.19 or later), add the following entry to the Url properties field in the associated MySQL account.
allowLoadLocalInfile = true
Snap type:
Write
Description:
Snap executes MySQL bulk load. This Snap uses the LOAD DATA INFILE statement internally to perform the bulk load action. The file is first copied to JCC node, then to MySQL server under tmp directory and finally to the target MySQL table.
Ensure sufficient space in the JCC and MySQL tmp location.
Table Creation
If the table does not exist when the Snap tries to do the load, and the Create table property is set, the table will be created with the columns and data types required to hold the values in the first input document. If you would like the table to be created with the same schema as a source table, you can connect the second output view of a Select Snap to the second input view of this Snap. The extra view in the Select and Bulk Load Snaps are used to pass metadata about the table, effectively allowing you to replicate a table from one database to another.
The table metadata document that is read in by the second input view contains a dump of the JDBC DatabaseMetaData class. The document can be manipulated to affect the CREATE TABLE statement that is generated by this Snap. For example, to rename the name column to full_name, you can use a Mapper (Data) Snap that sets the path $.columns.name.COLUMN_NAME to full_name. The document contains the following fields:
columns - Contains the result of the getColumns() method with each column as a separate field in the object. Changing the COLUMN_NAME value will change the name of the column in the created table. Note that if you change a column name, you do not need to change the name of the field in the row input documents. The Snap will automatically translate from the original name to the new name. For example, when changing from name to full_name, the name field in the input document will be put into the "full_name" column. You can also drop a column by setting the COLUMN_NAME value to null or the empty string. The other fields of interest in the column definition are:
TYPE_NAME - The type to use for the column. If this type is not known to the database, the DATA_TYPE field will be used as a fallback. If you want to explicitly set a type for a column, set the DATA_TYPE field.
_SL_PRECISION - Contains the result of the getPrecision() method. This field is used along with the _SL_SCALE field for setting the precision and scale of a DECIMAL or NUMERIC field.
_SL_SCALE - Contains the result of the getScale() method. This field is used along with the _SL_PRECISION field for setting the precision and scale of a DECIMAL or NUMERIC field.
primaryKeyColumns - Contains the result of the getPrimaryKeys() method with each column as a separate field in the object.
declaration - Contains the result of the getTables() method for this table. The values in this object are just informational at the moment. The target table name is taken from the Snap property.
importedKeys - Contains the foreign key information from the getImportedKeys() method. The generated CREATE TABLE statement will include FOREIGN KEY constraints based on the contents of this object. Note that you will need to change the PKTABLE_NAME value if you changed the name of the referenced table when replicating it.
indexInfo - Contains the result of the getIndexInfo() method for this table with each index as a separated field in the object. Any UNIQUE indexes in here will be included in the CREATE TABLE statement generated by this Snap.
The Snap will not automatically fix some errors encountered during table creation since they may require user intervention to resolve correctly. For example, if the source table contains a column with a type that does not have a direct mapping in the target database, the Snap will fail to execute. You will then need to add a Mapper (Data) Snap to change the metadata document to explicitly set the values needed to produce a valid CREATE TABLE statement.
Table definition has changed, please retry transaction.
This happens due to a known issue in the MySql Connector. For more information about this issue, see MySQL Bug #65378.
Account:
This Snap uses account references created on the Accounts page of SnapLogic Manager to handle access to this endpoint. See MySQL Account for information on setting up this type of account.
MySQL account settings have been shared across different MySQL Snaps and the batch size settings varies the performance for some of the Snaps. We recommend changing the batch size setting (within the account details) to 100k or 200k for only the MySQL Bulk Load Snap (these batch size settings for bulk load may vary based on the environment settings but this range should be ideal).
If you are using other MySQL Snaps along with MySQL Bulk Load Snap in the same pipeline, then use different accounts for each of these Snaps and increase the batch size setting for MySQL Bulk Load Snap (within the account details) as mentioned above.
Views:
Input
This Snap has one document input view by default.
A second view can be added for metadata for the table as a document so that the target absent table can be created in the MySQL database with a similar schema as the source table. This schema is usually from the second output of a database Select Snap. If the schema is from a different database, there is no guarantee that all the data types would be properly handled.
Output
This Snap has at most one document output view.
Error
This Snap has at most one document error view and produces zero or more documents in the view.
Settings
Label
Required. The name for the Snap. You can modify this to be more specific, especially if you have more than one of the same Snap in your pipeline.
Schema name
The database schema name. In case it is not defined, then the suggestion for the Table name will retrieve all tables names of all schemas. The property is suggestible and will retrieve available database schemas during suggest values.
The values can be passed using the pipeline parameters but not the upstream parameter.
Example: SYS Default value: [None]
Table name
Required. Table on which to execute the bulk load operation.
The values can be passed using the pipeline parameters but not the upstream parameter.
Example: people Default value: [None]
Create table if not present
Whether the table should be automatically created if it is not already present.
Default value: Not selected
Partitions
This is used to specify a list of one or more partitions and/or subpartitions. When used, if any input document cannot be inserted into any of the partitions or subpartitions named in the list, the input document will be ignored.
Default value: Not selected
Columns
When no column list is provided, input documents are expected to contain a field for each table column. When a column list is provided, the Snap will load only the specified columns. Default value: Not selected
Set Clause
Required. This is used to assign values to columns. For example, you can use "COLUMN1 = 1" to insert integer 1 to column COLUMN1 for each input document. See this link for more information.
Default value: [None]
On duplicates
Required. Specifies the action to be performed when duplicate records are found. In other words, rows that have the same value for a primary key or unique index as an existing row. If you choose REPLACE, input rows replace the existing rows. If you choose IGNORE, input rows are ignored.
Default value: IGNORE
Concurrency Option
Specifies how to handle the load process when other clients are reading from the table.
Available concurrency options are:
LOW_PRIORITY - If this option is selected, the loading process is delayed until no other clients are reading from the table. This affects only storage engines that use only table-level locking (such as MyISAM, MEMORY, and MERGE).
CONCURRENT - If this option is used with a MyISAM table that satisfies the condition for concurrent inserts (that is, it contains no free blocks in the middle), other threads can retrieve data from the table while MySQL Bulk Load Snap is executing. This affects the performance of the MySQL Bulk Load Snap a bit, even if no other thread is using the table at the same time.
Default value: None
Character Set
The MySQL server uses the character set indicated by the character_set_database system variable to interpret the information in the inputs. If the contents of the inputs use a character set that differs from the default, it is recommended that you specify the character set of the inputs with this property. A character set of binary specifies "no conversion".
It is not possible to load data that uses the ucs2, utf16, utf16le, or utf32 character set.
Default: [None]
Chunk size
Specifies the number of records to be loaded at a time.
Note: This property will override the "Batch size" property of the account
Default: 100000
Snap execution
Select one of the three modes in which the Snap executes. Available options are:
Validate & Execute: Performs limited execution of the Snap, and generates a data preview during Pipeline validation. Subsequently, performs full execution of the Snap (unlimited records) during Pipeline runtime.
Execute only: Performs full execution of the Snap during Pipeline execution without generating preview data.
Disabled: Disables the Snap and all Snaps that are downstream from it.
When invalid data is passed to the Snap, the Snap execution fails. The database administrator can set a global variable that can either handle an invalid case by passing a default value (such as, if strings are passed for integers, then pass the value 0) , or by displaying an error. See Load Data Syntax for more information.
In a scenario where the Auto commit on the account is set to true, and the downstream Snap does depends on the data processed on an Upstream Database Bulk Load Snap, use the Script Snap to add delay for the data to be available.
For example, when performing a create, insert and a delete function sequentially on a pipeline, using a Script Snap helps in creating a delay between the insert and delete function or otherwise it may turn out that the delete function is triggered even before inserting the records on the table.
Example
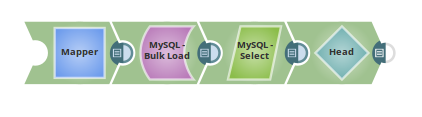
The following example illustrates the usage of the MySQL Bulk Load Snap. In this pipeline, we map the data using the Mapper Snap, insert it into the target table using the MySQL Bulkload Snap, read the data using the MySQL Select Snap and additionally sending the first document to the output view using the Head Snap.
The pipeline:
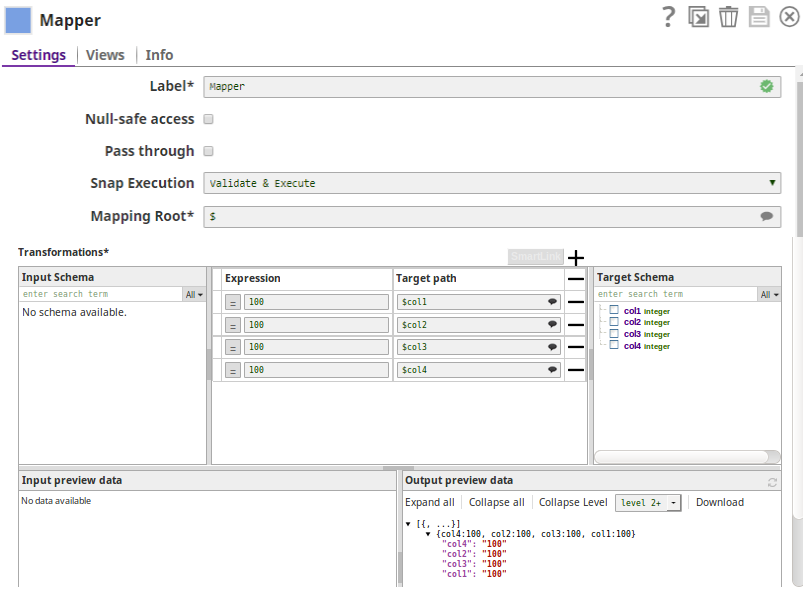
1. The mapper Snap maps the data and writes the result to the target path, enron numeric_table.
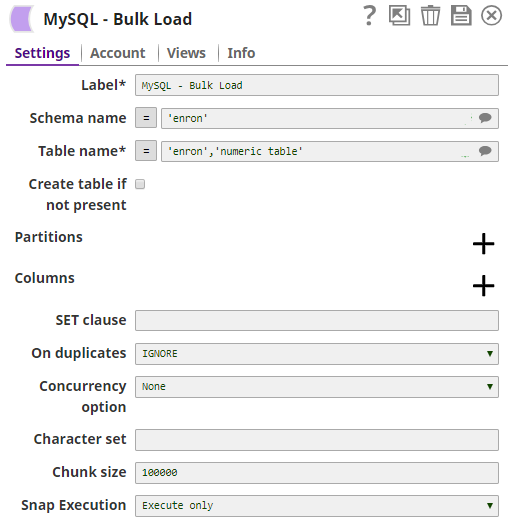
2. The MySQL Bulk Load Snap loads inputs to the table,enron numeric_table.
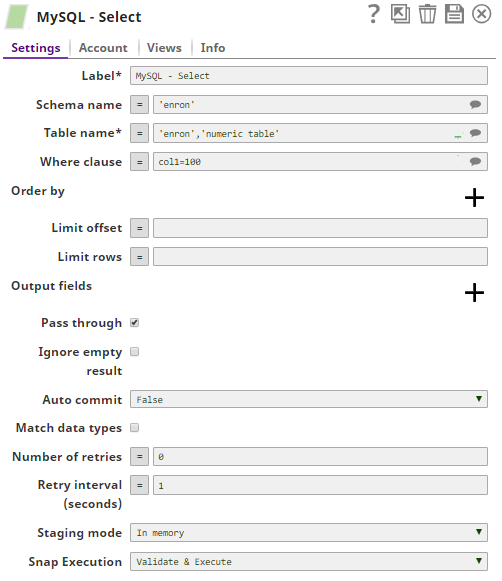
3. The MySQL Select Snap gets records from the table,enron numeric_table where the clause is col1= 100.
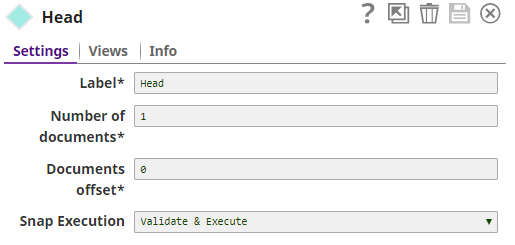
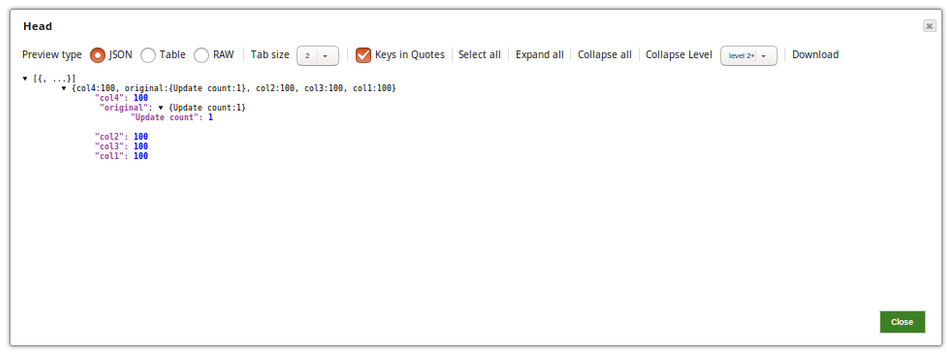
4. The Head Snap is set to1, meaning it would send the first document to the output view, and hence the MySQL Select Snap passes the first document only.
Successful execution of the pipeline gives the following output preview.
Snap Pack History
Click to view/expand
Release
Snap Pack Version
Date
Type
Updates
February 2025
main29887
Stable
Updated and certified against the current SnapLogic Platform release.
November 2024
main29029
Stable
Updated and certified against the current SnapLogic Platform release.
August 2024
main27765
Stable
Updated and certified against the current Snaplogic Platform release.
May 2024
437patches26298
Latest
Fixed an issue with the MySQL - Multi Execute Snap and the MySQL - Execute Snaps that displayed a null pointer exception when the Snap did not check nulltable metadata.
May 2024
main26341
Stable
Updated the Delete Condition (Truncates a Table if empty) field in the MySQL - DeleteSnap to Delete condition (deletes all records from a table if left blank) to indicate that all entries will be deleted from the table when this field is blank, but no truncate operation is performed.
February 2024
436patches25659
Latest
Fixed an issue with the MySQL- Multi Execute Snap that committed the changes when the Snap was expected to roll back if any query failed and the Number of Retries was more than 0. The Snap now performs a rollback when one or more queries fail.
Fixed an issue with the MySQL-Insert Snap that displayed an error when you inserted values such as 128 or morein the Tinyint unsigned datatype when the datatype must accept all the values in the range of 0-255.
Fixed an issue with MySQL-Insert Snap that failed to store the Time datatype with precision in the target table when passed from an upstream Mapper Snap in the stringformat or Date-only date format.
February 2024
main25112
Stable
Updated and certified against the current SnapLogic Platform release.
November 2023
main23721
Stable
Updated and certified against the current SnapLogic Platform release.
August 2023
main22460
Stable
The MySQL - Execute Snap now includes a new Query type field. When Auto is selected, the Snap tries to determine the query type automatically.
May 2023
main21015
Stable
Upgraded with the latest SnapLogic Platform release.
February 2023
432patches19870
Latest
Fixed an issue with the preview data of the MySQL-Execute Snap that displayed the date format as %m %d %Y (without the forward slash '/'). The Snap now displays the date as intended in %m/%d/%Y format after validation.
February 2023
main19844
Stable
Upgraded with the latest SnapLogic Platform release.
November 2022
431patches19263
Latest
The MySQL Insert Snap no longer includes the Preserve case-sensitivitycheckboxbecause the database is case-insensitive. The database stores the data regardless of whether the columns in the target table and the input data are in mixed, lower, or upper case.
November 2022
main18944
Stable
The MySQL - Insert Snap now creates the target table only from the table metadata of the second input view when the following conditions are met:
The Create table if not present checkbox is selected.
The target table does not exist.
The table metadata is provided in the second input view.
September 2022
430patches17894
Latest
The MySQL Select Snap now work as expected when the table name is dependent on an upstream input;
Writing the first batch of records to a temporary file after the Snap fails. Now the Snap writes to the error view as is the expected behavior.
Temporary files generation when a record does not contain a table column. Now, the Snaplex removes the temporary files created along with the directory after the Pipeline execution.
August 2022
main17386
Stable
Upgraded with the latest SnapLogic Platform release.
4.29
main15993
Stable
Upgraded with the latest SnapLogic Platform release.
4.28 Patch
428patches15101
Latest
Fixed an issue with SQL Server - Execute Snap where the Pipeline was failing when there were consecutive execute Snaps with a procedure call, followed by select statements.
4.28
main14627
Stable
Updated the label for Delete Condition to Delete Condition (Truncates Table if empty) in the MySQL DeleteSnap.
4.27
main12833
Stable
Enhanced the MySQL Database Accountto skip batch execution, when the Batch size value is one. When the Batch size is greater than one, the batch is executed.
Enhanced the MySQL - Execute Snap to invoke stored procedures.
4.26
main11181
Stable
Upgraded with the latest SnapLogic Platform release.
4.25
425patches11008
Latest
Enhanced the MySQL - Lookup Snap suggestions to load the Output Fields and Lookup Column settings.
Fixed an issue with MySQL - Select Snap where the second output view of the Snap was showing empty column values and improved the error messages in the Snap where the Snap fails with Null Pointer Exception when the account reference provided is invalid.
4.25
main9554
Stable
Upgraded with the latest SnapLogic Platform release.
4.24
main8556
Stable
Enhances the MySQL - Select Snap to return only the fields (provided in the Output Fields) in the output schema (second output view), through a new check box Fetch Output Fields InSchema. If the Output Fields property is empty all the columns are visible.
Enhances the MySQL - Stored Procedure to accept parameters from input documents by column keys. If the values are empty, the parameters are populated based on the column keys for easier mapping in the upstream Mapper Snap.
4.23 Patch
423patches7732
Latest
Fixes an issue in the MySQL - Bulk LoadSnap to support the following versions:
MySQL 8.0.17
MySQL 5.6.34
4.23
main7430
Stable
Upgraded with the latest SnapLogic Platform release.
4.22 Patch
422patches6629
Latest
Fixes the MySQLSnap Pack by acknowledging the lineage information of the original document in an empty output view whenPass Throughis enabled.
4.22
main6403
Stable
Upgraded with the latest SnapLogic Platform release.
4.21 Patch
421patches6272
Latest
Fixes the issue whereSnowflake SCD2Snap generates two output documents despite no changes toCause-historizationfieldswithDATE, TIME and TIMESTAMPSnowflake data types, and withIgnore unchanged rowsfield selected.
4.21 Patch
421patches6144
Latest
Fixes the following issues with DB Snaps:
The connection thread waits indefinitely causing the subsequent connection requests to become unresponsive.
Connection leaks occur during Pipeline execution.
4.21 Patch
mysql8842
Latest
Fixes the SSH tunneling issue by ensuring connectivity between JCC and MySQL server.
Updates the UI for MySQL Accounts to simplify the SSH tunneling configuration as described inConfiguring MySQL Accounts.
4.21 Patch
MULTIPLE8841
Latest
Fixes the connection issue in Database Snaps by detecting and closing open connections after the Snap execution ends.
4.21
snapsmrc542
Stable
Upgraded with the latest SnapLogic Platform release.
4.20 Patch
db/mysql8815
Latest
Fixes the MySQL Stored Procedure Snap to resolve compatibility issues with the Amazon Aurora database.
4.20 Patch
db/mysql8786
Latest
Fixes the MySQL - Bulk Load Snap to use the UTF-8 character set for writing temporary files in order to successfully handle special characters, irrespective of the value specified in the Character set field in the Snap settings.
4.20
snapsmrc535
Stable
Upgraded with the latest SnapLogic Platform release.
4.19 Patch
db/mysql8638
Latest
Fixes the MySQL Database Account where the associated Snaps produce a huge count of open file descriptors when theConfigure SSH Tunnelproperty is enabled.
4.19 Patch
db/mysql8635
Latest
Fixes the MySQL - Execute Snap where the retry option fails to establish a connection with the MySQL database, after an interrupted transmission.
4.19 Patch
db/mysql8407
Latest
Fixes an issue with the MySQL - Update Snap wherein the Snap is unable to perform operations when:
An expression is used in theUpdate conditionproperty.
Input data contain the character '?'.
4.19 Patch
db/mysql8390
Latest
Fixes an issue wherein the MySQL Snaps are unable to reconnect to the MySQL database after the breakdown of a connection.
4.19 Patch
db/mysql8340
Latest
Fixes an issue with the MySQL Bulk Load Snap wherein the Snap is unable to execute the bulk load feature with MySQL 8.0 and higher versions.
4.19
snaprsmrc528
Stable
Upgraded with the latest SnapLogic Platform release.
4.18 Patch
db/mysql7846
Latest
Fixed an issue with the MySQL Snaps wherein the Snaps exhibit degraded performance with snapsmrc523.
4.18
snapsmrc523
Stable
Reverted a 4.17-patch(db/mysql7395)update regarding how BIT and BOOLEAN column data type values are displayed. They now display as true or false (4.17GA behavior insnapsmrc515) rather than converting to 0 or 1 values (4.17-patch behavior).
4.17 Patch
db/mysql7395
Latest
Fixed an issue wherein bit data types in the MySQL - Select table convert to true or false instead of 0 or 1.
4.17 Patch
db/mysql7357
Latest
Fixed an issue with the MySQL Execute snap wherein the Retry property for connection fails after the database connection is severed.
4.17
ALL7402
Latest
Pushed automatic rebuild of the latest version of each Snap Pack to SnapLogic UAT and Elastic servers.
4.17
snapsmrc515
Latest
Fixed an issue with the MySQL Execute Snap wherein the Snap would send the input document to the output view even if the Pass through field is not selected in the Snap configuration. With this fix, the Snap sends the input document to the output view, under the key original, only if you select the Pass through field.
Added the Snap Execution field to all Standard-mode Snaps. In some Snaps, this field replaces the existing Execute during preview check box.
4.16 Patch
MULTIPLE7123
Latest
Added two new properties, Number of retries and Retry interval, to Delete, Insert, Select, Execute, Merge, Update, and MutliExecute Snaps that enables you to handle retry attempts during a connection failure.
4.16 Patch
db/mysql6823
Latest
Fixed an issue with the Lookup Snap passing data simultaneously to output and error views when some values contained spaces at the end.
4.16
snapsmrc508
Stable
Upgraded with the latest SnapLogic Platform release.
4.15 Patch
MULTIPLE6413
Latest
Added 2 new properties, JDBC Driver Class and JDBC JARs. The new properties enable uploading JDBC JARs that help connect to MYSQL8.
4.15 Patch
db/mysql6332
Latest
ReplacedMax idle timeandIdle connection testperiodproperties withMax life timeandIdle Timeout properties respectively, in the Account configuration. The new properties fix the connection release issues that were occurring due to default/restricted DB Account settings.
4.15
snapsmrc500
Stable
Upgraded with the latest SnapLogic Platform release.
4.14
snapsmrc490
Stable
Upgraded with the latest SnapLogic Platform release.
4.13
snapsmrc486
Stable
Upgraded with the latest SnapLogic Platform release.
4.12 Patch
db/mysql4924
Latest
Fixed the MySQL Bulk Load Snap so that it doesn't produce an output document if there are no input documents.
4.12
snapsmrc480
Stable
Upgraded with the latest SnapLogic Platform release.
4.11
snapsmrc465
Stable
New! MySQL Stored Procedure Snap added to call/execute MySQL Stored Procedure.
SSH Tunnelling related properties added at the Account level for both MySQL Dynamic Account and MySQL Database Account.
4.10 Patch
mysql3988
Latest
SSH Tunnelling related properties added at the Account level for both MySQL Dynamic Account and MySQL Database Account.
4.10
snapsmrc414
Stable
AddedAuto commitproperty to the Select and Execute Snaps at the Snap level to support overriding of theAuto commitproperty at the Account level.
4.9.0 Patch
mysql3070
Latest
Fixed an issue regarding connection not closed after login failure; Expose autocommit for "Select into" statement in PostgreSQL Execute Snap and Redshift Execute Snap
4.9
snapsmrc405
Stable
Upgraded with the latest SnapLogic Platform release.
4.8.0 Patch
mysql2755
Latest
Potential fix for JDBC deadlock issue.
4.8.0 Patch
mysql2695
Latest
Addresses an issue where some changes made in the platform patch MRC294 to improve perfomance caused Snaps in the listed Snap Packs to fail.
4.8
snapsmrc398
Stable
Info tab added to accounts.
Database accounts now invalidate connection pools if account properties are modified and login attempts fail.
4.7.0 Patch
mysql2189
Latest
Fixed an issue for database Select Snaps regarding Limit rows not supporting an empty string from a pipeline parameter.
4.7.0 Patch
mysql2280
Latest
MySQL Merge will now route documents to the output and error views correctly
4.7
snapsmrc382
Stable
Added a new Snap, MySQL Bulk Load.
4.6
snapsmrc362
Stable
Enhanced MySQL Execute Snap to fully support SQL statements with/without expressions & SQL bind variables.
Extended support for MySQL Dynamic accounts.
Resolved an issue in MySQL Select Snap that caused failures in the second output view when retrieving outputs from a table with a dot (.) character.
Resolved an issue in MySQL Execute Snap that caused failures when passing expression ($variable_name) for stored procedures.
Resolved an issue in MySQL Execute Snap that caused failures when an SQL statement had an inline comment.
Resolved an issue in MySQL Execute Snap that ignored all statements after "–".
4.5.1
snapsmrc344
Stable
Fixed an error in a tooltip for MySQL - Select Snap.
4.5
snapsmrc344
Latest
Resolved an issue in MySQL Insert Snap to ensure an error is reported when table column is set to NOT NULL.
4.4.1
NA
Stable
Upgraded with the latest SnapLogic Platform release.
4.4
NA
Stable
Upgraded with the latest SnapLogic Platform release.
4.3.2
NA
Stable
NEW! MySQL Lookup Snap
Improved performance of the MySQL Execute Snap.
4.3
NA
NA
Stable
Table List Snap: A new option, Compute table graph, now lets you determine whether or not to generate dependents data into the output.
4.2.2
NA
NA
Stable
Ignore empty result added to Execute and Select Snaps. The option will not write any document to the output view for select statements producing no results.