ELT Snap Pack Use Case Example
- Kalpana Malladi
- Anand Vedam
- Ankur Parekh
- Subhajit Sengupta
In this article
Use Case: Quick Retrieval of a Customer's Orders Information
In an e-Commerce environment, a customer typically has multiple orders, and managing huge volumes of data can be resource-consuming and time-consuming. To drive business growth using analytics and data insights, an enterprise application must be able to get customers' order data quickly and easily. This use case demonstrates how we can use the ELT Snap Pack to build an incremental query to load and transform data for retrieving a customer's order data from the database.
Problem
In a typical e-Commerce enterprise, customer data and order data are usually stored in separate tables in the database. To get the data of the orders placed by a certain customer from the database, we must read both these tables, filter the data for the specific customer, and then write the results into a separate table. Building an SQL query for this seemingly straightforward task is a complicated process. Besides, we cannot view the result of our query until the query is executed on the database. Therefore, testing such a query is difficult and could lead to getting incomplete or inaccurate data.
Solution
Using the ELT Snap Pack, enterprises can build a solution that efficiently automates the process of extracting, loading, and transforming data. We can leverage the functionalities of ELT Snaps, such as nesting SQL statements, to get the data we want quickly and easily to draw analytical insights, revisit business strategies, and drive business growth.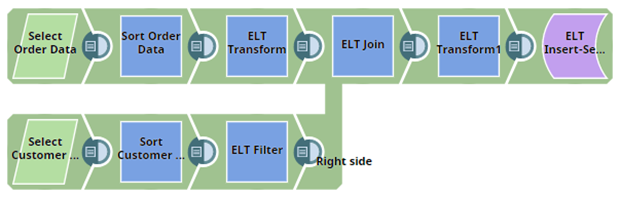
Understanding the ELT Pipeline
We leverage the ELT Snap Pack in this Pipeline to build an incremental query. This Pipeline involves a combination of ELT Snaps that we configure to get a single SQL statement (query) as the output for each Snap. Subsequently, the queries from all the Snaps are processed to form a single query, and finally, a single fully nested query is executed by the Pipeline in the target cloud data warehouse.
Understanding the Dataset
For this ELT Pipeline, we use the following dataset:
- We select the order data from the ORDERS3 table from the Snowflake database.
- We select the customer data from the CUSTOMERS3 table from the Snowflake database.
- We identify each customer by an unique ID that is included in the CUST_CODE column in the Customer table.
In this use case, we intend to get only the order data for the customer with the ID C00009. Building this Pipeline involves the following key steps:
- Select and transform order data.
- Select and filter customer data.
- Join and transform order and customer data.
- Insert the final data into a table for further processing.
Select and Transform Order Data
First, we configure the Pipeline to select, sort, and transform data. 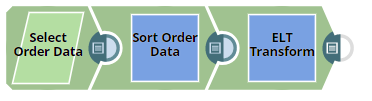
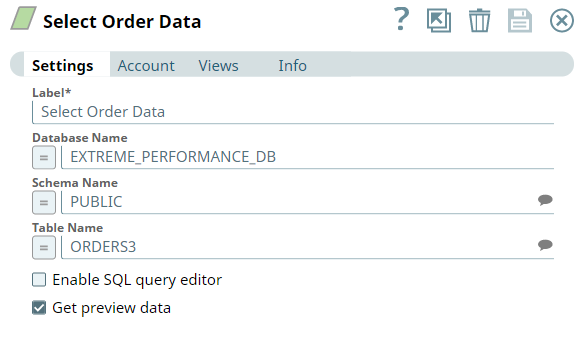
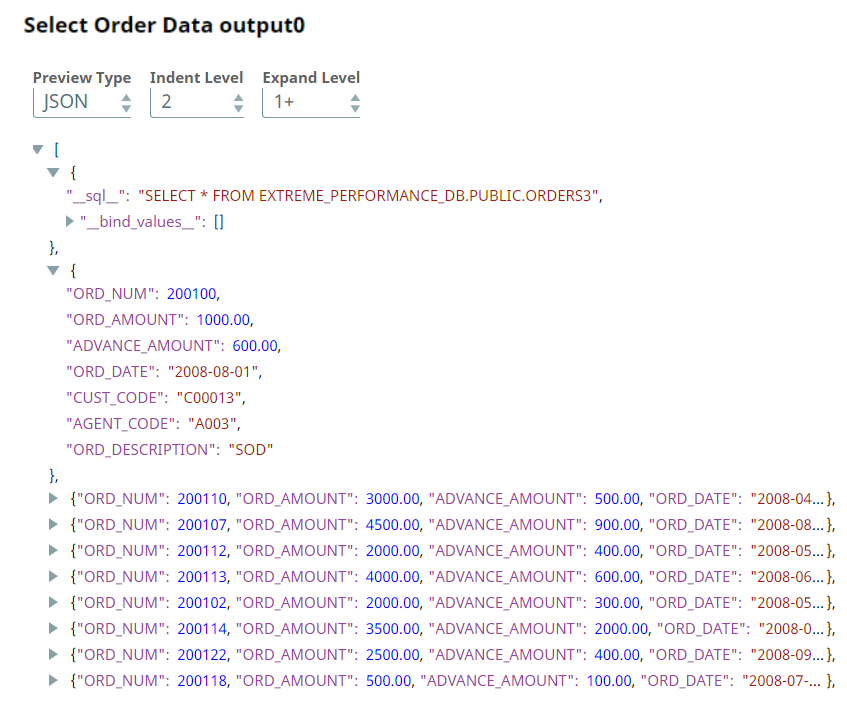
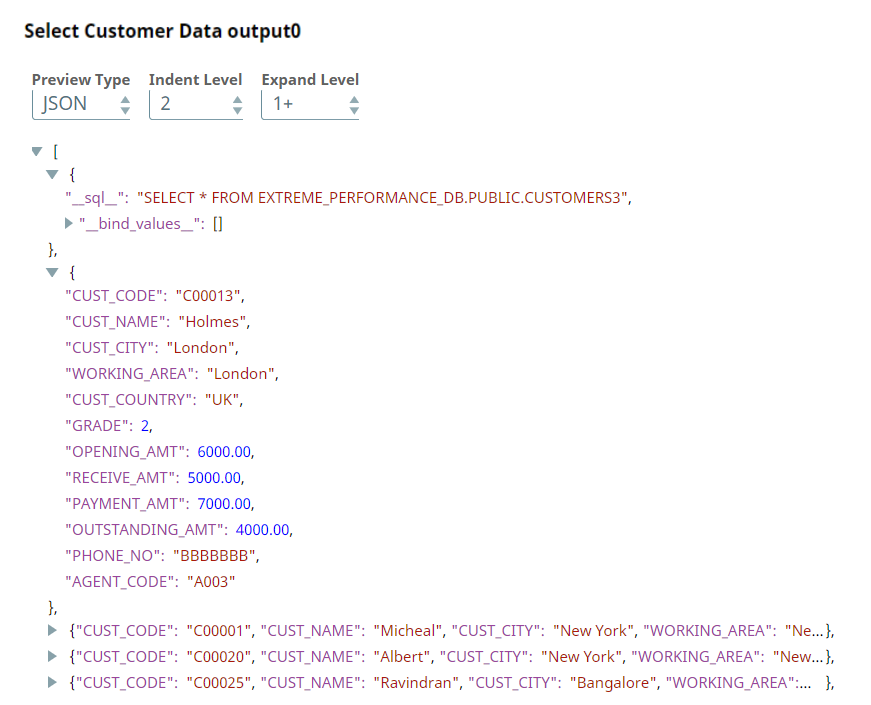
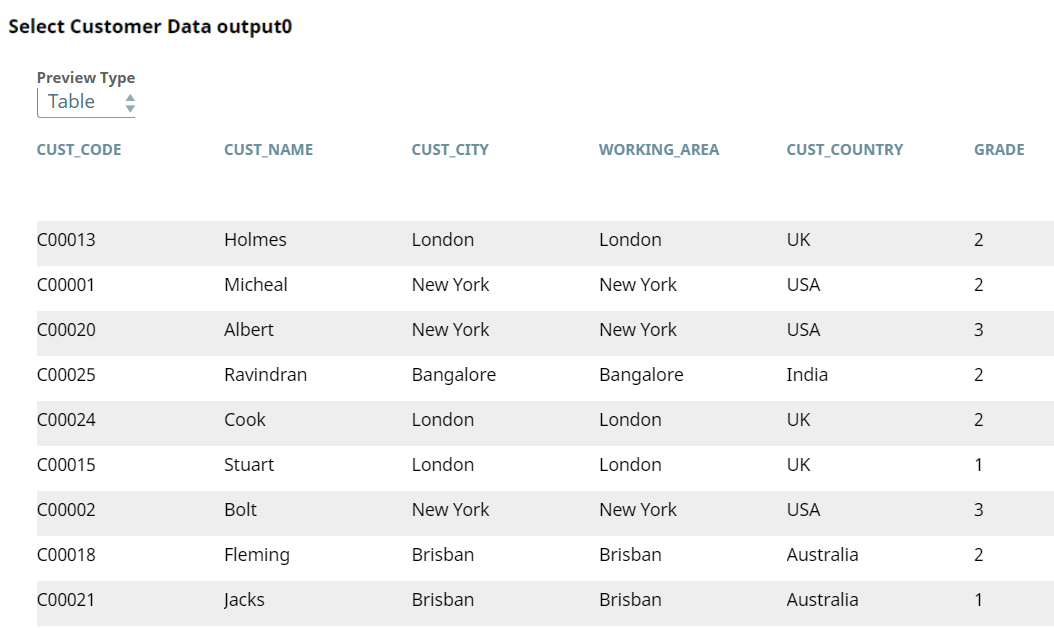
We use the ELT Select Snap to read the order table, ORDERS3. Upon validation, the Snap creates a SELECT query that includes a preview of the query's execution. The following screenshots show the Snap's output in JSON and Table formats.
| ELT Select | |
|---|---|
| |
| Output Preview in JSON format | |
| |
| Output Preview in Table format | |
|
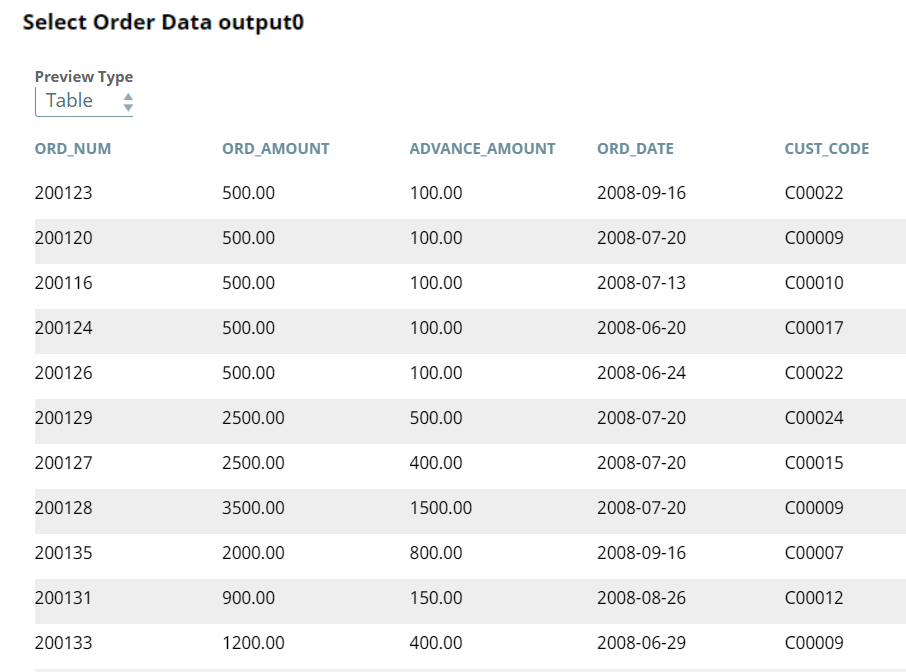
We then use the ELT Sort Snap to sort the order data based on the CUST_CODE column in ascending order, with null values displayed first in the list.
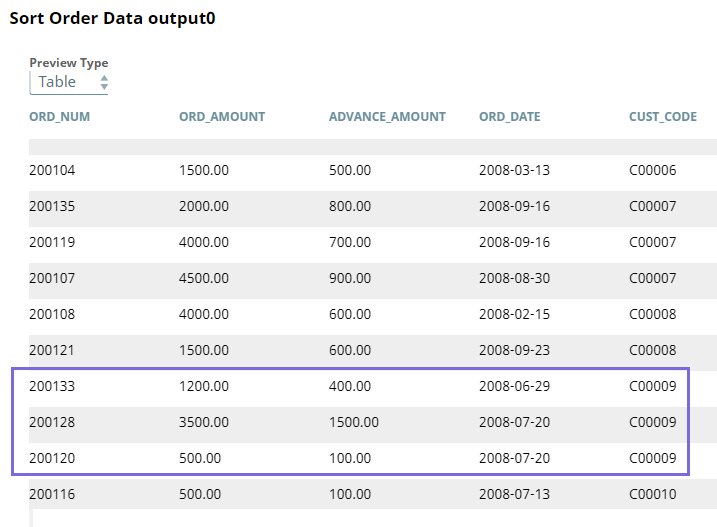
While sorting the data in the table is optional, sorting makes reading and interpreting the data easy, especially if your tables have large volumes of records. However, be aware that the sort operation increases the performance overhead of the Pipeline. We use the sort operation here only as an illustration.
The order table has several columns. We intend to get only the order amounts for each customer. We also plan to rename the CUST_CODE column to avoid collision of identical column names when we join the order and customer tables later. This error occurs when we join tables that have columns with the same name. Therefore, we use the ELT Transform Snap to:
- Output only the CUST_CODE and ORD_AMOUNT columns.
- Rename the CUST_CODE column to CUST_CODE1.
![]()
Upon validation, the ELT Transform Snap builds a SELECT query as shown in the following screenshot.![]()
Select and Filter Customer Data
This part of the Pipeline extracts, sorts, and filters the customer data based on the customer ID.
We use the ELT Select Snap to select the customer table, CUSTOMERS3.
| ELT Select | |
|---|---|
| |
| Output Preview in JSON Format | |
| |
| Output Preview in Table Format | |
|
Similar to what we did with the order data, we plan to sort the customer data. We use the ELT Sort Snap to sort the customer data based on the CUST_CODE column in ascending order, with null values listed first.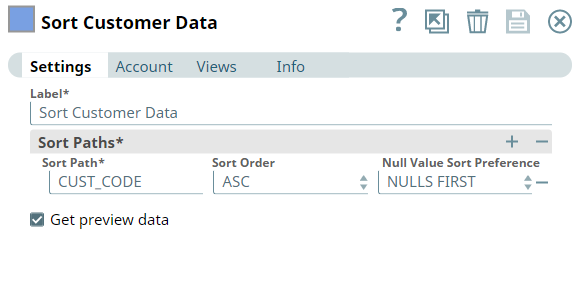
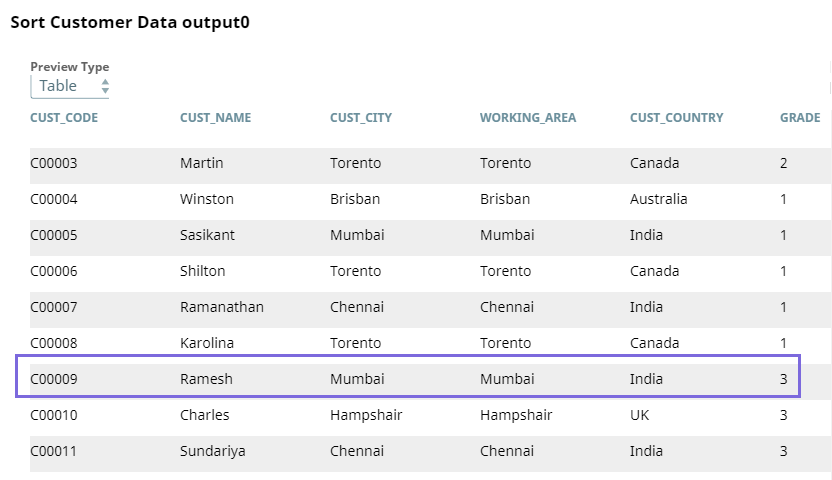
Next, we plan to get the order data of the customer C00009. Hence, we use the ELT Filter Snap to filter the data only for this customer. 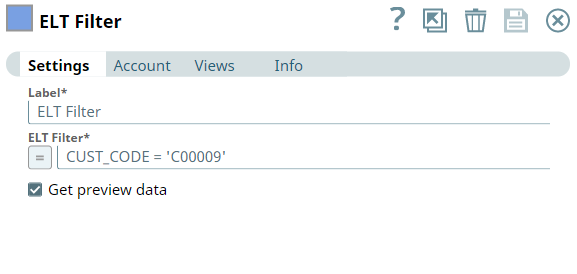
This Snap builds the following query.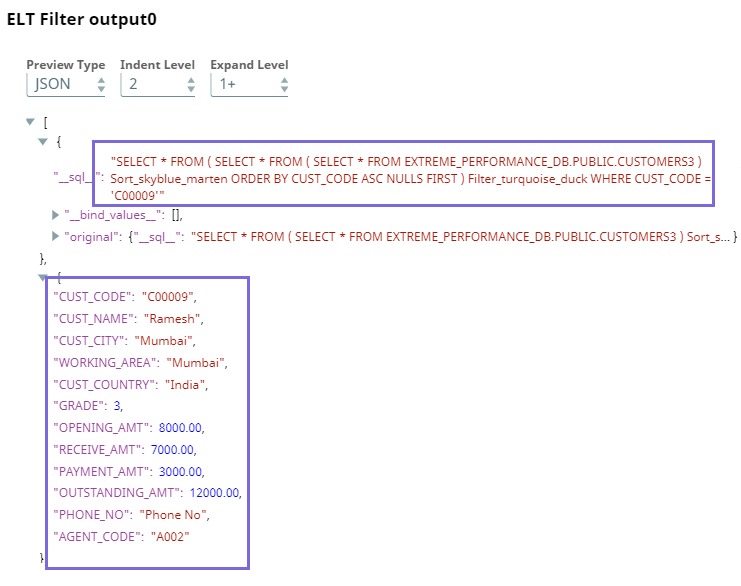
Join and Transform Order and Customer Data
In this part of the Pipeline, we configure the Pipeline to process the final join and transform operations.
Now that we have the datasets we need (customer's data and the data of all orders placed by that customer), we must join the datasets to combine the customer details and the order details. Hence, we configure the Pipeline with the ELT Join and ELT Transform Snaps to join and transform the customer data.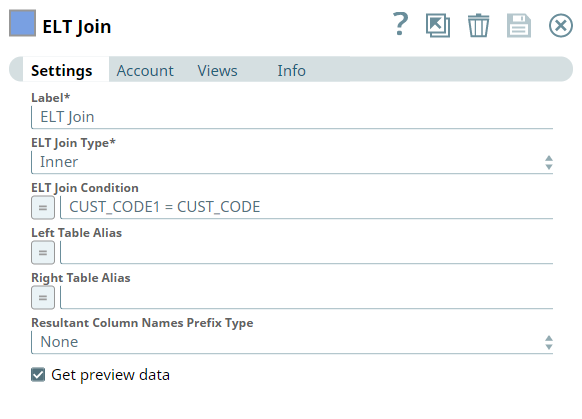
Upon successful execution, the Snap creates a SELECT query with the JOIN statement that includes a preview of the query's execution.
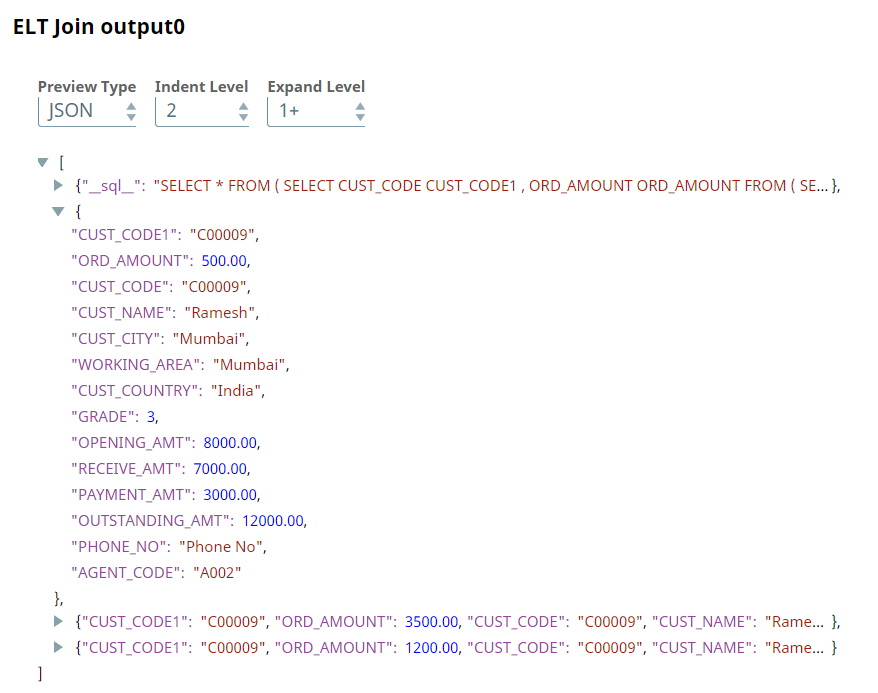
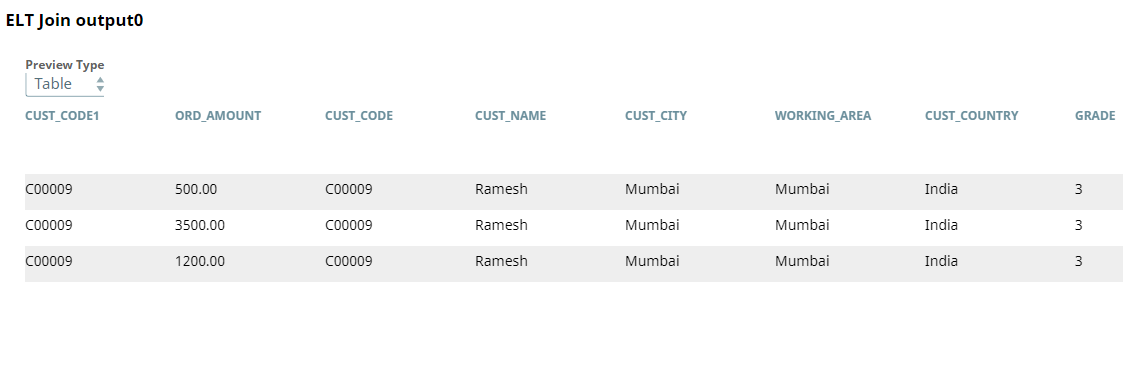
The data in the above screenshot is the data that we want. We can insert this data directly into another table for further processing. However, in this use case, we intend to insert only the CUST_NAME, CUST_CITY, and ORD_AMOUNT columns. We use the ELT Transform Snap to achieve this task.
![]()
Upon validation, this Snap builds a query as shown in the following screenshot.![]()
Insert the Final Data
This part of the Pipeline executes the final step.
In the final part, we pass the entire query that is built to the ELT Insert-Select Snap to run the query in the target database. Running this query enables the Pipeline to extract, load, and transform the data. As the ELT Insert-Select Snap has no output view, we use the ELT Select Snap to select the table and to verify whether the data is inserted correctly in the table.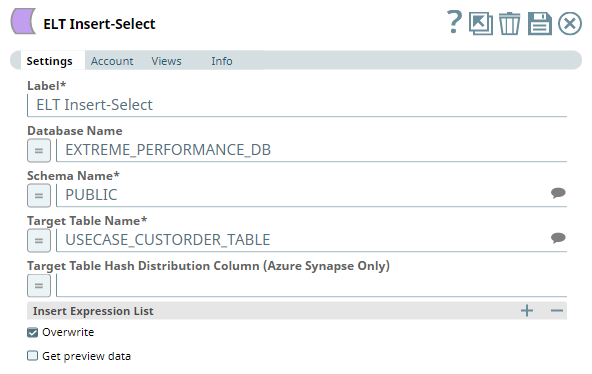
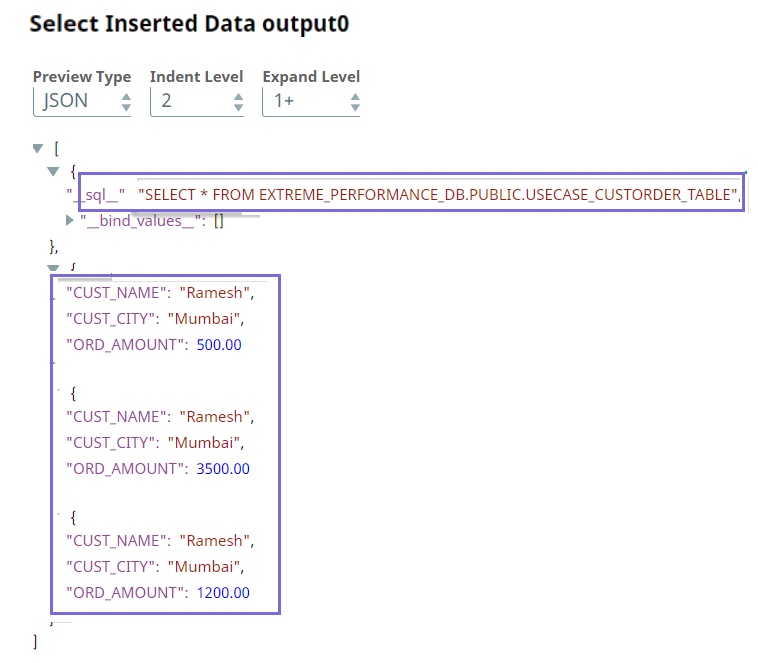
We can use this data to draw analytical insights using the various analytical capabilities offered by the database.
Downloads
Important steps to successfully reuse Pipelines
- Download and import the pipeline into the SnapLogic application.
- Configure Snap accounts as applicable.
- Provide pipeline parameters as applicable.
Have feedback? Email documentation@snaplogic.com | Ask a question in the SnapLogic Community
© 2017-2025 SnapLogic, Inc.