Kafka Consumer
- Kalpana Malladi
- Aparna Tayi (Unlicensed)
- Gouri Bhagchandani (Deactivated)
In this article
Overview
You can use the Kafka Consumer Snap to read or consume documents from a Kafka topic.
Prerequisites
- A valid account with the required permissions.
- A Kafka topic with parameters that are valid for consumption (reading).
In order for the notifications to work properly, all the Consumer and Acknowledge Snaps that belong to one consumer group should execute in the same node of the Snaplex. You can either use Pipeline Execute Snap to execute different Pipelines in the same node, or place all the Consumer and Acknowledge Snaps into one Pipeline.
Support for Ultra Pipelines
Works in Ultra Pipelines.
Limitations and Known Issues
None.
Snap Input and Output
| Input/Output | Type of View | Number of Views | Examples of Upstream and Downstream Snaps | Description |
|---|---|---|---|---|
| Input | Document |
|
| A document containing a Kafka topic, a consumer group, a partition, and an offset. |
| Output | Document |
|
| The message data with key/value parameters and metadata. |
Snap Settings
| Parameter Name | Data Type | Description | Default Value | Example |
|---|---|---|---|---|
| Label | String | Required. The name for the Snap. You can modify the default name to be more specific and meaningful, especially if you have more than one of the same Snaps in your Pipeline. | Kafka Consumer | Consumer_sales_data |
| Topic | String/Suggestion | Specify the topic from which messages are to be read. | N/A | T1 |
| Partition Number | Integer/Suggestion | Specify the partition number. This field is optional unless Seek type is set to Specify offset, in which case it is required. A value that is equal to or greater than the total number of partitions for the topic is allowed so that when a target partition is added to the topic, the Snap is ready to consume the messages from the partition without restarting. | N/A | 2 |
| Group ID | String/Expression | Required. Specify a unique string that identifies the group to which this consumer belongs. Kafka performs group rebalancing whenever a new consumer instance joins the group. We recommend you to specify a unique Group ID for each Snap instance to avoid rebalancing of all other consumer instances existing in the group. | N/A | people |
| Message Count | Integer/Expression | Specify the number of messages to be read before the consumption process stops.
If you set 0 as the value for Message Count, you might need to increase the Fetching Timeout value to avoid premature termination when records are actually available. | -1 | 20 |
| Wait For Full Count | Check box | Activates when you enter a positive integer value or an expression in the Message Count field. Select this check box to enable the Snap to read and process the messages until the specified number in the Message Count field is reached. If you deselect the check box, the Snap terminates when the specified number in the Message Count field is reached, or when all the available messages are read if the number of message is less than the specified count. | Selected | Not Selected |
| Max Poll Records | Integer/Expression | Select or enter the maximum number of records in a batch that is to be returned by a single call to poll. Increasing this value can improve performance, but also increases the number of records that require acknowledgement when Auto commit is set to false and Acknowledge mode is set to Wait after each batch of records. In this case, the value of Acknowledge timeout should be adjusted accordingly. This value sets an upper limit to the batch size, but Kafka might choose to return a smaller number of records depending on other factors, such as the size of each record. | 500 | 500 |
| Max Poll Interval (ms) | Integer/Expression | Defines the maximum time between poll invocations. This field corresponds to the Kafka If the account’s Advanced Kafka Properties specifies a value for | 300000 (5 min.) | 180000 |
| Fetching Timeout | Integer/Expression | Specify the number of milliseconds the Snap must wait to process for a single poll request. If the timeout expires, the Snap polls again for more messages, unless the message count is 0, in which case it stops as expected. | 2000 | 2000 |
| Auto Commit | Check box | Select this check box to enable the Snap to commit offsets automatically as messages are consumed and sent to the output view. If you deselect the Auto Commit check box, the Pipeline must contain one or more Acknowledge Snaps downstream to acknowledge the documents that are output by the Consumer, each of which represents an individual Kafka message, after each document is appropriately processed by the other snaps between the Consumer and Acknowledge Snaps. | Selected | Not Selected |
| Acknowledge Mode | Drop-down list | Activates when you deselect the Auto Commit check box. Select the Acknowledge Mode that determines when the Snap should wait for acknowledgments from the downstream Acknowledge Snaps. The available options are:
You must configure the Acknowledge Timeout value based on the Acknowledge Mode configuration. | Wait after each record | Wait after each batch of records. |
| Acknowledge Timeout (sec) | Expression/Integer | Activates when you deselect the Auto Commit check box. Enter the maximum number of seconds to wait for a notification from the Acknowledge Snap before committing the offset.
| 10 | 15 |
| Acknowledge Timeout Policy | Drop-down list | Activates when you deselect the Auto Commit check box. Select an Acknowledge Timeout Policy to handle acknowledge timeout errors. The available options are:
Acknowledge Timeout Policy determines the Snap's behavior when the following conditions are met:
When the Consumer’s Partition is not set, an acknowledge timeout triggers a group rebalance, which means that the reprocessing of a record might occur in a different Consumer instance within the same group. | Reprocess | Continue |
| Seek Type | Drop-down list | Specify the starting position where the Consumer Snap should begin reading messages when the Snap is first initialized and executed. The available options are:
The Kafka Consumer Snap commits offsets to Kafka as it consumes records. If the Pipeline aborts, Kafka saves the position of the last read records in each partition. If the Pipeline is restarted, and Seek Type is set to End, the Snap continues reading from the first unacknowledged record in each partitions. If the Consumer Snap is configured with an Error View, the Snap continues processing records as if the unacknowledged records had been acknowledged (after reporting the error to the Error View). The committed offsets reflect this continuation policy. If there is no Error View when a timeout occurs, the committed offsets reflect the first unacknowledged record of each partition. | End | Beginning |
| Offset | Expression/String | Activates when you choose the Specify Offset from the Seek Type list. Specify the Offset from which the Consumer should start consuming the message. The Offset is specific to a partition. Hence, when you specify an offset, you must specify the partition number. The offset starts from 0 for any partition. The Consumer can start consuming from any offset in the partition regardless of the messages that have been read earlier. | N/A | 7 |
| Auto Offset Reset | Drop-down list | Choose an option for auto offset reset from the list. The available options are:
This field is used only if no offsets have been committed for the current partition. | Earliest | Latest |
| Output Mode | Drop-down list | Activates when you select the Auto Commit field, or when you set Acknowledge Mode to Wait after each batch of records. Select the mode to output the consumed records. The available options are:
Use the One output document per batch mode if you want to preserve the batching in your Pipeline's data flow. This mode is useful when Auto Commit is disabled and Acknowledge Mode is Wait after each batch of records, depending on the nature of processing between the Kafka Consumer and the Kafka Acknowledge Snaps. | One output document per record | One output document per batch |
| Key Deserializer | Drop-down list | Select the target data type for the deserialized key of each record. The available options are:
Ensure that your Confluent Kafka Account's configuration includes the schema registry if you select Avro as the Key Deserializer value. | String | Int32 |
| Value Deserializer | Drop-down list | Select the target data type for the deserialized value of each record. The available options are:
| String | Int64 |
| Default Header Deserializer | Drop-down list | Select a Header Deserializer that is to be assigned to the headers that are not configured in the Header Deserializers table. | String | JSON |
Header Deserializers | Use this field set to define the Key and Deserializer for any headers that requires a deserializer other than the Default Header Deserializer. Click
| |||
| Key | String/Expression/Drop-down list | Specify a name for header that requires a Deserializer other than the Default Header Deserializer. | N/A | Department |
| Deserializer | String/Drop-down list | Select a Deserializer for the header to convert the header's value to a specific data type such as string or Int32. | String | ByteArray |
| Include Timestamp | Check box | Select this check box to include a timestamp in the metadata of each record that is sent to the output view. A timestamp value is the number of milliseconds that have elapsed since midnight, January 1, 1970 UTC. All Kafka records have a standard timestamp in milliseconds, and all records have a copy of the topic’s | Not selected | Selected |
| Pass Through | Check box | Select this check box to allow the original document to pass through. | Not selected | Selected |
| Snap Execution | Drop-down list | Select one of the three modes in which the Snap executes:
| Validate & Execute | Execute only |
Key Concepts
Consumers and Consumer Groups
To help scale the consumption of messages from a topic, you can split the data that is being read among multiple consumers, which allows a number of consumers to read from a topic. When you use multiple Kafka Consumer instances configured with the same consumer group, each instance is assigned a different subset of partitions in the topic.
For example, if a single Kafka Consumer Snap (c1) subscribes to a topic t1 with four partitions, and c1 is the only consumer in consumer group g1, then c1 gets all the messages from all the four partitions.
If you add a second Kafka Consumer Snap (c2), to the Pipeline within the the same consumer group (g1), the Snap assigns two partitions (for example, 0 and 2) to consumer c1 and two other partitions (for example, 1 and 3) to consumer c2.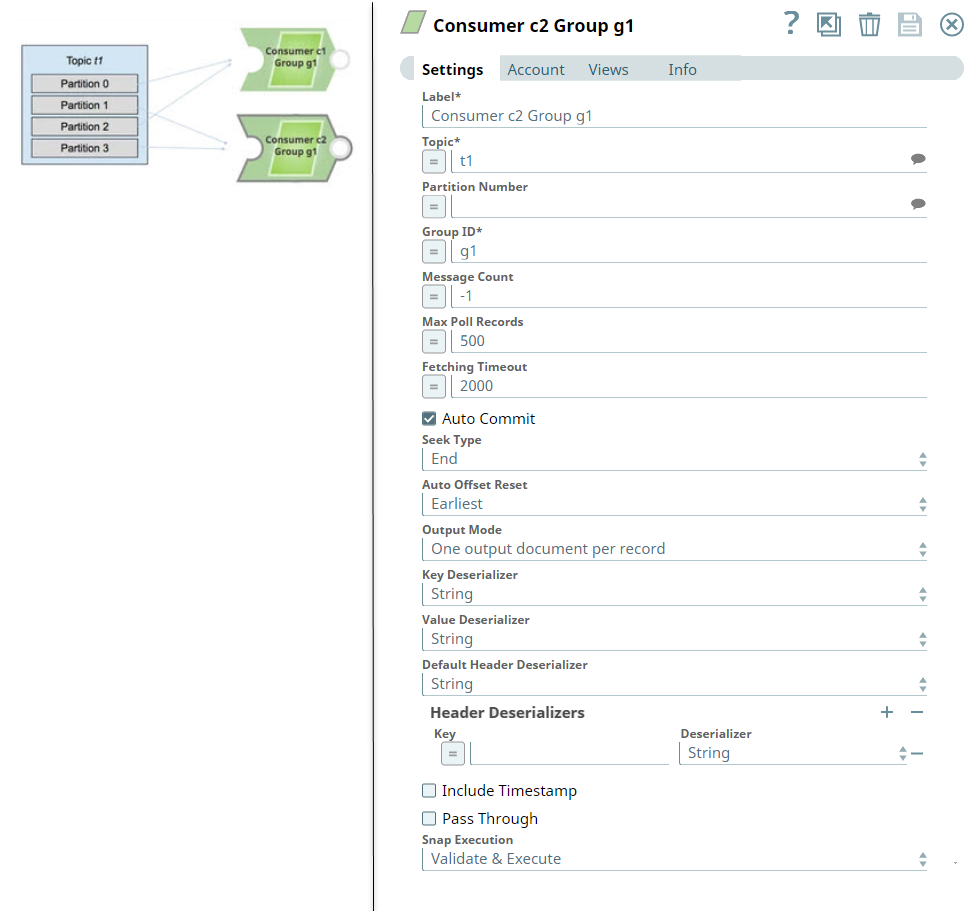
If you add more consumers to a single group, and the number of consumers is more than the number of existing partitions, then some of the consumers remain idle and do not receive messages.
If you add additional consumers to a different consumer group (for example, g2), then those consumers behave independently of those within the consumer group g1.
Consider the following example. For topic t1 with four partitions, four of the five consumers in g1 receive messages, and c5 remains in idle state (because there is no available partition to assign to this consumer). For consumer group g2, consumer c1 receives messages from partitions 0 and 2, and consumer c2 receives messages from partitions 1 and 3.
Therefore, it is important to know how many partitions exist within a topic while adding consumers to consume the messages. 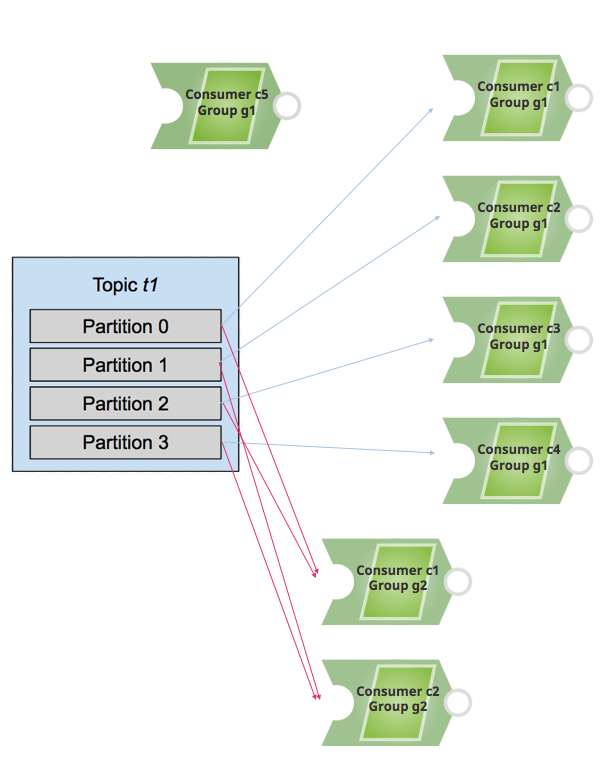
Example
Consuming Messages from a Kafka Topic
This example demonstrates how messages are read from a Kafka topic, and how the selected output documents are sent to the downstream Mapper view.
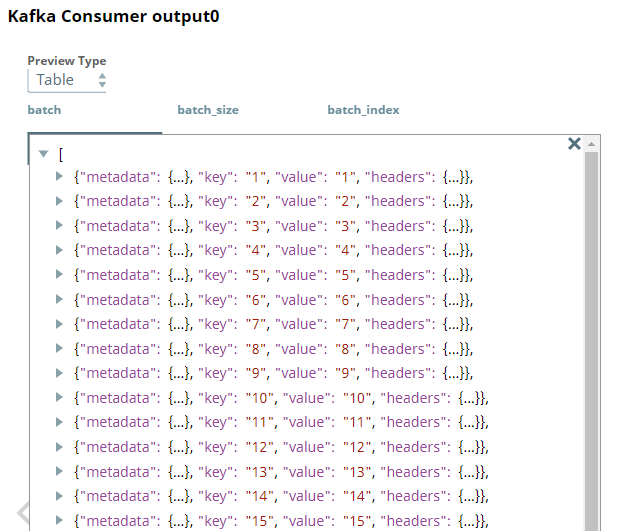
First, we configure the Kafka Consumer Snap to read the messages from the Topic, Sample_Topic, under the Group ID, consumergroup. We select the Output Mode as One output document per batch, because we want to view the output records in batches.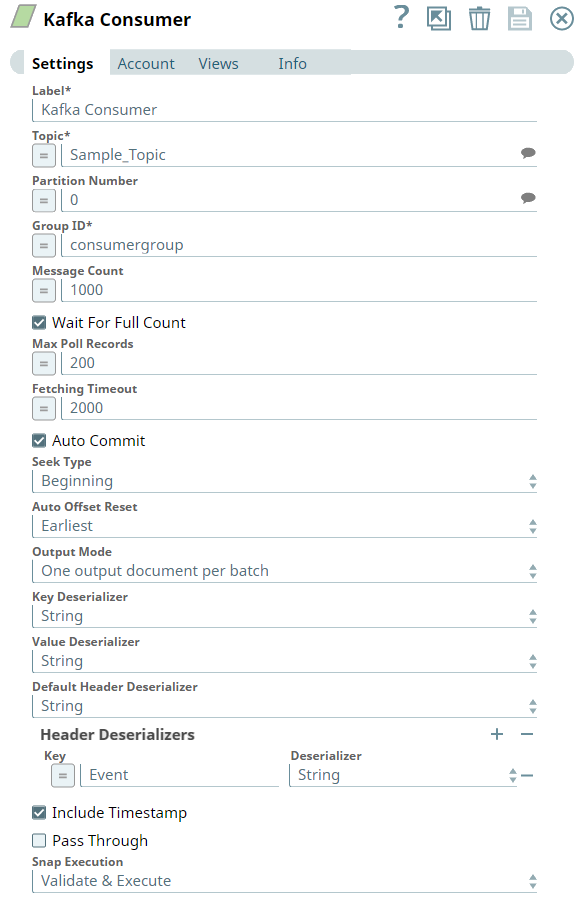
After validation, we can view the output preview of the Kafka Consumer Snap as follows:
| Kafka Consumer Output (Table) | Kafka Consumer Output (JSON) |
|---|---|
|
|

We use the Mapper Snap to display only those fields that we require in the output view. Note that we set the Mapping root to $batch[*] to map the fields of each record in the batch. Hence, we configure the Mapper Snap as shown below: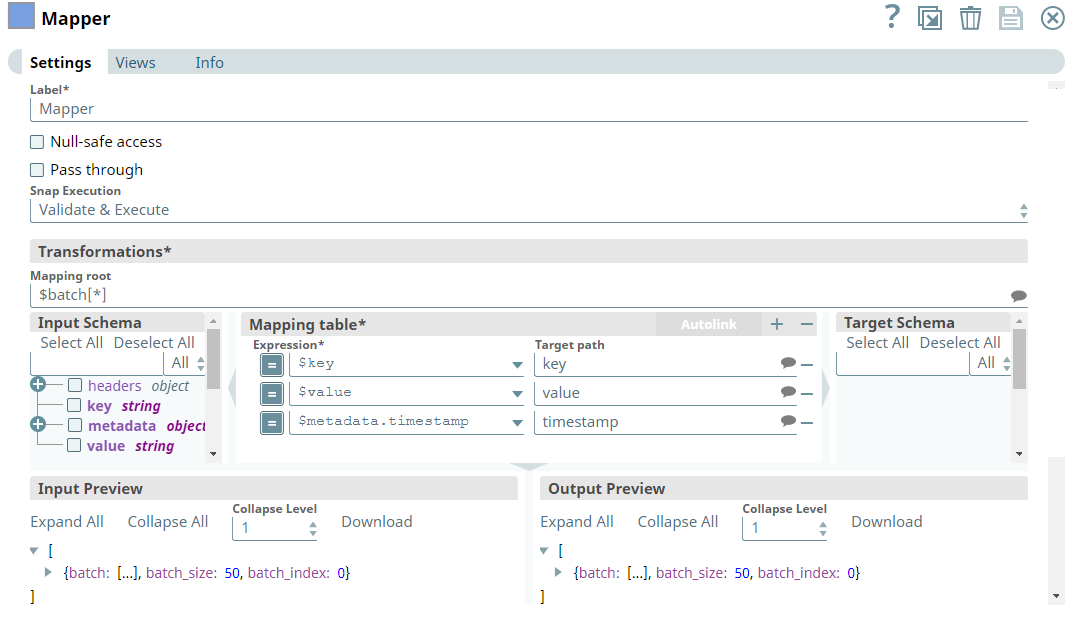
Upon successful execution, we see the output preview of the Mapper Snap as follows: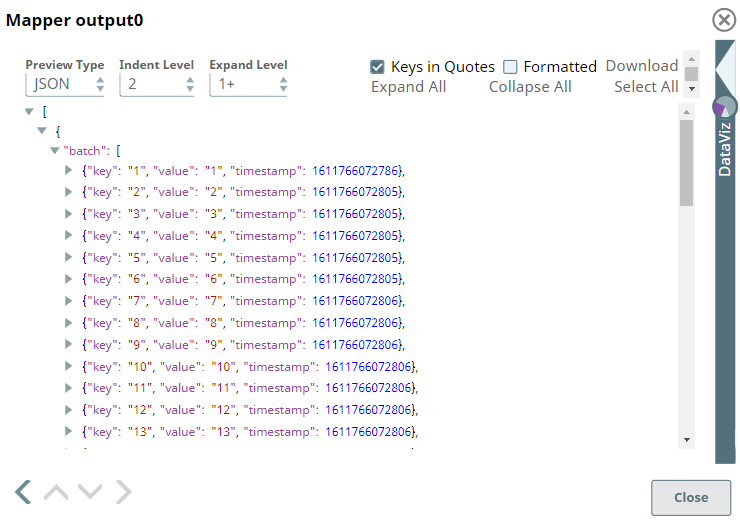
Downloads
Important Steps to Successfully Reuse Pipelines
- Download and import the Pipeline into SnapLogic.
- Configure Snap accounts as applicable.
- Provide Pipeline parameters as applicable.
Snap Pack History
| Release | Snap Pack Version | Date | Type | Updates |
|---|---|---|---|---|
| February 2025 | 440patches29980 | Latest | Enhanced the Kafka OAuth2 Account to support SASL extensions through Advanced properties using OAuth/OIDC. | |
| February 2025 | main29887 | Stable | Updated and certified against the current SnapLogic Platform release. | |
| November 2024 | main29029 | Stable | Updated and certified against the current SnapLogic Platform release. | |
| August 2024 | 438patches28723 | Latest | Enhanced the Kafka MSK IAM Account to support debugging for the IAM configuration. When you configure IAM debugging (Global properties and Logging Level) in the Snaplex configuration, the account logs the IAM credential identity in the Snaplex log. | |
| August 2024 | 438patches28225 | - | Enhanced the Kafka MSK IAM Account to support Cross Account IAM Access on Amazon MSK Cluster configured through Transit Gateway and multi VPC Peering. | |
August 2024 | main27765 | | Stable | Upgraded the |
| August 2024 | 437patches27730 | Latest | Fixed an issue with the Kafka Consumer Snap where the Seek Type of Beginning or End (skip all existing messages) may not work correctly after a rebalance. | |
| May 2024 | 437patches27404 | Latest | Fixed an issue with the Kafka SSL Account that displayed an error when the Kafka Consumer Snap could not commit offsets during the rebalancing process. This behavior avoids unstable partition allocation. Now, the Snap logs a warning, allowing the Kafka Consumer to continue processing instead of displaying an exception. | |
| May 2024 | 437patches26651 | Latest | Added Kafka OAuth2 Account to the Kafka Snap Pack to enable the usage of OAuth within the Kafka SASL_SSL framework. | |
| May 2024 | main26341 | Stable | Kafka Snap Pack: Enhanced the following fields to support expressions through pipeline parameters:
| |
| February 2024 | main25112 | Stable | Updated and certified against the current SnapLogic Platform release. | |
| November 2023 | main23721 |
| Stable | Updated and certified against the current SnapLogic Platform release. |
August 2023 | main22460 |
| Stable | Updated and certified against the current SnapLogic Platform release. |
| May 2023 | 433patches21070 | Latest | Fixed an issue with the Kafka Consumer Snap that caused it to skip records in a partition when a pipeline failed without successfully processing any records from that partition. This was an edge case that was only possible with a specific configuration of the Snap and a specific ordering of events during termination of the pipeline. | |
May 2023 | main21015 | Stable | Upgraded with the latest SnapLogic Platform release. | |
| February 2023 | 432patches20143 | Latest/Stable | Fixed an issue with the Kafka Producer Snap to avoid an error about delivery.timeout.ms. The Snap now adjusts the value of the Message Publish Timeout setting automatically and displays a warning in the Pipeline Execution Statistics. | |
| February 2023 | main19844 | Stable | Upgraded with the latest SnapLogic Platform release. | |
| November 2022 | 431patches19770 | Latest | Fixed a memory issue that occurred when the Kafka Producer Snap was used to produce many records in a long-running pipeline. | |
| November 2022 | 431patches19211 | Latest | Enhanced the Kafka Consumer Snap with the new Max Poll Interval (ms) field, which allows you to specify the time limit between subsequent calls to poll. This field corresponds to the Kafka max.poll.interval.ms property. | |
| November 2022 | main18944 | Stable | Upgraded with the latest SnapLogic Platform release. | |
| August 2022 | main17386 | Stable |
| |
| 4.29 Patch | 429patches17109 | Latest |
| |
| 4.29 | main15993 | Stable | The Kafka Snap Pack now supports Azure Event Hubs streaming service. Learn more: Azure Event Hubs configuration in Azure portal for Kafka SSL Account. | |
| 4.28 Patch | 428patches14904 | Latest | Fixed an issue with Kafka Snaps where the Snaps failed with null pointer exceptions when logging the cluster information with the controller’s identity not known. | |
| 4.28 | main14627 | Stable | Upgraded with the latest SnapLogic Platform release. | |
4.27 | main12833 | | Stable | Upgraded with the latest SnapLogic Platform release. |
| 4.26 | main11181 | Stable | Upgraded with the latest SnapLogic Platform release. | |
| 4.25 Patch | 425patches10543 | Latest |
| |
| 4.25 | main9554 | Stable | Upgraded with the latest SnapLogic Platform release. | |
| 4.24 Patch | 424patches8805 | Latest | Fixed an issue in the Kafka Producer Snap by removing the validation of the account when the Snap initialized in a Pipeline execution. | |
| 4.24 | main8556 | Stable | Upgraded with the latest SnapLogic Platform release. | |
| 4.23 Patch | 423patches7900 | Latest |
| |
| 4.23 | main7430 | Stable | Fixed an intermittent issue of Confluent Kafka Consumer Snap stopping when Message Count is 0 while the records are available. The Snap will now stop only if a poll returns no records twice in a row, and has partitions assigned before and after each poll. | |
| 4.22 | main6403 | Stable | Upgraded with the latest SnapLogic Platform release. | |
| 4.21 Patch | 421patches6136 | Latest | Enhanced the Confluent Kafka Consumer Snap with an option to allow reprocessing of records that remain unacknowledged due to acknowledge timeouts. This ensures that all records from Kafka are processed. | |
4.21 Patch | 421patches5862 | Latest | Fixes the Confluent Kafka Consumer Snap that aborts abruptly upon getting a | |
| 4.21 | snapsmrc542 |
| Stable | Enhanced the Confluent Kafka Consumer Snap to significantly reduce the volume of commit requests for offsets when using the Record acknowledgement mode (Wait after each record), and thereby, improve performance and stability. |
4.20 Patch | confluentkafka8747 | Latest | Updated the Confluent Kafka SSL Account settings to make the Truststore filepath and Truststore password properties optional. | |
| 4.20 | snapsmrc535 | Stable | Upgraded with the latest SnapLogic Platform release. | |
| 4.19 | snaprsmrc528 | Stable | Upgraded with the latest SnapLogic Platform release. | |
| 4.18 Patch | confluentkafka8111 | Latest | Fixed an issue with the Confluent Kafka Producer Snap wherein the Topic property doesn't evaluate expression against input documents. | |
| 4.18 Patch | confluentkafka8006 | Latest | Fixed an exception that occurs while consuming log-compacted topics, in the Confluent Kafka Consumer Snap. | |
| 4.18 Patch | confluentkafka7784 | Latest | Fixed the Consumer Snap to stop quickly and cleanly on CLOSE and STOP lifecycle events. | |
4.18 Patch | confluentkafka7732 | Latest | Added support for Kerberos-based authentication to enable connecting to Kerberos-enabled Kafka servers. | |
| 4.18 | snapsmrc523 | Stable | Upgraded with the latest SnapLogic Platform release. | |
4.17 Patch | confluentkafka7537 | Latest | Updated the following Snaps:
| |
| 4.17 | ALL7402 | Latest | Pushed automatic rebuild of the latest version of each Snap Pack to SnapLogic UAT and Elastic servers. | |
| 4.17 | snapsmrc515 | Latest |
| |
| 4.16 Patch | confluentkafka7118 | Latest | Fixed an issue with the Confluent Kafka Producer Snap wherein the Snap fails to produce the upstream Snap's input schema for Partition Number property in the output preview. | |
4.16 Patch | confluentkafka6891 | Latest | Certified Confluent Platform version 5.x. | |
| 4.16 | snapsmrc508 | Stable | Upgraded with the latest SnapLogic Platform release. | |
| 4.15 Patch | confluentkafka6446 | Latest | Fixed an issue with the Confluent Kafka Consumer Snap wherein some connections were not closed after a Pipeline is aborted. | |
| 4.15 | snapsmrc500 | Stable | Upgraded with the latest SnapLogic Platform release. | |
| 4.14 Patch | confluentkafka5737 | Latest | Added a new property to the Confluent Kafka Producer Snap, Message publish timeout (milliseconds), that lets you specify a timeout value. | |
| 4.14 Patch | confluentkafka5663 | Latest | Fixed the Confluent Kafka Snaps that do not delete temp files after pipeline execution. | |
| 4.14 | snapsmrc490 | Stable | Upgraded with the latest SnapLogic Platform release. | |
| 4.13 Patch | confluentkafka5614 | Latest | Fixed the Confluent Kafka Snap Pack that does not delete the temp files after executing pipelines. | |
| 4.13 Patch | confluentkafka5330 | Latest | Added support in Confluent Kafka Producer Snap the ability to write data to multiple partitions, in a round robin fashion. | |
| 4.13 | snapsmrc486 | Stable | Upgraded with the latest SnapLogic Platform release. | |
4.12 Patch | confluentkafka5087 | Latest | Fixed an issue with the Consumer Snap that fails when the specified timeout value is less than the pipeline execution time. | |
| 4.12 | snapsmrc480 | Stable | Enhanced the performance of the Confluent Kafka Producer Snap in writing incoming documents into the Confluent Kafka Cluster. | |
4.11 Patch | confluentkafka4626 | Latest | Fixed an issue with the Confluent Kafka Consumer Snap wherein the Consumer session is not closing properly when manually stopping a pipeline, which causes the subsequent pipeline execution to wait for the previous session to die and not consume messages. | |
| 4.11 Patch | confluentkafka4302 | Latest | Fixed an issue with the Confluent Kafka Consumer Snap that fetched 500 messages only, when message count set to 0 caused due to driver default value change. | |
| 4.11 | snapsmrc465 | Stable | Updated the Confluent Kafka SSL Account with SCRAM_SASL support. | |
| 4.10 | snapsmrc414 | Stable | Confluent v3.2 support for Confluent Kafka Snap Pack. | |
| 4.9 Patch | confluentkafka3156 | Latest | Fixed an issue regarding account validation failure due to unauthorized topics; Enhance the error message for empty topic suggestions | |
| 4.9 | snapsmrc405 | Stable |
| |
| 4.8 Patch | confluentkafka2804 | Latest | Addressed an issue with Confluent Kafka Producer not including input document schema in Message Key and Value expression properties | |
| 4.8 | snapsmrc398 | Stable | New Snap Pack for 4.8. It consists of Confluent Kafka Consumer and Confluent Kafka Producer. |
See Also
Have feedback? Email documentation@snaplogic.com | Ask a question in the SnapLogic Community
© 2017-2025 SnapLogic, Inc.