ELT DLP Account
- Anand Vedam
- Gouri Bhagchandani (Deactivated)
- Shilpa (Deactivated)
In this article
Overview
You can use the ELT Database Account to connect ELT Snaps with Databricks Lakehouse Platform (DLP) target instance. This account enables you to write transformed data to a target DLP instance hosted in a Microsoft Azure cloud location. The cloud location where the database is hosted is indicated in the JDBC URL for DLP—jdbc:spark://<your_instance_code>.cloud.databricks.com for AWS or jdbc:spark://<your_instance_code>.azuredatabricks.net for Microsoft Azure.
The ELT Snap Pack does not support mixed accounts from different types of databases in the same Pipeline. For example, a Pipeline in which some Snaps are connecting to the DLP instance cannot have other Snaps connecting to the Snowflake database.
Prerequisites
- A valid DLP account.
Certified JDBC JAR File: databricks-jdbc-2.6.29.jar
Using Alternate JDBC JAR File Versions
We recommend that you let the ELT Snaps use this JAR file version. However, you may use a different JAR file version of your choice.
Limitations
- With the basic authentication type for Databricks Lakehouse Platform (DLP) reaching its end of life on July 10, 2024, SnapLogic ELT pipelines designed to use this authentication type to connect to DLP instances would cease to succeed. We recommend that you reconfigure the corresponding Snap accounts to use the Personal access tokens (PAT) authentication type.
Known Issues
- When you use the auto-fill feature in the Google Chrome browser to fill ELT Snap account credentials—such as user names, passwords, client secrets, auth codes and tokens, secret keys, and keystores, the accounts, and hence the Pipelines fail. This is because the browser overwrites the field values with its own encrypted values that the SnapLogic Platform cannot read. SnapLogic recommends that you do not auto-save your Snap account credentials in the Chrome browser, delete any credentials that the browser has already saved for elastic.snaplogic.com, and then perform ONE of the following actions:
- Option 1: Click
 that appears in the address bar after you submit your login credentials at elastic.snaplogic.com, and then click Never.
that appears in the address bar after you submit your login credentials at elastic.snaplogic.com, and then click Never. - Option 2: Disable the Offer to save Passwords option at chrome://settings/passwords while working with your SnapLogic Pipelines. If you disable this option, your Chrome browser will not remember your passwords on any other website.
- Option 1: Click
Due to an issue with DLP, aborting an ELT Pipeline validation (with preview data enabled) causes only those SQL statements that retrieve data using bind parameters to get aborted while all other static statements (that use values instead of bind parameters) persist.
For example,
select * from a_table where id = 10will not be aborted whileselect * from test where id = ?gets aborted.
To avoid this issue, ensure that you always configure your Snap settings to use bind parameters inside its SQL queries.
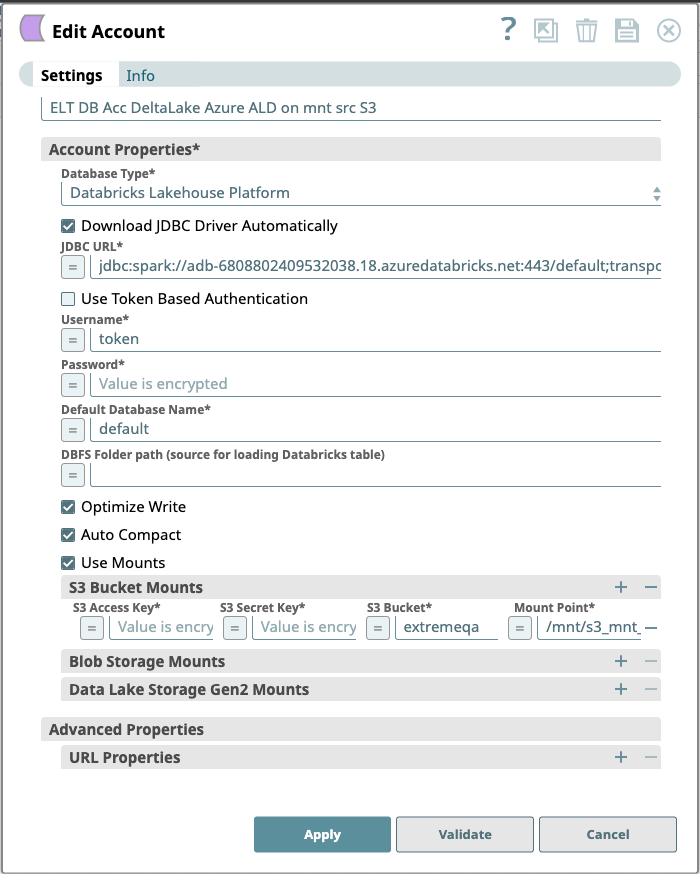
Account Settings
Asterisk ( * ) indicates a mandatory field.
Suggestion icon (
 ) indicates a list that is dynamically populated based on the configuration.
) indicates a list that is dynamically populated based on the configuration.Expression icon (
 ) indicates whether the value is an expression (if enabled) or a static value (if disabled). Learn more about Using Expressions in SnapLogic.
) indicates whether the value is an expression (if enabled) or a static value (if disabled). Learn more about Using Expressions in SnapLogic.Add icon (
 ) indicates that you can add fields in the fieldset.
) indicates that you can add fields in the fieldset.Remove icon (
 ) indicates that you can remove fields from the fieldset.
) indicates that you can remove fields from the fieldset.
| Parameter | Field Dependency | Description | ||
|---|---|---|---|---|
| Label* | None. | Required. Unique user-provided label for the account. Default Value: N/A Example: ELT DLP Azure Account AD ON | ||
| Account Properties* | Use this field set to configure the information required to establish a JDBC connection with the account. This field set consists of the following fields:
| |||
| Database Type* | None. | Select the target data warehouse into which the queries must be loaded, that is Databricks Lakehouse Platform. This activates the following fields:
Default Value: N/A Example: Databricks Lakehouse Platform | ||
| Download JDBC Driver Automatically | None. | Select this checkbox to allow the Snap account to download the certified JDBC Driver for DLP. The following fields are disabled when this checkbox is selected.
To use a JDBC Driver of your choice, clear this checkbox, upload (to SLDB), and choose the required JAR files in the JDBC JAR(s) and/or ZIP(s): JDBC Driver field. Use of Custom JDBC JAR version You can use a different JAR file version outside of the recommended listed JAR file versions. Spark JDBC and Databricks JDBC If you do not select this checkbox and use an older JDBC JAR file (older than version 2.6.25), ensure that you use:
Default Value: Not Selected Example: Selected | ||
| JDBC JAR(s) and/or ZIP(s): JDBC Driver | Required when the Download JDBC Driver Automatically checkbox is not selected. | Upload the JDBC driver and other JAR files that you want to use into SLDB. Click Default Value: N/A Example: SimbaSparkJDBC42-2.6.21.1021.jar | ||
| JDBC driver class* | Required when the Download JDBC Driver Automatically checkbox is not selected. | Specify the driver class to use for your application. We recommend that you use com.simba.spark.jdbc.Driver for DLP, as other classes and methods may change due to future enhancements. Default Value: N/A Example: com.simba.spark.jdbc.Driver | ||
| JDBC URL* | None. | Enter the JDBC driver connection string that you want to use in the syntax provided below, for connecting to your DLP instance. See Microsoft's JDBC and ODBC drivers and configuration parameters for more information.
Spark JDBC and Databricks JDBC If you do not choose the Download JDBC Driver Automatically checkbox and use an older JDBC JAR file (older than version 2.6.25), ensure that you use:
Alternatively, you can make use of the Username, Password, and Database Name fields, along with the Advanced Properties > URL Properties field set to provide the parameters required for building your JDBC URL. See Passing your JDBC URL for more information. Avoid passing Password inside the JDBC URL If you specify the password inside the JDBC URL, it is saved as it is and is not encrypted. We recommend passing your password using the Password field provided, instead, to ensure that your password is encrypted. Default Value: N/A Example: jdbc:spark://adb-2409532680880038.18.azuredatabricks.net:443/default;transportMode=http;ssl=1;httpPath=sql/protocolv1/o/2409532680880038/0326-212833-drier754;AuthMech=3; | ||
Use Token Based Authentication | Database Type is Databricks Lakehouse Platform | Select this checkbox to use token-based authentication for connecting to the target database (DLP) instance. Activates the Token field. Default value: Selected Example: Not selected | ||
| Token* | When Use Token Based Authentication checkbox is selected. | Enter the token value for accessing the target database/folder path. Default value: N/A Example: <Encrypted> | ||
| Default Database Name* | None. | Enter the name of the database to use by default. This database is used if you do not specify one in the ELT Select, ELT Insert-Select, or ELT Merge Into Snaps. Default value: N/A Example: EMPLOYEEDB | ||
| DBFS Folder path (source for loading Databricks table) | Database Type is Databricks Lakehouse Platform | Required for ELT Load Snap. Specify the fully qualified path to a target folder in your DBFS instance. It should begin with / which denotes the DBFS Root folder. If DBFS path has a mount point included (to a folder in S3 or Azure Blob Storage or ADLS Gen2 Storage), this field assumes that the specified external data folder is mounted on to DBFS path already. For example, if /mnt/mnt_point _to_s3/csv is the specified path to DBFS folder, this field assumes that you have already created Default value: N/A Example: /my_DBFS/mounted0408_folder | ||
| Optimize Write | Database Type is Databricks Lakehouse Platform. | Select this checkbox to dynamically optimize the Apache Spark partition sizes based on the actual data. If selected, DLP attempts to write 128 MB files (this is an approximate size and can vary depending on dataset characteristics) for each table partition. Default Value: Not Selected Example: Selected | ||
| Auto Compact | Database Type is Databricks Lakehouse Platform. | Select this checkbox to allow DLP to compact small files being written into a Delta table. Default Value: Not Selected Example: Selected | ||
| Use Mounts | Checkbox | If this checkbox is selected, it provides three different sources to mount DBFS. | ||
| S3 Bucket Mounts | Use this field set to provide the information required to configure the S3 Database account. It consists of the following fields:
| |||
S3 Access Key | String | Specify the S3 access key ID that you want to use for AWS authentication. Default Value: N/A | ||
| S3 Secret Key | String | Specify the S3 secret key associated with the S3 Access-ID key listed in the S3 Access-key ID field. Default Value: N/A | ||
| S3 Bucket | String | Specify the name of the S3 bucket that you want to use for staging data to Snowflake. Default Value: N/A | ||
Mount Point | String | The directory within DBFS to mount the source. Data written to mount point paths ( In the case of ELT Load Snap (DataBricks only) the priority of the loading from paths is as follows: All DBFS mount points should start with /mnt/ dir within the DBFS (example: /mnt/s3/some_bucket) Learn more at Defining mount points. | ||
| Blob Storage Mounts | Use this field set to provide the information required to configure the blob storage mounts. It consists of the following fields:
| |||
Azure Blob Account Name | Database Type is Databricks Lake Platform. External Location is Blob Storage or Azure Data Lake Gen2. | Enter your Account name to access the selected Azure external storage location. You must configure this field if you want to use the ELT Load Snap. Default value: N/A Example: adlsgen2v02 | ||
Azure Blob Storage Key | Database Type is Databricks Lake Platform. External Location is Blob Storage or Azure Data Lake Gen2. Azure Auth Type is Shared Access Signature, Managed Identity, or Service Principals. | Enter the storage access key value corresponding to the Azure account mentioned in Storage Account field. See COPY INTO (Transact-SQL) in Microsoft Docs for more information on the expected values for this field. This field is needed only when you want to define the File Name Pattern in the ELT Load Snap to locate and read the file/s from the Azure Folder path. Else, leave it blank. Default value: N/A Example: ufv!befDIuf#fnb$KH&_hweuf | ||
Container Name | Database Type is Databricks Lake Platform. External Location is Blob Storage or Azure Data Lake Gen2. | Enter the name of the container in the Azure storage account. Azure Container does not apply to the Redshift database. Default value: N/A Example: hrdepartment | ||
Mount Point | String | The directory within DBFS to mount the source. Data written to mount point paths ( In the case of ELT Load Snap (Databricks only) the priority of the loading from paths is as follows: All DBFS mount points should start with /mnt/ dir within the DBFS (example: /mnt/s3/some_bucket) Learn more at Defining mount points. | ||
Data Lake Storage Gen2 Mounts | Use this field set to provide the information required to configure the Data Lake Storage Gen2 Mounts. It consists of the following fields:
| |||
Application Id | Database Type is Databricks Lake Platform. External Location is Blob Storage or Azure Data Lake Gen2. | Enter the name of theapplication (client) ID for the Azure Active Directory application that you want to configure. Default value: N/A Example: 635f1f0e-2378bd-412683734777efa9ef | ||
ADLS Gen2 Oauth2 Secret Key | Database Type is Databricks Lake Platform. External Location is Blob Storage or Azure Data Lake Gen2. | Enter the Oauth2 secret key which is part of ADLS Gen2 account authentication in the Azure portal. Default value: N/A Example: 7ed4587-a77f-43bf-94c5dfg | ||
ADLS Gen2 Tenant Id | Database Type is Databricks Lake Platform. External Location is Blob Storage or Azure Data Lake Gen2. | Enter the Tenant ID obtained after creating the application in the Azure portal. Default value: N/A Example: 2060aaafe-89d9-9514-eac46338ec05 | ||
ADLS Gen2 Account Name | Database Type is Databricks Lake Platform. External Location is Blob Storage or Azure Data Lake Gen2. | Enter the name of the account. Default value: N/A Example: Gen2 account name | ||
ADLS Gen2 Container Name | Database Type is Databricks Lake Platform. External Location is Blob Storage or Azure Data Lake Gen2. | Enter the name of the container in the Azure storage account. Azure Container does not apply to the Redshift database. Default value: N/A Example: hrdepartment | ||
| Mount Point | String | The directory within DBFS to mount the source. Data written to mount point paths ( In the case of ELT Load Snap (DataBricks only) the priority of the loading from paths is as follows: All Dbfs mountpoints should start with /mnt/ dir within dbfs (example /mnt/s3/some_bucket) Learn more at Defining mount points. | ||
| Advanced Properties | Other parameters that you want to specify as URL properties. This field set consists of the following fields:
| |||
| URL Properties | None. | The account parameter's name and its corresponding value. Click + to add more rows. Add each URL property-value pair in a separate row. Specify the name of the parameter in the URL Property Name field and its value in the URL Property Value field. Default value: N/A Example: MAX_CONCURRENCY_LEVEL: 3 | ||
Click Validate after entering the required details to ensure that all fields have been filled accurately. Click Apply to save the settings.
Account Validation when using Pipeline parameters
If you have used Pipeline parameters or expressions to define values for the account fields above, the account validation (done by clicking the Validate button) is not supported. However, the Snaps that use this account may connect to the endpoint successfully depending on the accuracy and validity of the expressions and parameters used.
Passing your JDBC URL
Order of Precedence
The parameter values for the URL used to connect to your target database are governed by the following order of precedence:
- JDBC URL field
- Snap Properties (including Advanced Properties)
- Default values
Default Properties set internally
No properties are passed in the URL internally for DLP, by default.
Specific Scenarios
When setting default values for the Database Name, Username, and Password fields:
As a best practice, ensure that the Default Database Name provided in the Snap's properties and the database name in the JDBC URL field match.
Else, make sure that both the database names exist.
However, the username and password from the JDBC URL take precedence over the values provided in the respective fields.
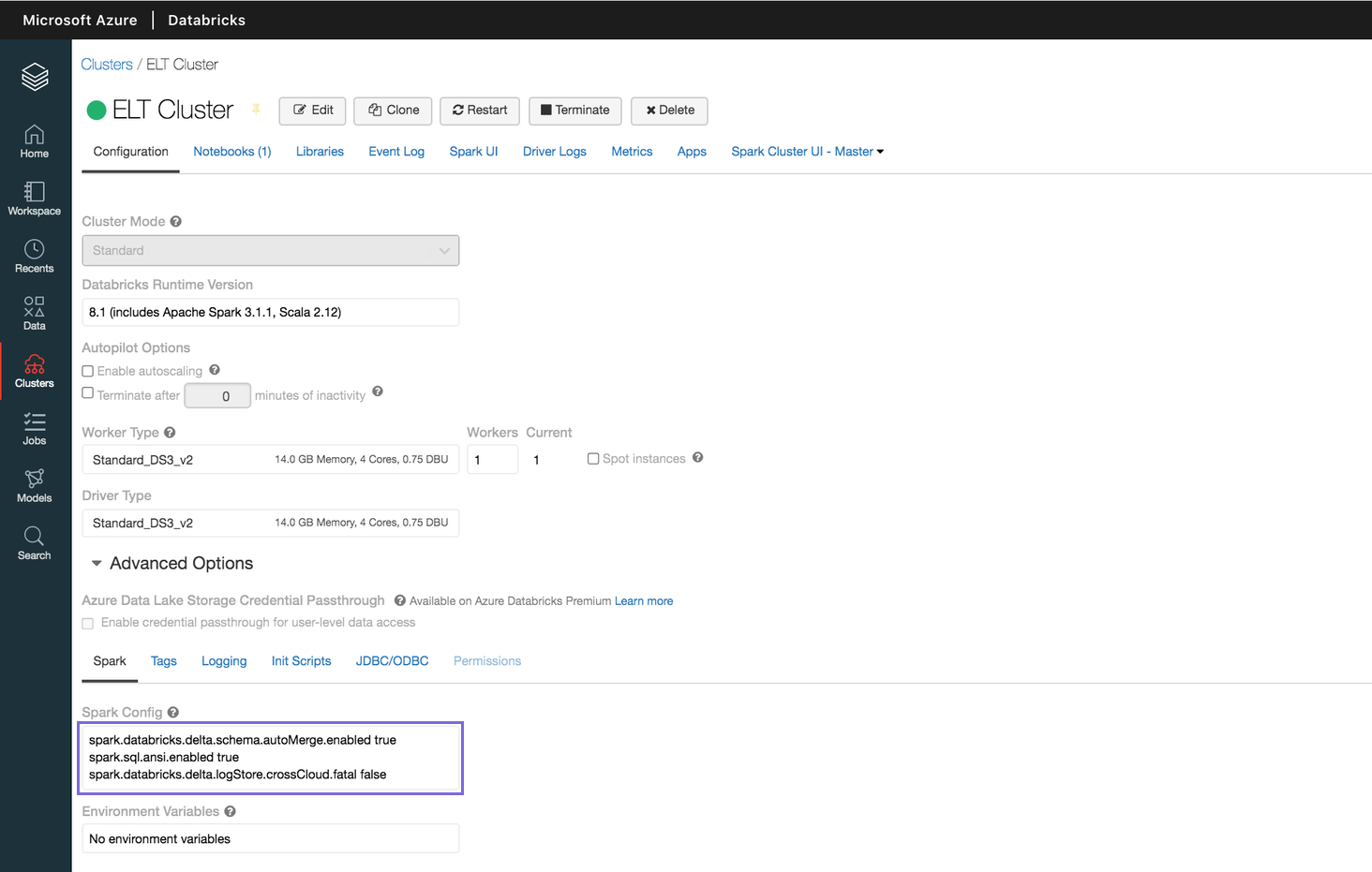
Spark settings required for supporting ELT on DLP
Ensure to configure the following Spark configuration properties/settings for your Azure Databricks cluster. Refer Configuring Clusters for Azure Databricks for information on defining Spark Configuration Properties.
Spark Config Property Name | Expected Property Value |
|---|---|
spark.sql.ansi.enabled | true |
spark.databricks.delta.logStore.crossCloud.fatal | false |
spark.databricks.delta.schema.autoMerge.enabled | true |
spark.sql.legacy.timeParserPolicy | LEGACY |
The following image depicts the Spark configuration properties defined for a sample DLP instance.
Defining mount points
You can use the following external (cloud storage) buckets/containers and their folder paths for reading, writing, and loading Databricks delta tables.
AWS S3 (accessed using S3A protocol)
Azure Blob Storage (accessed using WASBS protocol)
ADLS Gen 2 (accessed using ABFSS protocol)
To enable Databricks runtime to access externally located data files from the Databricks cluster, you need to mount your bucket/container on to DBFS path. Once the ‘mount point’ is created through a cluster, the corresponding DBFS path allows accessing the external data location (cloud storage).
Security considerations
The mount point is only a pointer to your cloud storage location, so the data is never synced locally (i.e data is never moved into DBFS)
Once a mount point is created through a Python Notebook attached to a cluster, users of that cluster can immediately access the mount point.
To use the mount point in another running cluster, you must run
dbutils.fs.refreshMounts()on that running cluster to make the newly created mount point available.All users have read and write access to all the objects in the buckets/containers mounted to DBFS.
Azure Blob storage supports three blob types: block, append, and page. You can only mount block blobs to DBFS.
Mount an S3 Bucket on DBFS Path
Use Databricks Python Notebook to run the
fsutils.mount()command with your access credentials, as follows:- Verify that the mount point is created by running the
display(dbutils.fs.mounts())command.
Mount an Azure Blob Storage’s Container on DBFS Path
Use Databricks Python Notebook to run the
fsutils.mount()command with your access credentials, as follows:- Verify that the mount point is created by running the
display(dbutils.fs.mounts())command.
Mount an ADLS Gen2 Container on DBFS Path
The steps below assume you have created the OAuth2 application to access your containers.
Use Databricks Python Notebook to run the
fsutils.mount()command with your access credentials, as follows:Optionally, you can add a
<directory-name>to the source URI of your mount point.- Verify that the mount point is created by running the
display(dbutils.fs.mounts())command.
To specify the table names from your cloud storage in an ELT Snap:
- Specify the mount point as DBFS Folder path in the Snap's account and specify the table name in the Snap's (Target) Table Name field.
Example:`/mnt/my-mount-pt/input/csv/employee`as DBFS Folder path in the Snap's accountand file_namein the Snap.
OR - Specify the entire mount point path including the table name in the Snap's (Target) Table Name field.
Example:`/mnt/my-mount-pt/input/csv/employee/as (Target) Table Name in the Snap.file_name`
In both the above cases, the DBFS folder paths resolve to the corresponding table name in the cloud storage, as follows:
- s3a://<bucket_name>/delta/<table_name>
- wasbs://<mycontainer>@<mystorageaccountt>.blob.core.windows.net/input/csv/people/<table_name>
- abfss://<mycontainer>@myadlsgen2.dfs.core.windows.net/input/csv/people/<table_name>
Troubleshooting
None.
Example
Configuring the ELT Database Account for Connecting to a DLP Instance
The following Pipeline is designed to extract data from a Parquet file residing in the ADLS Gen2 storage and load it into a new table in the DLP instance.
Snap Settings
The Pipeline uses an ELT Load Snap to load data from a CSV file located in a DBFS location and is configured to perform the following functions.
- Insert new rows from the CSV file (org10.csv) to an existing target table `/mnt/elt/delta01`.
- In the CSV file, there is a header row, and the delimiter is comma (,).
- The Snap shall infer the schema from the source data.
- The Snap is allowed to enforce the copy operation even when an idempotent row exists (loaded earlier).
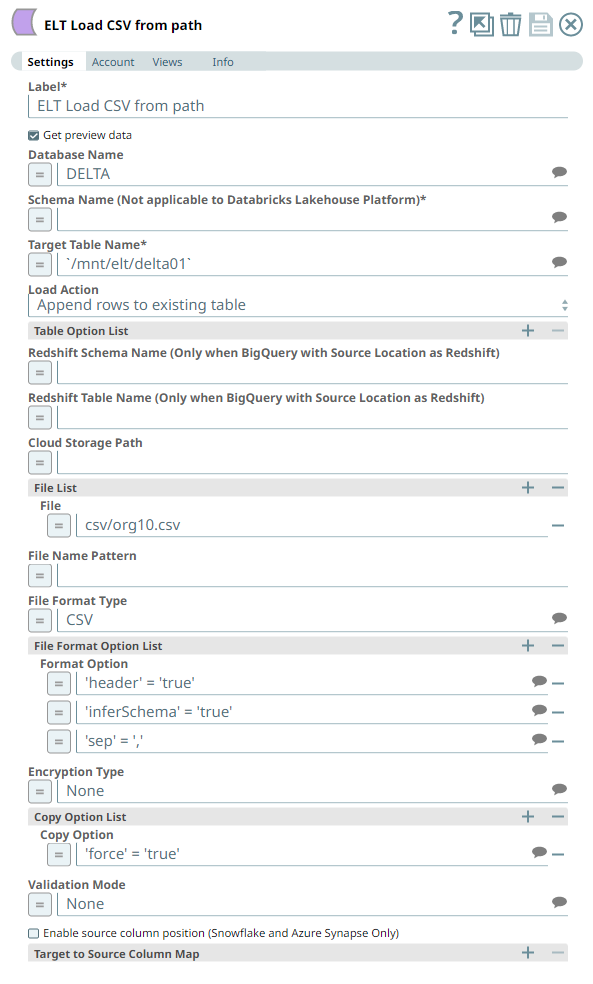
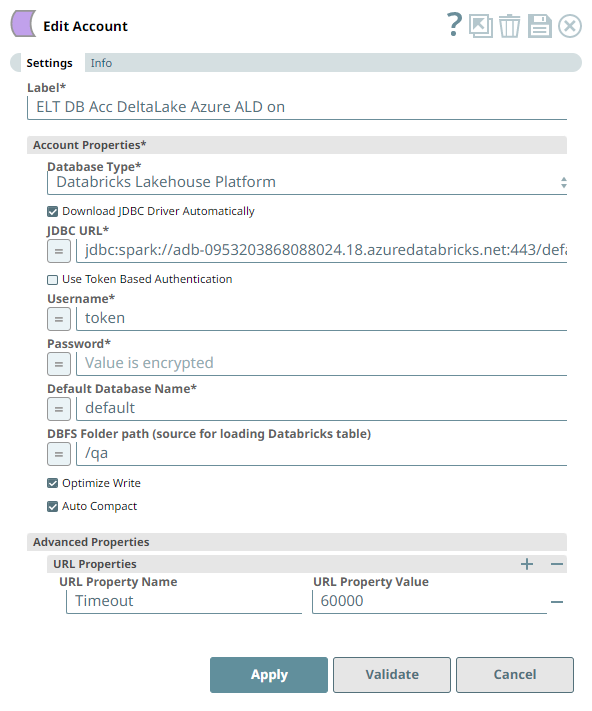
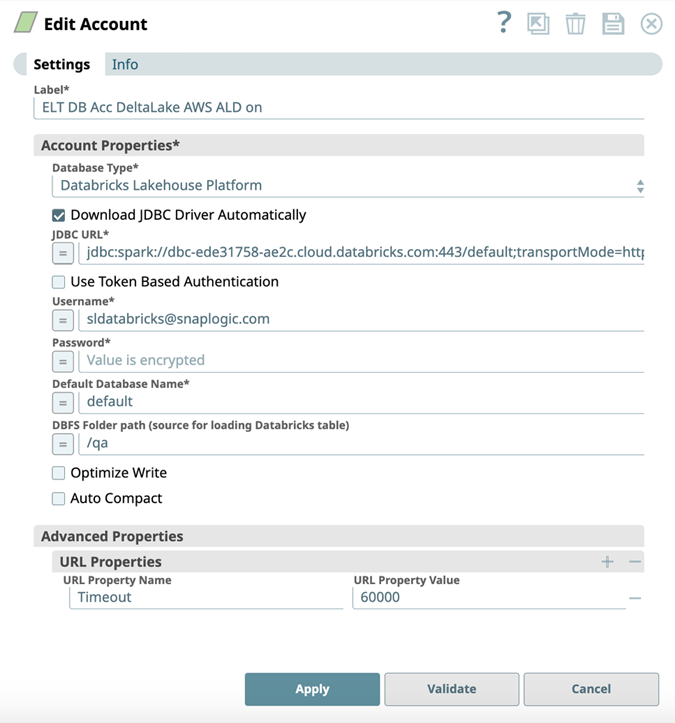
Account Settings
The ELT Load Snap uses an account that:
- Downloads the JDBC driver automatically,
- Optimizes the write operation for efficiency, and
- Performs an auto-compact operation on the source data before loading.
| DLP instance hosted in Microsoft Azure Cloud | DLP instance hosted in AWS Cloud |
|---|---|
 |  |
See Also
Have feedback? Email documentation@snaplogic.com | Ask a question in the SnapLogic Community
© 2017-2025 SnapLogic, Inc.