Parquet Reader
- Kalpana Malladi
- Aparna Tayi (Unlicensed)
- Lakshmi Manda
In this article
Overview
Parquet Reader is a Read-type Snap that reads Parquet files from HDFS (Hadoop Distributed File System), ADL (Azure Data Lake), ABFS (Azure Blob File Storage), WASB (Windows Azure Storage Blob), or S3 and converts the data into documents. You can also use this Snap to read the structure of Parquet files in the SnapLogic metadata catalog.
This Snap supports HDFS (Hadoop Distributed File System), ADL (Azure Data Lake), ABFS (Azure Blob File Storage), WASB (Windows Azure Storage Blob), and S3 protocols.

Behavior Change
When you select the Use datetime types checkbox in the Parquet Reader Snap, the Snap displays the LocalDate and DateTime in the output for INT32 (DATE) and INT64 (TIMESTAMP_MILLIS) columns. When you deselect this checkbox, the columns retain the previous datatypes and display string and integer values in the output.
Prerequisites
Access and permission to read from HDFS, ADL (Azure Data Lake), ABFS (Azure Data Lake Storage Gen 2), WASB (Azure storage), or AWS S3.
Support for Ultra Pipelines
Works in Ultra Tasks.
Limitations
None.
Known Issues
The upgrade of Azure Storage library from v3.0.0 to v8.3.0 has caused the following issue when using the WASB protocol:
When you use invalid credentials for the WASB protocol in Hadoop Snaps (HDFS Reader, HDFS Writer, ORC Reader, Parquet Reader, Parquet Writer), the pipeline does not fail immediately, instead it takes 13-14 minutes to display the following error:
reason=The request failed with error code null and HTTP code 0. , status_code=error
SnapLogic® is actively working with Microsoft®Support to resolve the issue.
Learn more about Azure Storage library upgrade.
Snap Input and Output
| Input/Output | Type of View | Number of Views | Examples of Upstream and Downstream Snaps | Description |
|---|---|---|---|---|
| Input | Document | Min: 0 Max: 1 |
| [None] |
| Output | Document | Min: 1 Max: 1 |
| A document with the columns and data of the Parquet file. |
Account
This Snap uses account references created on the Accounts page of SnapLogic Manager to handle access to this endpoint. This Snap supports several account types, as listed below.
| Protocol | Account Types | Documentation | Setting |
|---|---|---|---|
| S3 | Amazon AWS | AWS S3 | Access-key ID, Secret key |
| S3 | AWS IAM Role | AWS S3 | Enable IAM Role checkbox |
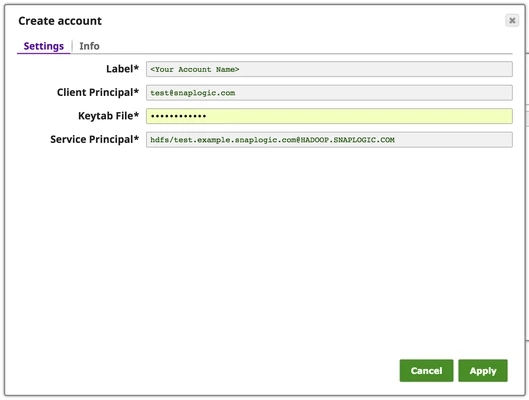
| HDFS | Kerberos | Kerberos | Client Principal, Keytab file, Service Principal |
| WASB | Azure Blob Storage | Azure Storage | Account name, Primary access key |
| WASBs | Azure Blob Storage | Azure Storage | Account name, Primary access key |
| ADL | Azure Data Lake | Azure Data Lake | Tenant ID, Access ID, Security Key |
| ADFS | Azure Data Lake | Azure Data Lake | Tenant ID, Access ID, Security Key |
The security model configured for the Groundplex (SIMPLE or KERBEROS authentication) must match the security model of the remote server. Due to limitations of the Hadoop library we are only able to create the necessary internal credentials for the configuration of the Groundplex.
Snap Settings
Field | Field Type | Description | ||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
Label* | String | Specify a unique name for the Snap. You can modify this to be more specific, especially if you have more than one of the same Snap in your Pipeline. Default Value: Parquet Reader | ||||||||||||||||||||||||||||||||||
Directory | String/Expression | Specify a directory in HDFS to read data. All files within the directory must be Parquet formatted. We support file storage systems as below:
When you use the ABFS protocol to connect to an endpoint, the account name and endpoint details provided in the URL override the corresponding values in the Account Settings fields. With the ABFS protocol, SnapLogic creates a temporary file to store the incoming data. Therefore, the hard drive where the JCC is running should have enough space to temporarily store all the account data coming in from ABFS. SnapLogic automatically appends "azuredatalakestore.net" to the store name you specify when using Azure Data Lake; therefore, you do not need to add 'azuredatalakestore.net' to the URI while specifying the directory. | ||||||||||||||||||||||||||||||||||
| File Filter | String/Expression | A glob to select only certain files or directories. The glob pattern is used to display a list of directories or files when the Suggest icon is pressed in the Directory or File property. The complete glob pattern is formed by combining the value of the Directory property and the Filter property. If the value of the Directory property does not end with "/", the Snap appends one so that the value of the Filter property is applied to the directory specified by the Directory property. The following rules are used to interpret glob patterns:
Default Value: * | ||||||||||||||||||||||||||||||||||
| File | String/Expression | Required for standard mode. Filename or a relative path to a file under the directory given in the Directory property. It should not start with a URL separator "/". The File property can be a JavaScript expression which will be evaluated with values from the input view document. When you press the Suggest icon, it will display a list of regular files under the directory in the Directory property. It generates the list by applying the value of the Filter property. Example:
Both the Parquet Reader and Parquet Writer Snaps have the ability to read compressed files. The compression codecs that are currently supported are: Snappy, GZIP, and LZO. To use LZO compression, you must explicitly enable the LZO compression type on the cluster (as an administrator) for the Snap to recognize and run the format. For more information, see Data Compression. For detailed guidance on setting up LZO compression, see Clourdera documentation on Installing the GPL Extras Parcel. Many compression algorithms require both Java and system libraries and will fail if the latter is not installed. If you see unexpected errors, ask your system administrator to verify that all the required system libraries are installed–they are typically not installed by default. The system libraries will have names such as liblzo2.so.2 or libsnappy.so.1 and will probably be located in the /usr/lib/x86_64-linux-gnu directory. | ||||||||||||||||||||||||||||||||||
User Impersonation | Checkbox | Hadoop allows you to configure proxy users to access HDFS on behalf of other users; this is called impersonation. When user impersonation is enabled on the Hadoop cluster, any jobs submitted using a proxy are executed with the impersonated user's existing privilege levels rather than those of a superuser.
The HDFS Writer Snap supports Azure storage account, Azure Data Lake account, Kerberos account, or no account. When an account is configured with the HDFS Writer Snap, User impersonation setting has no impact on the accounts except Kerberos Account. Default Value: Not selected For encryption zones, use user impersonation. | ||||||||||||||||||||||||||||||||||
| Ignore empty file | Checkbox | Select this checkbox to ignore an empty file, that is the Snap does nothing.
Default Value: Selected | ||||||||||||||||||||||||||||||||||
| Use old data format | Checkbox | Deselect this checkbox to read complex data types or nested schema such as LIST, and MAP. Null values are skipped when doing so. Default Value: Selected | ||||||||||||||||||||||||||||||||||
| int96 As Timestamp | Enabled when you deselect Use old data format checkbox. Select this checkbox to enable the Snap to convert int96 values to timestamp strings of a specified format in Date Time Format field. If you deselect this checkbox, the Snap shows values for int96 data type as 12-byte BigInteger objects. Default Value: Deselected | |||||||||||||||||||||||||||||||||||
| Use datetime types | Select this checkbox to enable the Snap to display LOCALDATE type for int32(DATE) and DATETIME type for int64(TIMESTAMP_MILLIS) in the output. When deselected, the columns retain the previous datatypes. Default Value: Deselected | |||||||||||||||||||||||||||||||||||
| Date Time Format | Enabled when you select int96 As Timestamp checkbox. Enter a date-time format of your choice for int96 data-type fields (timestamp and time zone). For more information about valid date-time formats, see DateTimeFormatter. The int96 data type can support up to nanosecond accuracy. Default Value: yyyy-MM-dd'T'HH:mm:ss.SSSX | |||||||||||||||||||||||||||||||||||
| Azure SAS URI Properties | Shared Access Signatures (SAS) properties of the Azure Storage account. | |||||||||||||||||||||||||||||||||||
| SAS URI | String/Expression | Specify the Shared Access Signatures (SAS) URI that you want to use to access the Azure storage blob folder specified in the Azure Storage Account. You can get a valid SAS URI either from the Shared access signature in the Azure Portal or by generating one from the SAS Generator Snap. If the SAS URI value is provided in the Snap settings, then the settings provided in the account (if any account is attached) are ignored. | ||||||||||||||||||||||||||||||||||
Snap Execution | Dropdown list | Select one of the following three modes in which the Snap executes:
Default Value: Validate & Execute Example: Execute Only | ||||||||||||||||||||||||||||||||||
Troubleshooting
Writing to S3 files with HDFS version CDH 5.8 or later
When running HDFS version later than CDH 5.8, the Hadoop Snap Pack may fail to write to S3 files. To overcome this, make the following changes in the Cloudera manager:
- Go to HDFS configuration.
- In Cluster-wide Advanced Configuration Snippet (Safety Valve) for core-site.xml, add an entry with the following details:
- Name: fs.s3a.threads.max
- Value: 15
- Click Save.
- Restart all the nodes.
- Under Restart Stale Services, select Re-deploy client configuration.
- Click Restart Now.
Temporary Files
During execution, data processing on Snaplex nodes occurs principally in-memory as streaming and is unencrypted. When larger datasets are processed that exceeds the available compute memory, the Snap writes Pipeline data to local storage as unencrypted to optimize the performance. These temporary files are deleted when the Snap/Pipeline execution completes. You can configure the temporary data's location in the Global properties table of the Snaplex's node properties, which can also help avoid Pipeline errors due to the unavailability of space. For more information, see Temporary Folder in Configuration Options.Examples
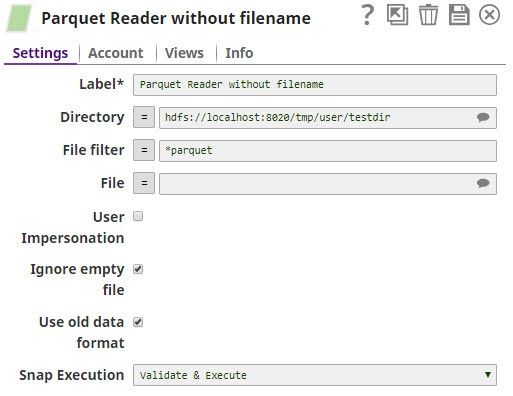
Displaying Files in a Directory Using the Parquet Reader
In the below pipeline, the Parquet Reader Snap reads the documents from a directory path with a filter *.parquet. Since the file name is not provided, the Snap displays all the files with the applied filter on that directory.
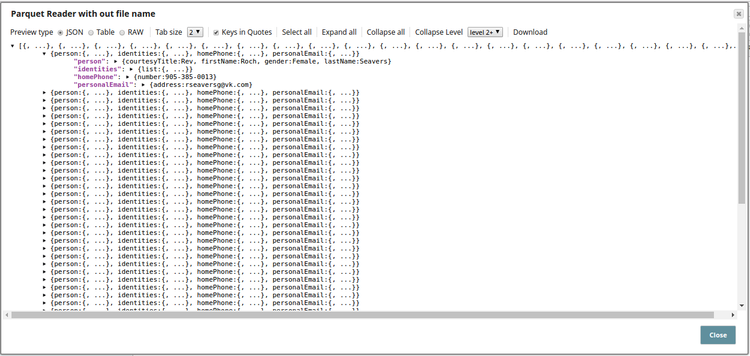
Successful execution of the Pipeline displays the output preview as follows:
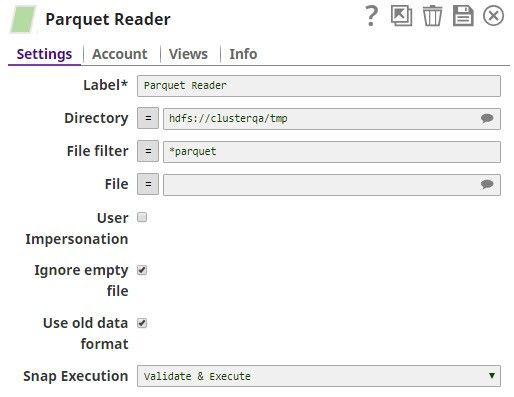
Reading from HDFS
A Parquet Reader configured to read from a local instance of HDFS. The path it reads from is /tmp/test.parquet.
Reading from S3
Reading a Parquet file from AWS S3 requires an S3 account.
- Create an S3 account or use an existing one.
- If it is a regular S3 account, name the account and supply the Access-key ID and Secret key.
If the account is an IAM role-enabled Account:
Select the IAM role checkbox.
Leave the Access-key ID and Secret key blank.
The IAM role properties are optional. You can leave them blank.
To use IAM Role Properties, ensure to select the IAM Role check box.
- Within the Parquet Snap, use a valid S3 path for the directory in the format of:
s3://<bucket name>/<key name prefix>
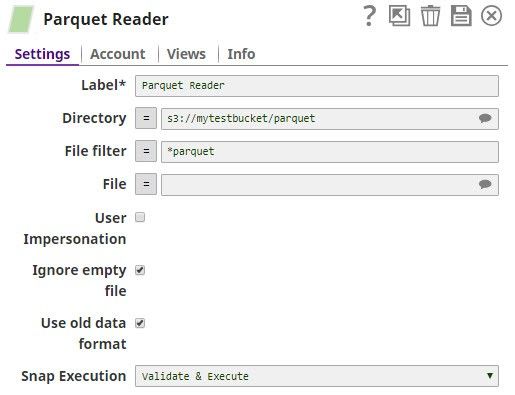
Reading from Kerberos
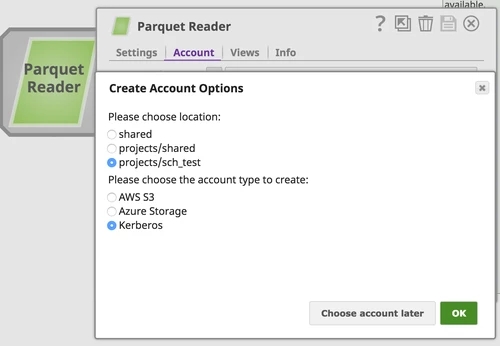
Read from Kerberosize Cluster requires Kerberos account as below:
Reading Schema Information from the Catalog Query Snap
In this example, we shall query a SnapLogic metadata catalog table partition to retrieve the schema used and then use the Parquet Reader Snap to read the retrieved schema.
Download this pipeline
Understanding the Pipeline
We create the pipeline as shown below:
The Catalog Query Snap
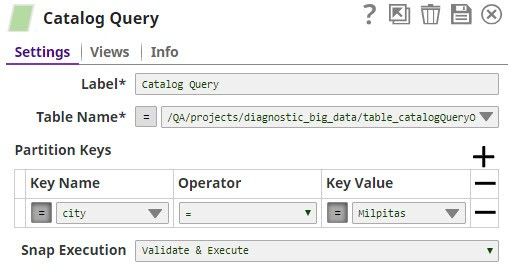
In this pipeline, the Catalog Query Snap retrieves metadata information from the metadata catalog table and makes it available for the next Snap. We configure the Snap to pick up the table from a location in SLDB; we also specify partition keys (city=Milpitas) to identify a precise partition in the table, as shown below:
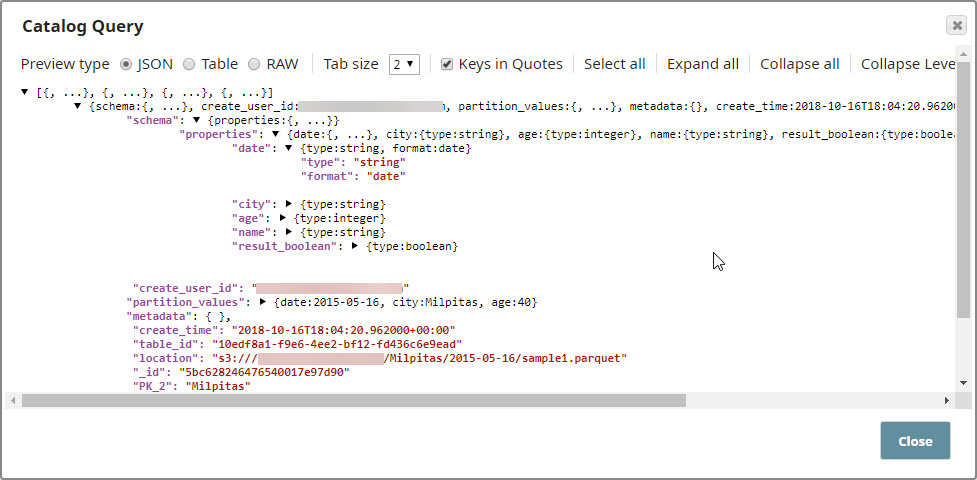
On execution the Snap retrieves the metadata associated with the specified partition in the concerned table, as shown below:
The Parquet Reader Snap
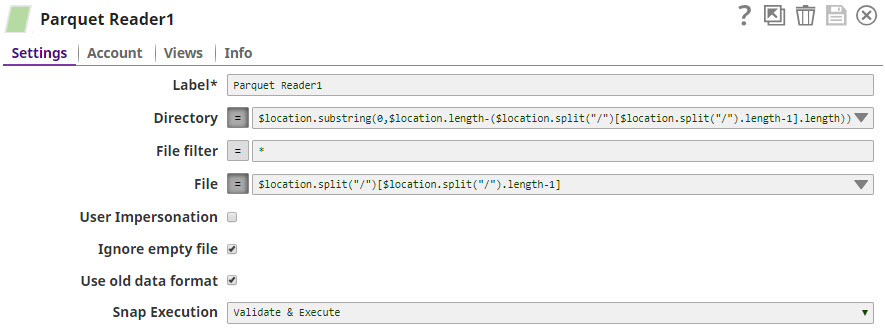
We now want to extract the schema information from the Catalog Query Snap's output. To do so, we insert a Parquet Reader Snap into the pipeline, as shown below:
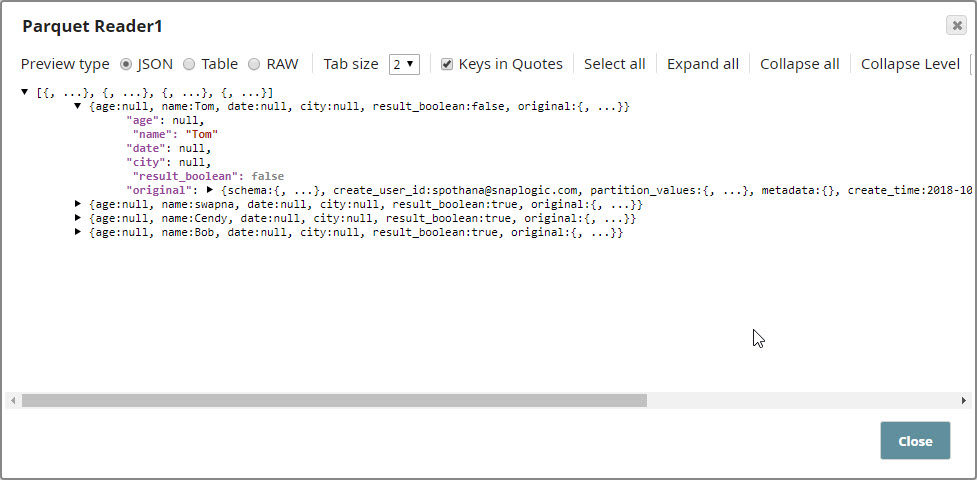
Once this Snap is executed, it identifies and retrieves the schema information from the Catalog Query Snap, as shown below:
Download this pipeline
Downloads
Important steps to successfully reuse Pipelines
- Download and import the pipeline into the SnapLogic application.
- Configure Snap accounts as applicable.
- Provide pipeline parameters as applicable.
See Also
Have feedback? Email documentation@snaplogic.com | Ask a question in the SnapLogic Community
© 2017-2024 SnapLogic, Inc.