ELT: Analyze Customer Returns For Retail Stores Chain
- Shilpa
In this Article
Use Case: Analyze Customer Returns For Retail Stores Chain
In a real business scenario, once the customers receive their placed order, they have an option to return the order in the retail chain. This use case demonstrates how you can use SnapLogic ELT Snap Pack to analyze customer returns for a retail stores chain. This example demonstrates the process to find customers who have returned items worth 20% more often than the average customer returns for a store in a given state for a given year.
Problem
For a given retail chain, we need data on customers who return more than 20% of the average customer merchandise returns for a given store per year. In the retail industry, the dataset is typically large, running into several terabytes. The challenge in dealing with such large datasets is grouping the data.
Solution
This use case is based on the TPC Benchmark DSTM (TPC-DS) specification, a widely used decision support industry benchmark that evaluates the performance of big data processing engines. TPC-DS models the Data Science functions that retailers use to capture the longer-running complex queries of Data Science. TPC-DS models the Data Science functions of a retailer. This model captures the longer-running complex queries of Data Science and represents samples of data sets - customers, store, store_returns, and data_dim.
There is a fact dataset: STORE_RETURNS and 3 dimensions datasets: DATE_DIM, STORES, and CUSTOMERS.
ELT Solution Pipeline
To solve this big data problem, we have designed example Pipelines that run on the following:
- AWS Snowflake
- AWS Redshift
- Microsoft Azure Synapse
- Microsoft Azure Databricks Lakehouse Platform
- Google BigQuery
Example Pipelines - Snowflake
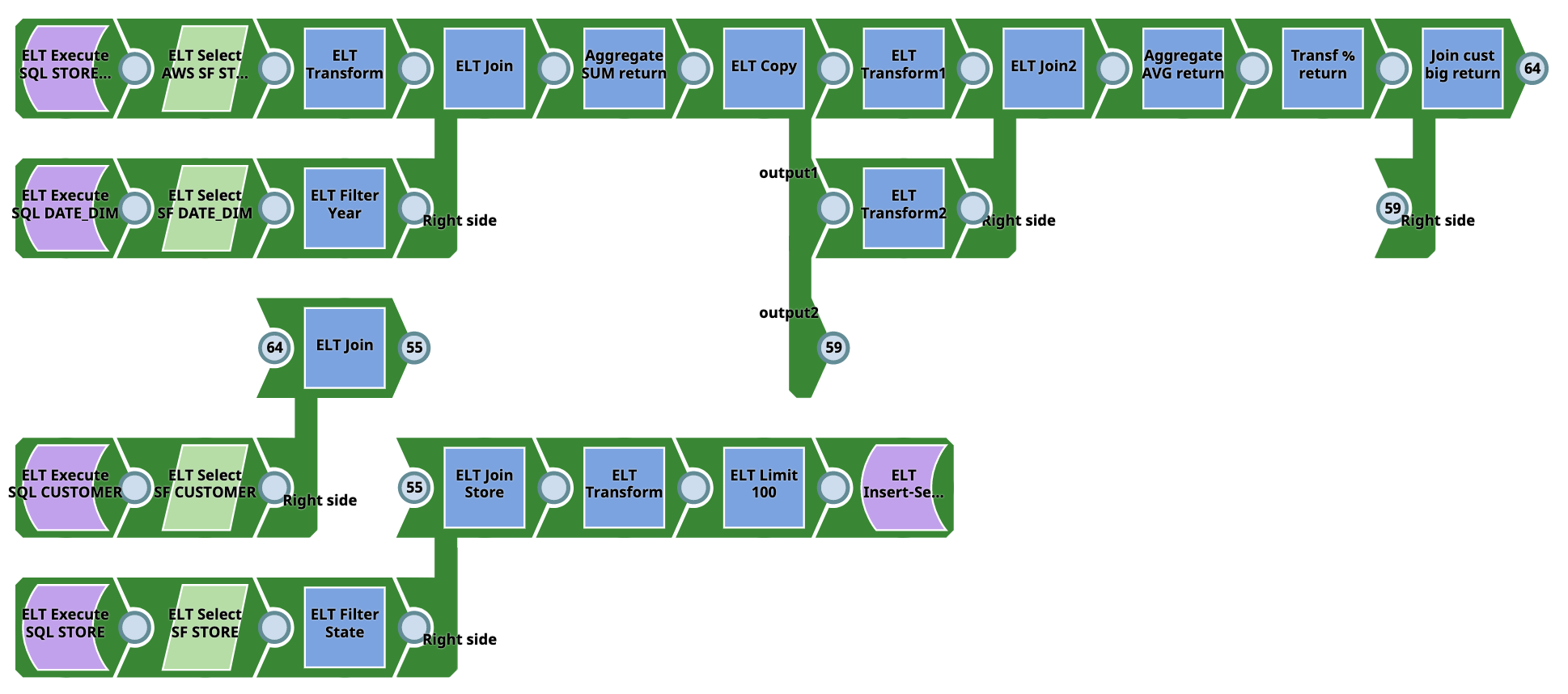
Pipeline 1 (SQL to Snowflake)
This Pipeline does not require source tables as they are created on Snowflake during runtime using SQL. Output target tables are also created on Snowflake. The Pipeline writes from the Snowflake database to the Snowflake database. Users need not have Snowflake accounts. However, they require SQL experience.
You can download the Pipeline from here
Pipeline 2 (S3 to SF)
This Pipeline does not require source tables as they are created on Snowflake on the fly using ELT Load snap and the output target tables are created on Snowflake. The Pipeline writes from the Snowflake - from the S3 location to the Snowflake database. The Pipeline converts CSV data to database tables. This data can be used for a wide variety of complex tasks. It requires table schema setup and AWS/Snowflake account is required. Users need not require SQL experience for this Pipeline.
.png?version=4&modificationDate=1655899528546&cacheVersion=1&api=v2)
You can download the Pipeline from here
Pipeline 3 (Snowflake to Snowflake)
The Pipeline writes from the Snowflake database to the Snowflake database. However, it requires source tables to be present in the Snowflake database to run the Pipeline. An output target table is created on Snowflake. The Pipeline converts data from CSV to database tables and can be used for a wide variety of complex tasks. It requires table schema setup and AWS/Snowflake account is required. Users need not require SQL experience for this Pipeline.
.png?version=3&modificationDate=1655899658482&cacheVersion=1&api=v2)
You can download the Pipeline from here
Example Pipelines - AWS Redshift
Pipeline 1 (SQL to Redshift)
This Pipeline does not require source tables or raw data as they are created on AWS Redshift on the fly from SQL. Output target tables are also built on AWS Redshift. However, they require SQL experience. It can be used only for ELT demos or simple tasks.
You can download the Pipeline from here
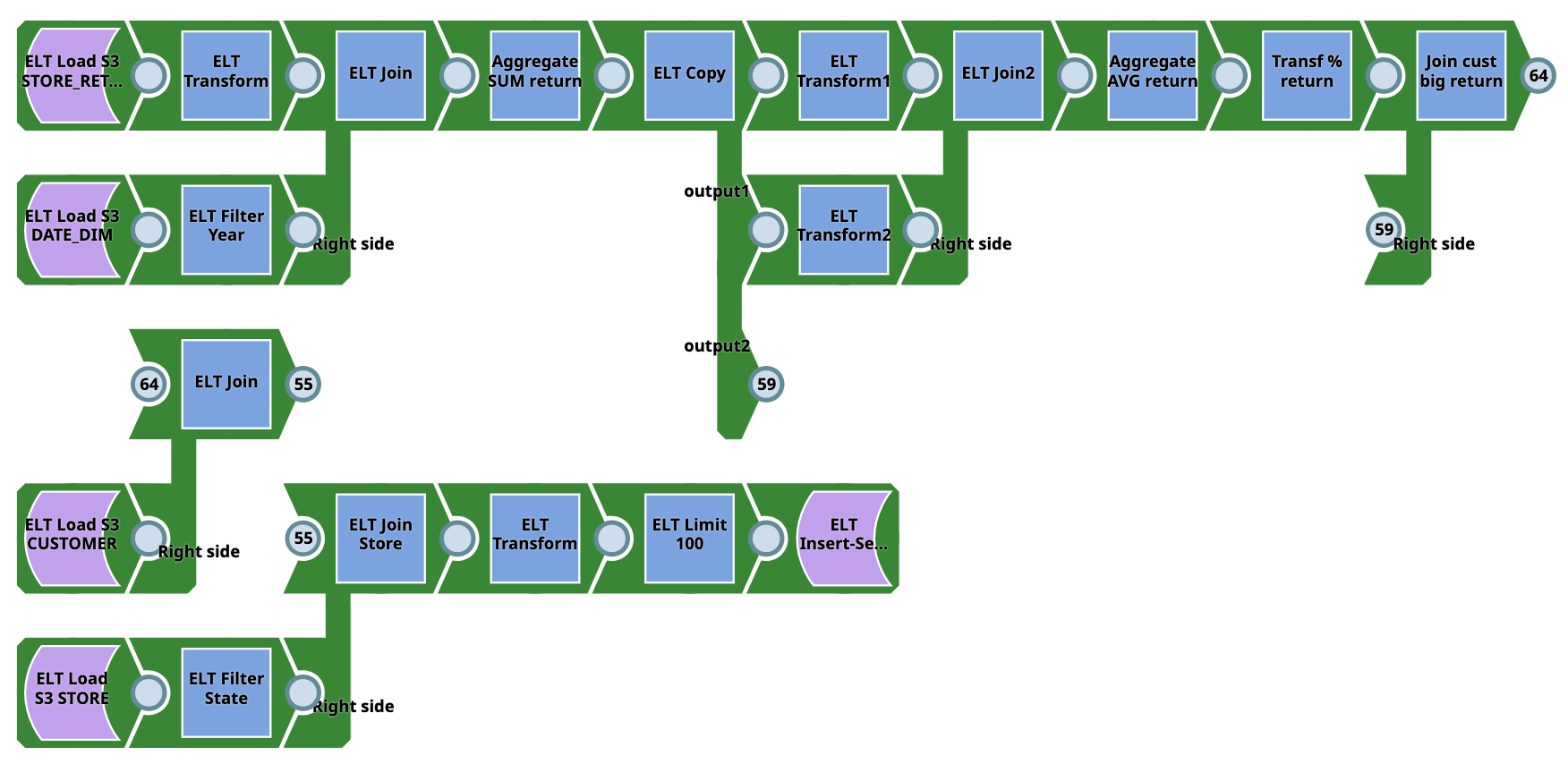
Pipeline 2 (S3 to RS)
This Pipeline does not require source tables as they are created on AWS Redshift on the fly using ELT Load snap and the output target tables are made on AWS Redshift. The Pipeline converts data from CSV to database tables and can be used for a wide variety of complex tasks. It requires table schema setup and AWS Redshift account is required. Users need not require SQL experience for this Pipeline.
You can download the Pipeline from here
Pipeline 3 (RS to RS)
The Pipeline writes from AWS Redshift to AWS Redshift. However, source tables must be present in AWS Redshift before execution. Users do not require SQL experience. The Pipeline can be used for a wide variety of complex tasks.
You can download the Pipeline from here
Example Pipelines - Microsoft Azure Synapse
Pipeline 1 (SQL to SY)
This Pipeline does not require source tables or raw data as they are created on Azure Synapse on the fly from SQL. Output target tables are also created on Azure Synapse. However, they require SQL experience. It can be used only for ELT demo or simple tasks.
You can download the Pipeline from here
Pipeline 2 (Microsoft Azure Data Lake Storage to Azure Synapse)
This Pipeline does not require source tables as they are created on Azure Synapse on the fly using ELT Load snap and the output target tables are made on Azure Synapse. The Pipeline converts data from CSV (ADLS Gen 2 location) to database tables and can be used for a wide variety of complex tasks. It requires table schema setup and an Azure Synapse account is required. Users need not require SQL experience for this Pipeline.
You can download the Pipeline from here
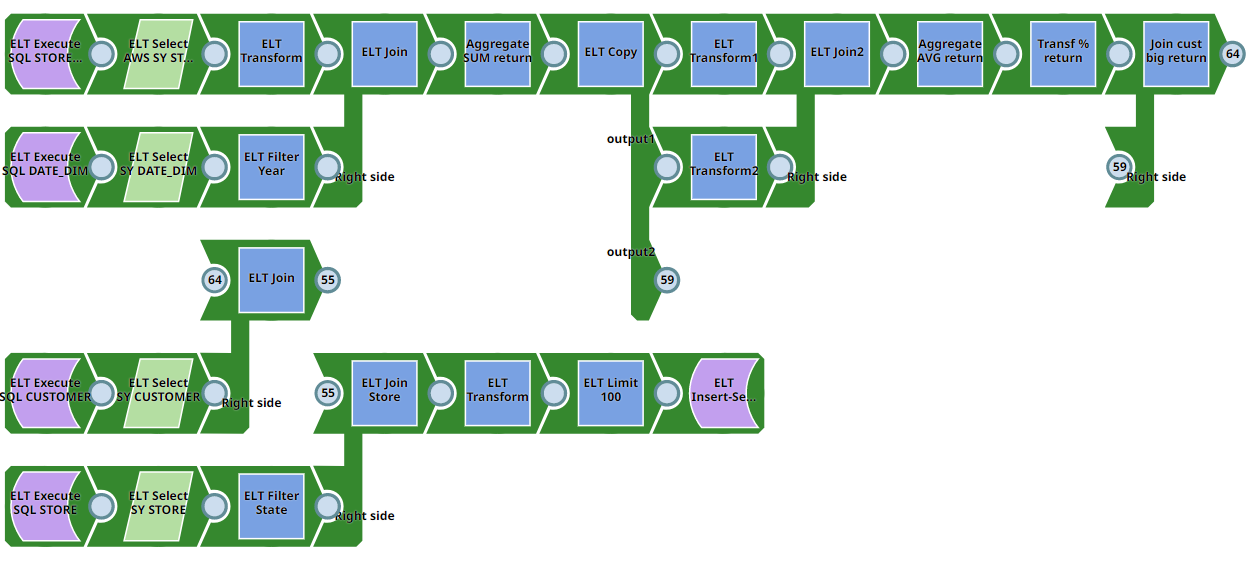
Pipeline 3 (SY to SY)
The Pipeline writes from Azure Synapse to Azure Synapse. However, it requires source tables to be present in the Azure Synapse before execution. Users do not require SQL experience. The Pipeline can be used for a wide variety of complex tasks.
You can download the Pipeline from here
Example Pipelines - Microsoft Azure Databricks Lakehouse Platform
Pipeline 1 (SQL to DLP)
This Pipeline does not require source tables or raw data as they are created on Microsoft Azure Databricks Lakehouse Platform (DLP) on the fly from SQL. Output target tables are also built on Microsoft Azure Databricks Lakehouse Platform. The Pipeline writes from the Microsoft Azure Databricks Lakehouse Platform database to the Microsoft Azure Databricks Lakehouse Platform. However, they require SQL experience. It can be used only for ELT demo or simple tasks.
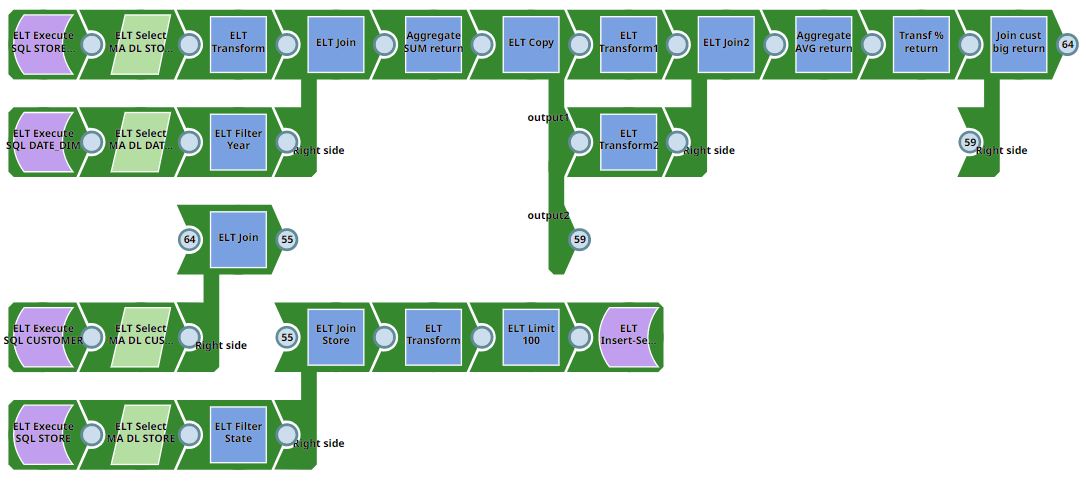
You can download the Pipeline from here
Pipeline 2 (DBFS to DLP)
This Pipeline does not require source tables as they are created on Databricks Lakehouse Platform on the fly using ELT Load snap and the output target tables are created on Databricks Lakehouse Platform. The Pipeline converts data from CSV (DBFS location) to database tables and can be used for a wide variety of complex tasks. It requires table schema setup and DLP account is required. Users need not require SQL experience for this Pipeline.
You can download the Pipeline from here
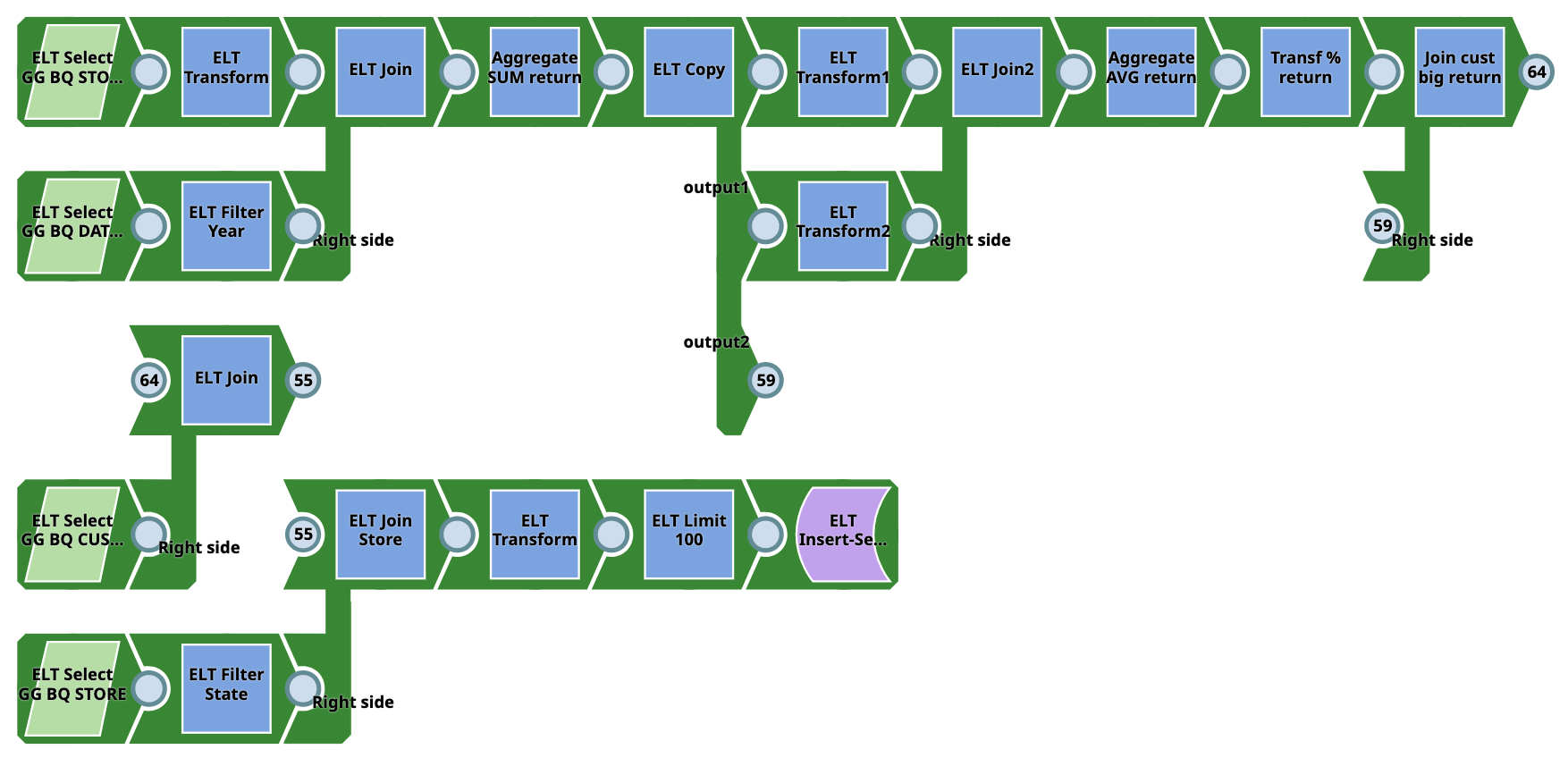
Pipeline 3 (DLP to DLP)
The Pipeline writes from the Microsoft Azure Databricks Lakehouse Platform to the Microsoft Azure Databricks Lakehouse Platform. However, source tables must be present in the Microsoft Azure Databricks Lakehouse Platform before execution. An output target table is created on Microsoft Azure Databricks Lakehouse Platform. Users do not require SQL experience. The Pipeline can be used for a wide variety of complex tasks.
You can download the Pipeline from here
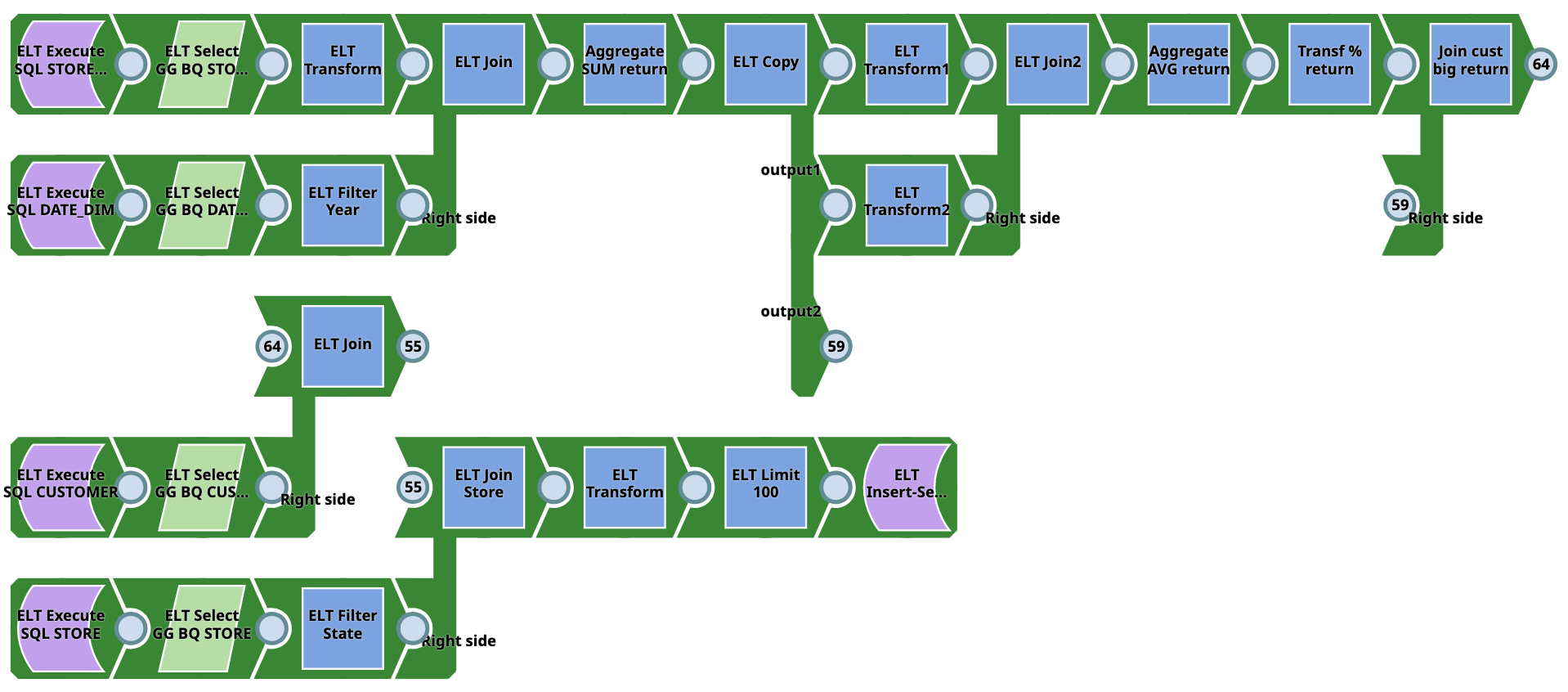
Example Pipelines - Google BigQuery
Pipeline 1 (SQL to BQ)
This Pipeline does not require source tables or raw data as they are created on Google BigQuery on the fly from SQL. Output target tables are also created on Google BigQuery. However, they require SQL experience. It can be used only for ELT demo or simple tasks.
You can download the Pipeline from here
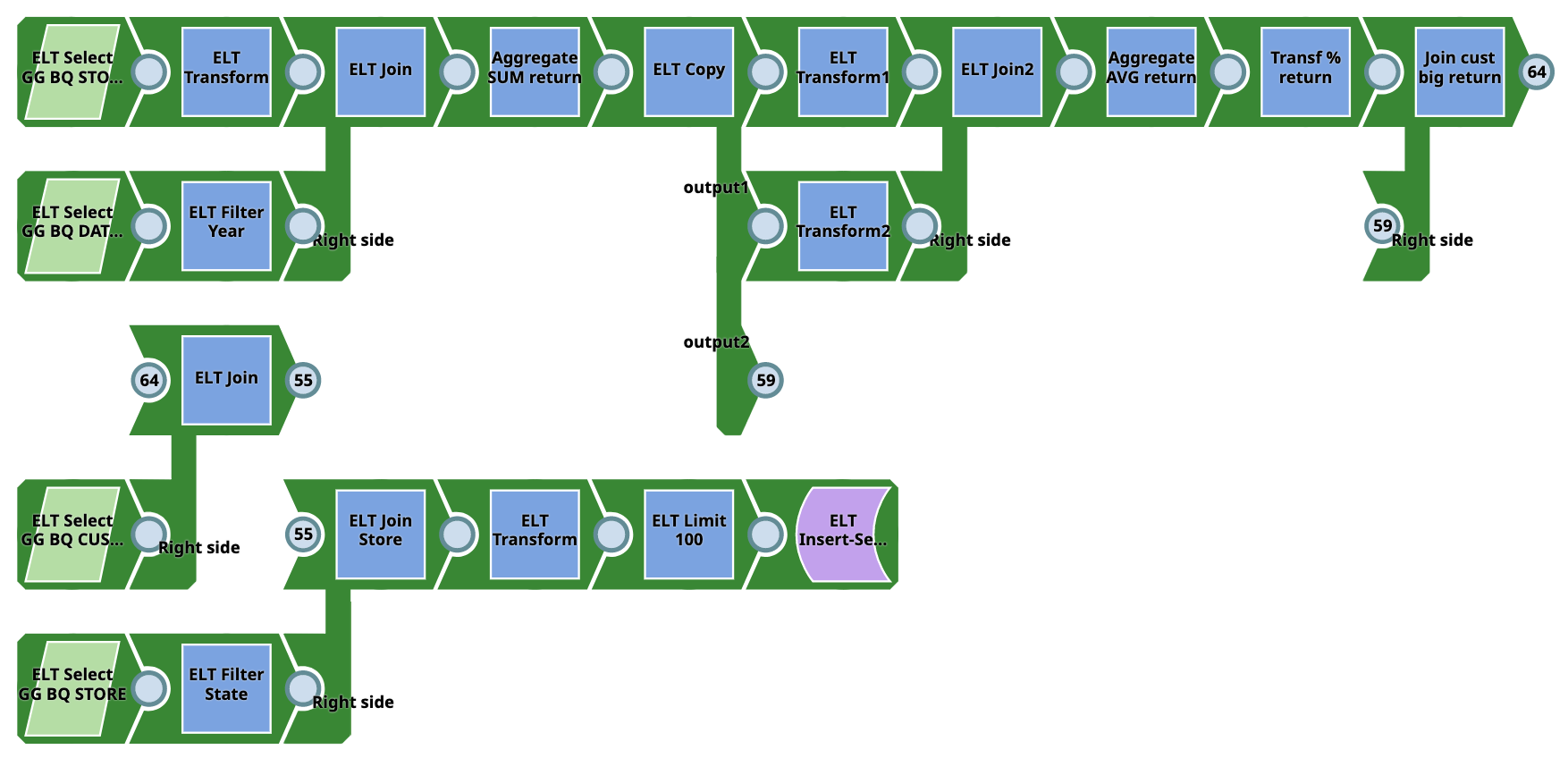
Pipeline 2 (S3 to BQ)
This Pipeline does not require source tables as they are created on Google BigQuery on the fly using ELT Load snap and the output target tables are created on Google BigQuery. The Pipeline converts data from CSV (S3 location) to database tables and can be used for a wide variety of complex tasks. It requires table schema setup and a Google BigQuery account is required. Users need not require SQL experience for this Pipeline.
You can download the Pipeline from here
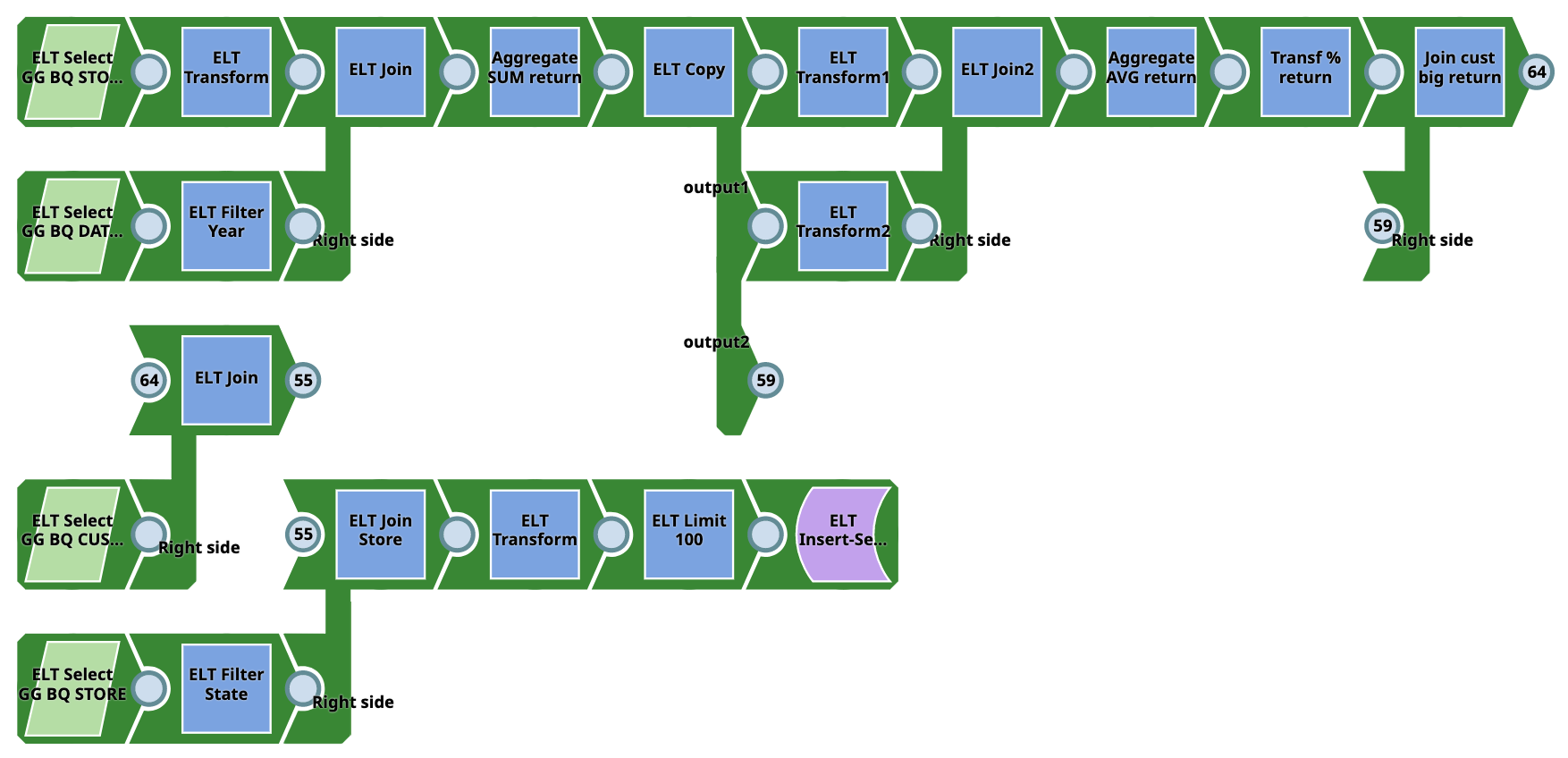
Pipeline 3 (BQ to BQ)
The Pipeline writes from Google BigQuery to Google BigQuery. However, source tables must be present in the Google BigQuery before execution. Users do not require SQL experience. The Pipeline can be used for a wide variety of complex tasks.
You can download the Pipeline from here
Source Data Sets Details:
File Name | Volume | Rows |
|---|---|---|
| STORE_RETURNS_DEMO_3.csv | 128K | 1000 |
| STORE_DEMO_3.csv | 128K | 1000 |
| CUSTOMER_DEMO_3.csv | 707K | 5000 |
| STORE_DEMO_3.csv | 271K | 1000 |
Have feedback? Email documentation@snaplogic.com | Ask a question in the SnapLogic Community
© 2017-2024 SnapLogic, Inc.