This Snap executes a SQL Insert statement using the document's keys as the columns to insert to and the document's values as the values to insert into the columns.
Table Creation
If the table does not exist when the Snap tries to do the insert, and the Create table property is set, the table will be created with the columns and data types required to hold the values in the first input document. If you would like the table to be created with the same schema as a source table, you can connect the second output view of a Select Snap to the second input view of this Snap. The extra view in the Select and Bulk Load Snaps are used to pass metadata about the table, effectively allowing you to replicate a table from one database to another.
The table metadata document that is read in by the second input view contains a dump of the JDBC DatabaseMetaData class. The document can be manipulated to affect the CREATE TABLE statement that is generated by this Snap. For example, to rename the name column to full_name, you can use a Mapper (Data) Snap that sets the path $.columns.name.COLUMN_NAME to full_name. The document contains the following fields:
columns - Contains the result of the getColumns() method with each column as a separate field in the object. Changing the COLUMN_NAME value will change the name of the column in the created table. Note that if you change a column name, you do not need to change the name of the field in the row input documents. The Snap will automatically translate from the original name to the new name. For example, when changing from name tofull_name, the name field in the input document will be put into the "full_name" column. You can also drop a column by setting the COLUMN_NAME value to null or the empty string. The other fields of interest in the column definition are:
TYPE_NAME - The type to use for the column. If this type is not known to the database, the DATA_TYPE field will be used as a fallback. If you want to explicitly set a type for a column, set the DATA_TYPE field.
_SL_PRECISION - Contains the result of the getPrecision() method. This field is used along with the _SL_SCALE field for setting the precision and scale of a DECIMAL or NUMERIC field.
_SL_SCALE - Contains the result of the getScale() method. This field is used along with the _SL_PRECISION field for setting the precision and scale of a DECIMAL or NUMERIC field.
primaryKeyColumns - Contains the result of the getPrimaryKeys() method with each column as a separate field in the object.
declaration - Contains the result of the getTables() method for this table. The values in this object are just informational at the moment. The target table name is taken from the Snap property.
importedKeys - Contains the foreign key information from the getImportedKeys() method. The generated CREATETABLE statement will include FOREIGN KEY constraints based on the contents of this object. Note that you will need to change the PKTABLE_NAME value if you changed the name of the referenced table when replicating it.
indexInfo - Contains the result of the getIndexInfo() method for this table with each index as a separated field in the object. Any UNIQUE indexes in here will be included in the CREATE TABLE statement generated by this Snap.
If you create multiple tables with an overlapping column name, the data replication occurs in a different column having an unsuitable structure. It results in a value-exceeding-data-type-length error, causing failure to the Pipeline execution.
When such two tables are joined, the Snap renames one of the two columns names for smooth execution of the Pipeline.
Example:
A table named Owner has columns – firstname, lastname, ownerid; another table named Visit has columns – date and ownerid.
The column name ownerid is overlapping in both the tables.
As a fix, the Snap would name the columns as firstname, lastname, ownerid, date, visit.ownerid to join the two tables.
The Snap will not automatically fix errors encountered during table creation, since they may require user intervention to be resolved correctly. For example, if the source table contains a column with a type that does not have a direct mapping in the target database, the Snap will fail to execute. You will then need to add a Mapper (Data) Snap to change the metadata document to explicitly set the values needed to produce a valid CREATE TABLE statement.
Expected Input and Output
Expected upstream Snaps: Any Snap that provides a document output view, such as a Mapper or PostgreSQL Execute Snap.
Expected downstream Snaps:[None] or any Snap that has a document input view such as a Filter or a Data or a JSON Formatter.
Known Issue: If database metadata from an upstream Snap contains geography column data such as modifiers, those modifiers may not be written to the target table. Workaround:To write geographic data to the target table, create the table using the PostgreSQL - Execute Snap.
Account:
This Snap uses account references created on the Accounts page of SnapLogic Manager to handle access to this endpoint. See Configuring PostgreSQL Accounts for information on setting up this type of account.
Views:
Input
This Snap has one input view by default that accepts the rows to insert into the table. A second input view can be added that accepts the table metadata document from a database Select Snap. The table metadata will then be used to guide the creation of the table in the database.
Output
This Snap has at most one document output view.
Error
This Snap has at most one error view and produces zero or more documents in the view.
Database Write Snaps output all records of a batch (as configured in your account settings) to the error view if the write fails during batch processing.
Settings
Label*
Specify the name for the Snap. You can modify this to be more specific, especially if you have more than one of the same Snap in your pipeline.
Schema name
Specify the database schema name. Selecting a schema filters the Table name list to show only those tables within the selected schema.
The values can be passed using the pipeline parameters but not the upstream parameter.
Example: SYS
Table name*
Specify the table that the rows will be inserted into.
The values can be passed using the pipeline parameters but not the upstream parameter.
Example: users
You must check the datatype of each column in the table into which you want to insert the input data, and structure your data accordingly; else the endpoint generates an error. For example, if the column contact_id expects data in the UUID datatype, you must provide UUID data. For details on the UUID datatype, see The Basics of PostgreSQL UUID Data Type.
Create table if not present
Select this checkbox to automatically create the target table if it does not exist.
If a second input view is configured for the Snap and it contains a document with schema (metadata) from the source table, the Snap creates the new (target) table using the same schema (metadata). However, if the schema comes from a different database, the Snap might fail with the Unable to create table: "<table_name>" error due to data type incompatibility.
In the absence of a second input view, the Snap creates a table based on the data types of the columns generated from the first row of the input document (first input view).
Due to implementation details, a newly created table is not visible to subsequent database Snaps during runtime validation. If you want to immediately use the newly updated data you must use a child Pipeline that is invoked through a Pipeline Execute Snap.
If database metadata from an upstream Snap contains geography column data such as modifiers, those modifiers may not be written to the target table. For example, if the column metadata contains a polygon modifier, that modifier will not be written to the target table. Workaround: Create the table using the PostgreSQL - ExecuteSnap.
Default value: Not selected
Preserve case sensitivity
Select this checkbox to preserve the case sensitivity of the column names while performing the insert operation.
If you do not select this option, then Snap converts the column names in the input document to match the column names in the target database table before inserting the values. The Snap checks for the following three conditions:
If the column name in the table is in lower case, it modifies the column label to lower case.
If the column name in the table is in the upper case, it modifies the column label to upper case.
If the conditions mentioned above are not met, it takes the column label as is.
On the contrary, if you select this checkbox, the Snap does not convert the case of the column names and inserts the names as-is in the target database. Therefore, ensure that the column labels in the input document match the column labels in the target database table. Else, the Snap does not insert the values and displays an error. For example, if the column names (ID, Name) in the input document do not match the column names (Id, name) in the database, then the Snap does not insert the values and displays an error.
Number of retries
Specify the maximum number of attempts to be made to receive a response. The request is terminated if the attempts do not result in a response.
Default value: 0 Example: 3
Retry interval (seconds)
Specify the time interval between two successive retry requests. A retry happens only when the previous attempt resulted in an exception.
Default value: 1 Example: 10
Snap execution
Select one of the three modes in which the Snap executes. Available options are:
Validate & Execute: Performs limited execution of the Snap, and generates a data preview during Pipeline validation. Subsequently, performs full execution of the Snap (unlimited records) during Pipeline runtime.
Execute only: Performs full execution of the Snap during Pipeline execution without generating preview data.
Disabled: Disables the Snap and all Snaps that are downstream from it.
In a scenario where the Auto commit on the account is set to true, and the downstream Snap does depends on the data processed on an Upstream Database Bulk Load Snap, use the Script Snap to add delay for the data to be available.
For example, when performing a create, insert and a delete function sequentially on a pipeline, using a Script Snap helps in creating a delay between the insert and delete function or otherwise it may turn out that the delete function is triggered even before inserting the records on the table.
Snap Pack History
Click to view/expand
Release
Snap Pack Version
Date
Type
Updates
November 2024
439patches29250
Latest
Updated the tooltip for the Authentication Method dropdown field in the PostgreSQL and PostgreSQL Dynamic Accounts to enhance clarity and accuracy.
November 2024
main29029
Stable
Updated and certified against the current SnapLogic Platform release.
August 2024
main27765
Stable
Updated and certified against the current Snaplogic Platform release.
Upgraded the PostgreSQL JDBC driver from v9.4.1207 to v42.7.2 (Java 8). This upgrade will be part of the GA release on August 14, 2024 (Stable release). As part of this upgrade, the 42.7.2 JDBC driver is bundled with the PostgreSQL Snap Pack as the default JDBC driver. Your existing PostgreSQL pipelines that use the default driver (bundled with the PostgreSQL Snap Pack) might break.
Behavior change:
Thisdriver upgrade has resulted in specific behavior changes in errors, status codes, and success and failure messages.Learn more.
May 2024
437patches26634
Latest
Fixed an issue with PostgreSQL - ExecuteSnap that produced logs causing node crashes.
May 2024
4postgresupgrade26570
-
Upgraded the PostgreSQL JDBC driver from v9.4.1207 to v42.7.2 (Java 8). This upgrade will be part of the latest release on July 10,2024 and Stable release (GA) on August 14, 2024. As part of this upgrade, the 42.7.2 JDBC driver is bundled with the PostgreSQL Snap Pack as the default JDBC driver. Your existing PostgreSQL pipelines that use the default driver (bundled with the PostgreSQL Snap Pack) might break.
Behavior change:
This JDBC driver upgrade has resulted in specific behavior changes in errors, status codes, and success and failure messages. Learn more.
May 2024
main26341
Stable
Updated the Delete Condition (Truncates a Table if empty) field in the PostgreSQL - DeleteSnap to Delete condition (deletes all records from a table if left blank) to indicate that all entries will be deleted from the table when this field is blank, but no truncate operation is performed.
February 2024
main25112
Stable
Updated and certified against the current SnapLogic Platform release.
Updated and certified against the current SnapLogic Platform release.
August 2023
main22460
Stable
The PostgreSQL - Execute Snap now includes a new Query type field. When Auto is selected, the Snap tries to determine the query type automatically.
May 2023
433patches21298
Latest
Fixed an issue with the PostgreSQL Insert Snap that inconsistently inserted some columns and missed the remaining columns(especially the Time fields), when the data was passed in the JSON format from an upstream Snap.
May 2023
main21015
Stable
Upgraded with the latest SnapLogic Platform release.
February 2023
432patches20409
Latest
The PostgreSQL - Bulk Load and PostgreSQL - Insert Snaps no longer fail with the message ERROR: type modifier is not allowed for type 'bytea' when creating a new table if Create table if not present is selected and the target table does not exist. This issue occurred when metadata from the second input view document contained columns of the bytea data type.
February 2023
main19844
Stable
Upgraded with the latest SnapLogic Platform release.
November 2022
431patches19454
Latest
The PostgreSQLSnap Pack supports geospatial data types.
November 2022
main18944
Stable
The PostgreSQL - Bulk Load Snap can now process records with more than 16 KB in the document without encountering the BufferOverflowException because the default value of 16 KB for byte buffer size is now removed.
The PostgreSQL - Insert Snap now creates the target table only from the table metadata of the second input view when the following conditions are met:
The Create table if not present checkbox is selected.
The target table does not exist.
The table metadata is provided in the second input view.
The PostgreSQL Select Snap now works as expected when the table name is dependent on an upstream input.
August 2022
430patches17700
Latest
The PostgreSQL - Bulk Load Snap can now process the records with more than 16KB in the document without encountering BufferOverflowException because the default value of 16KB for byte buffer size is now removed.
August 2022
main17386
Stable
Enhanced the PostgreSQL Account and PostgreSQL Dynamic Account with SSH Tunneling configurations to encrypt the network connection between the client and the PostgreSQL Database server, thereby ensuring the secure network connection.
4.29 Patch
429patches17036
Latest
Enhanced the PostgreSQL Account and PostgreSQL Dynamic Account with SSH Tunneling configurations to encrypt the network connection between the client and the PostgreSQL Database server, thereby ensuring a secure network connection.
4.29
main15993
Stable
Upgraded with the latest SnapLogic Platform release.
4.28
main14627
Stable
Updated the label for Delete Condition to Delete Condition (Truncates Table if empty) in the PostgreSQL DeleteSnap.
4.27 Patch
427patches13149
Latest
Fixed an issue with PostgreSQL - Execute Snap, where the Snap failed when using Delete query with the RETURNING function.
Upgraded with the latest SnapLogic Platform release.
4.25 Patch
425patches9879
Latest
Enhanced the performance ofPostgreSQL - Bulk Load Snap significantly. SnapLogic anticipates that the Snap will execute up to 3 times faster than the previous version for enterprise workloads.
4.25
main9554
Stable
Upgraded with the latest SnapLogic Platform release.
4.24
main8556
Stable
Enhanced the PostgreSQL - SelectSnap to return only the selected output fields or columns in the output schema (second output view) using the Fetch Output Fields In Schema check box. If the Output Fields field is empty all the columns are visible.
4.23
main7430
Stable
Upgraded with the latest SnapLogic Platform release.
4.22 Patch
422patches6879
Latest
Fixed the PostgreSQL - Bulk Load Snap by preventing it from adding extra double quotes when loading values from input documents.
4.22
main6403
Stable
Upgraded with the latest SnapLogic Platform release.
4.21 Patch
421patches6272
Latest
Fixed the issue whereSnowflake SCD2Snap generates two output documents despite no changes toCause-historizationfieldswithDATE, TIME and TIMESTAMPSnowflake data types, and withIgnore unchanged rowsfield selected.
4.21 Patch
421patches6144
Latest
Fixed the following issues with DB Snaps:
The connection thread waits indefinitely causing the subsequent connection requests to become unresponsive.
Connection leaks occur during Pipeline execution.
4.21 Patch
MULTIPLE8841
Latest
Fixed the connection issue in Database Snaps by detecting and closing open connections after the Snap execution ends.
4.21
snapsmrc542
Stable
Upgraded with the latest SnapLogic Platform release.
4.20
snapsmrc535
Stable
Upgraded with the latest SnapLogic Platform release.
4.19 Patch
db/postgres8409
Latest
Fixed an issue with the PostgreSQL - Update Snap wherein the Snap is unable to perform operations when:
An expression is used in the Update condition property.
Input data contain the character '?'.
4.19
snaprsmrc528
Stable
Added new Snap PostgresSQL Bulk Load.
4.18 Patch
postgres8021
Latest
Fixed an issue with the PostgreSQL grammar to better handle the single quote characters.
4.18
snapsmrc523
Stable
Upgraded with the latest SnapLogic Platform release.
4.17 Patch
db/postgres7588
Latest
Fixed an issue with tables sharing an overlapping column name wherein Pipeline execution fails due to the table collision.
4.17
ALL7402
Latest
Pushed automatic rebuild of the latest version of each Snap Pack to SnapLogic UAT and Elastic servers.
4.17
snapsmrc515
Latest
Fixed an issue with the PostgreSQL Execute Snap wherein the Snap would send the input document to the output view even if the Pass through field is not selected in the Snap configuration. With this fix, the Snap sends the input document to the output view, under the key original, only if you select the Pass through field.
Added the Snap Execution field to all Standard-mode Snaps. In some Snaps, this field replaces the existing Execute during preview check box.
4.16 Patch
db/postgres6822
Latest
Fixed an issue with the Lookup Snap passing data simultaneously to output and error views when some values contained spaces at the end.
4.16
snapsmrc508
Stable
Upgraded with the latest SnapLogic Platform release.
4.15 Patch
db/postgres6333
Latest
Replaced Max idle time and Idle connection testperiod properties with Max life time and Idle Timeout properties respectively, in the Account configuration. The new properties fix the connection release issues that were occurring due to default/restricted DB Account settings.
4.15
snapsmrc500
Stable
Upgraded with the latest SnapLogic Platform release.
4.14
snapsmrc490
Stable
Added support for Amazon Aurora and Azure SQL DB.
4.13
snapsmrc486
Stable
Upgraded with the latest SnapLogic Platform release.
4.12 Patch
MULTIPLE4967
Latest
Provided an interim fix for an issue with the PostgreSQL 10 accounts by re-registering the driver for each account validation. The final fix is being shipped in a separate build.
4.12 Patch
postgres4832
Latest
Updated the driver from version 8.4.704 to version 9.4.1207 to support PostgreSQL v10 servers.
4.12
snapsmrc480
Stable
Upgraded with the latest SnapLogic Platform release.
4.11 Patch
db/postgres4290
Latest
PostgreSQL Snap Pack - Fixed an issue when inserting a valid NaN value into a column.
4.11
snapsmrc465
Stable
Upgraded with the latest SnapLogic Platform release.
4.10 Patch
postgres3773
Latest
Previously the Postgres PGObject datatype could not be serialized. It is now handled as a String.
4.10
snapsmrc414
Stable
AddedAuto commitproperty to the Select and Execute Snaps at the Snap level to support overriding of theAuto commitproperty at the Account level.
4.9.0 Patch
postgres3134
Latest
PostgreSQL Execute: New Snap advanced property Auto commit has been implemented to fix the Select query error in PostgreSQL replica servers.
4.9 Patch
postgres3072
Latest
Fixed an issue regarding connection not closed after login failure; Expose autocommit for "Select into" statement in PostgreSQL Execute Snap and Redshift Execute Snap.
4.9
snapsmrc405
Stable
Upgraded with the latest SnapLogic Platform release.
4.8.0 Patch
postgres2757
Latest
Potential fix for JDBC deadlock issue.
4.8.0 Patch
postgres2712
Latest
Fixed PostgreSQL Snap Pack rendering dates that are one hour off from the date returned by database query for non-UTC Snaplexes.
4.8.0 Patch
postgres2696
Latest
Addressed an issue where some changes made in the platform patch MRC294 to improve perfomance caused Snaps in the listed Snap Packs to fail.
4.8
snapsmrc398
Stable
Info tab added to accounts.
Database accounts now invalidate connection pools if account properties are modified and login attempts fail.
4.7.0 Patch
postgres2192
Latest
Fixed an issue for database Select Snaps regarding Limit rows not supporting an empty string from a pipeline parameter.
4.7.0 Patch
postgres2185
Latest
Resolved an issue with the PostgreSQL Execute Snap failing with a “java.util.regex.Pattern” error.
4.7
snapsmrc382
Stable
Upgraded with the latest SnapLogic Platform release.
4.6
snapsmrc362
Stable
Upgraded with the latest SnapLogic Platform release.
4.5.1
postgres1584
Stable
Resolved an issue in the PostgreSQL - Execute Snap that resulted from restrictions on the 'with' operator in conjunction with an 'insert' statement.
Resolved an issue in the PostgreSQL Snaps that resulting from restrictions on the 'with' operator in conjunction with the RECURSIVE keyword.
4.4.1
NA
Stable
Upgraded with the latest SnapLogic Platform release.
4.4
NA
Stable
Resolved an issue with PostgreSQL Select Snap not parsing JSON data type correctly.
Note: The fix for this issue required updating libraries that impacted all database Snaps except those for MongoDB.
4.3.2
NA
Stable
This Snap Pack is now compatible with the PostgreSQL drivers available in 4.3 Patch mrc222.
NA
NA
Stable
PostgreSQL Insert Snap: resolved an issue where it inserts a negative value when the input data was out of range.
PostgreSQL Snaps did not properly handle when a table name was created in mixed case.
JSON paths in WHERE clauses should be processed as bind values after the expression is evaluated.
NA
NA
Stable
A - otd:6828 Postgres Snap shows wrong data type in preview for timestamp withtime zone data type
Dynamic DB queries now supported in the Execute Snap.
The SQL statement property now can be set as an expression property. When it is an expression, it will be evaluated with each input document and one SQL statement per each input document will be executed.
Known issue: When the SQL statement property is an expression, the pipeline parameters are shown in the suggest, but not the input schema.
With the SQL statement property set as an expression, the Snap can be exposed to SQL injection. Please use this feature with caution.
NA
NA
Stable
PostgreSQL Insert: Enhanced data type support.
PostgreSQL Lookup: bug fixes on lookup failures; Pass-though on no lookup match property added to allow you to pass the input document through to the output view when there is no lookup matching.
PostgreSQL Select Snap: added support for handling array types.
Example
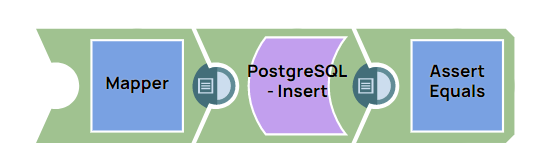
Inserting the Records Into an Existing Table in the Database
This example pipeline demonstrates how to insert the records into an existing table in the database using the PostgreSQL Insert Snap.
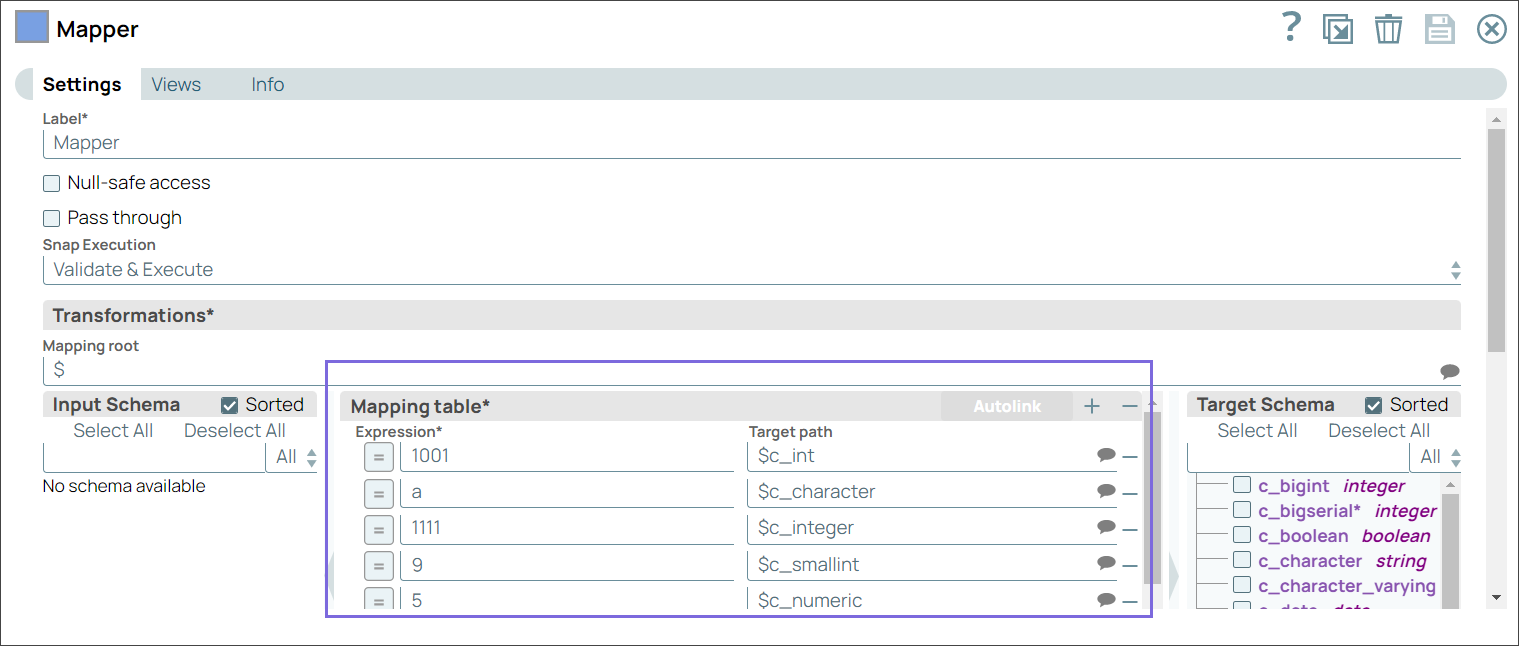
Step 1: Configure the Mapper Snap with the static or dynamic values you want to insert in the database for different variables.
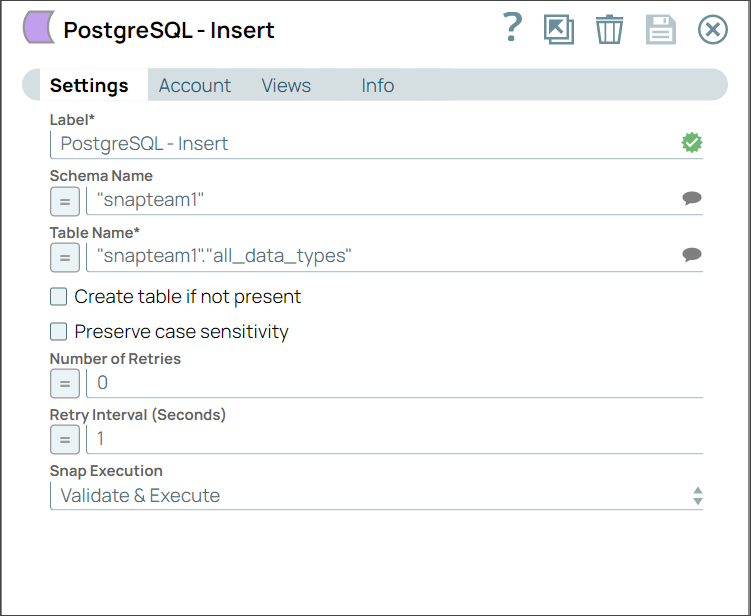
Step 2: Configure the PostgreSQL Insert Snap to insert the values in a table in the database.
Step 3: Validate the pipeline. A success message appears with all the values inserted in the database.