Handwritten Digit Recognition using Convolutional Neural Networks
- Kalpana Malladi
- Mohammed Iqbal
- Subhajit Sengupta
On this Page
Problem Statement
Papers are replaced by digital documents for various reasons. However, we still see a lot of paper documentation in our daily life. Machines do not have the ability to understand what has been written on those physical papers. Converting handwritten characters to digital characters has been a tough problem in the past and continues to be. We cannot efficiently process those physical documents with computers unless we can convert them to digital documents.
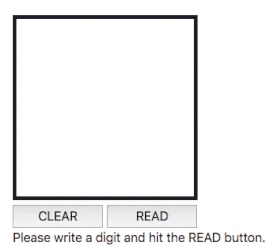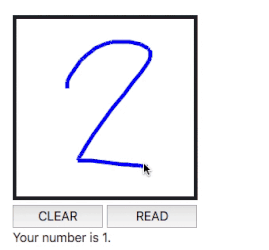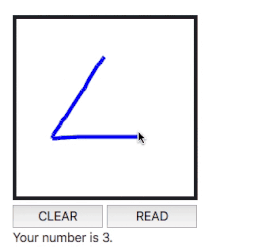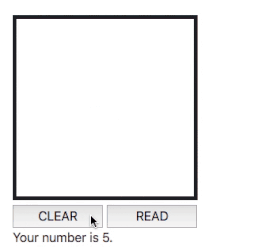
Solution
Researchers in the Machine Learning field have been trying to solve this problem for many years. A lot of state-of-the-art Machine Learning algorithms are able to accurately recognize handwritten characters. In the past few years, Convolutional Neural Networks (CNN) algorithm has been widely used and has shown successful results in various computer vision tasks. It also shows promising results in handwritten character recognition.
In this use case, we train the CNN model on MNIST dataset that consists of 70,000 images containing handwritten digits. Each image is 28 pixels by 28 pixels and contains one handwritten digit. We train the model on 60,000 images and keep 10,000 images for testing.
The live demo is available at our Machine Learning Showcase.
Objectives
- Model Building: Use Remote Python Script Snap from ML Core Snap Pack to deploy python script to train convolutional neural networks model on MNIST dataset.
- Model Testing: Test the model with a sample.
- Model Hosting: Use Remote Python Script Snap from ML Core Snap Pack to deploy python script to host the model and schedule an Ultra Task to provide API.
- API Testing: Use REST Post Snap to send a sample request to the Ultra Task to make sure the API is working as expected.
We will build 4 pipelines: Model Building, Model Testing, Model Hosting, and API Testing; and an Ultra Task to accomplish the above objectives. Each of these pipelines is described in the Pipelines section below.
Pipelines
Model Building
The Remote Python Script Snap downloads the MNIST dataset (we use Keras library to get the dataset), train CNN model, and evaluate the model. We then format the model with the JSON Formatter Snap and save the model on SnapLogic File System (SLFS) using File Writer Snap.

Python Script
Below is the script from the Remote Python Script Snap used in this pipeline. The script has the following 3 main functions:
- snaplogic_init
- snaplogic_process
- snaplogic_final
The first function (snaplogic_init) is executed before consuming input data. The second function (snaplogic_process) is called on each of the incoming documents. The last function (snaplogic_final) is processed after all incoming documents are consumed by snaplogic_process.
We use SLTool.ensure to automatically install required libraries. SLTool class contains useful methods: ensure, execute, encode, decode, etc. In this case, we need keras and tensorflow. The tensorflow 1.5.0 does not have optimization, hence it is recommended for old CPUs.
We then use SL.ensure to automatically install python libraries required by this script. In this case, we need keras and tensorflow. The tensorflow 1.5.0 does not have optimization so it is recommended for old CPUs.
In snaplogic_init, we create a new session. We download the dataset and build the CNN model in snaplogic_final. The dataset can be obtained directly from Keras. The raw data shape is (N, 28, 28), we need to reshape it to (N, 28, 28, X) in order to use the Conv2D layer. Since the images in this dataset contain one color channel (grayscale), X is 1. We scale the color intensity to range [0,1]. We apply one hot encoding to targets (y_train, y_test).
Our CNN model starts with two Conv2D layers with (3,3) kernel. The first layer's size is 32 and the second one is 64. Then, MaxPooling2D, Dropout, Flatten, Dense, one more Dropout and Dense layers are followed. We train the model 12 epochs with the batch size of 128. The model performs at 99.06% accuracy on 10,000 test samples.
Model Testing
In the pipeline, the File Reader Snap reads the CNN model trained in the previous pipeline from SLFS. The JSON Generator Snap contains 1 handwritten image. The correct label is "1".
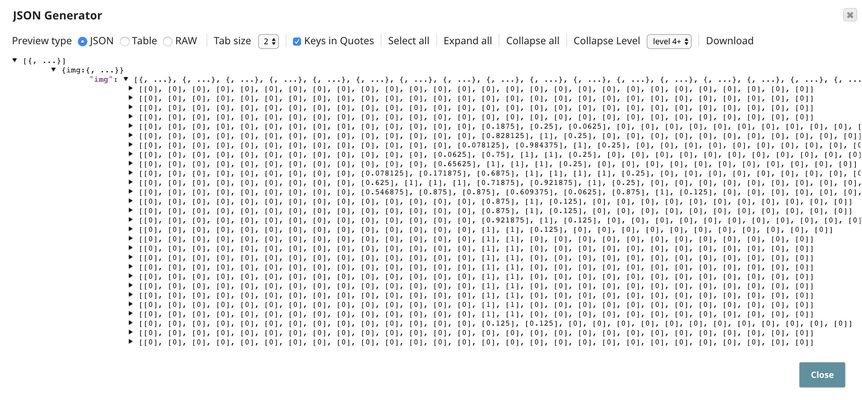
The screenshot below shows the handwritten image in the JSON Generator Snap.
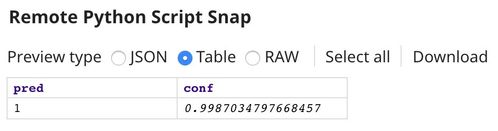
The prediction of the Remote Python Script Snap is shown below. The digit has been correctly identified.
Python Script
The input of the Remote Python Script Snap can be either the neural networks model or a sample. If it is the model, we use base64 to decode the model. If the incoming document is a sample, we will add it to the queue. Once the model is loaded, we apply the model to samples in the queue and output predictions. In order to preserve lineage property in Ultra Task, SLTool.get_drop_doc() is returned for the document describing the model.
Model Hosting
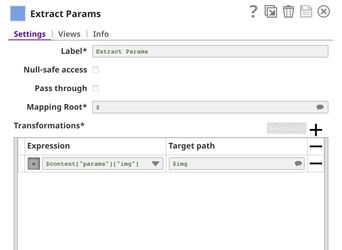
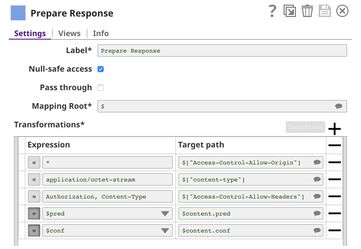
This pipeline is scheduled as an Ultra Task to provide a REST API that is accessible by external applications. The core components of this pipeline are File Reader, JSON Parser, Union, and Remote Python Script Snap Snaps that are the same as in the Model Testing pipeline. Instead of taking the data from the JSON Generator, the Remote Python Script Snap takes the data from API request. The Filter Snap is used to authenticate the request by checking the token that can be changed in pipeline parameters. The Extract Params Snap (Mapper) extracts the required fields from the request. The Prepare Response Snap (Mapper) maps from prediction to $content.pred and confidence level to $content.conf which will be the response body. This Snap also adds headers to allow Cross-Origin Resource Sharing (CORS).
Building API
To deploy this pipeline as a REST API, click the calendar icon in the toolbar. Either Triggered Task or Ultra Task can be used.
Triggered Task is good for batch processing since it starts a new pipeline instance for each request. Ultra Task is good to provide REST API to external applications that require low latency. In this case, the Ultra Task is preferable. Bearer token is not needed here since the Filter Snap will perform authentication inside the pipeline.
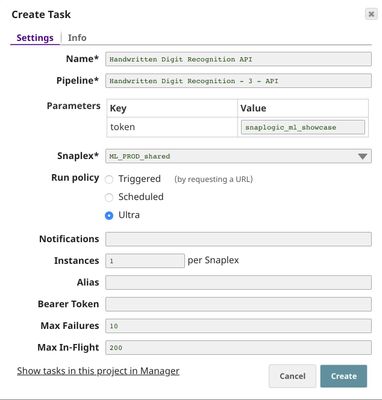
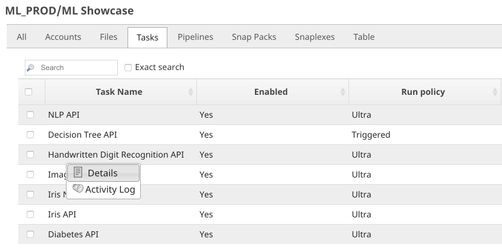
In order to get the URL, click Show tasks in this project in Manager in the Create Task window. Click the small triangle next to the task then Details. The task detail will show up with the URL.
API Testing
In this pipeline, a sample request is generated by the JSON Generator. The request is sent to the Ultra Task by REST Post Snap. The Mapper Snap is used to extract response which is in $response.entity.
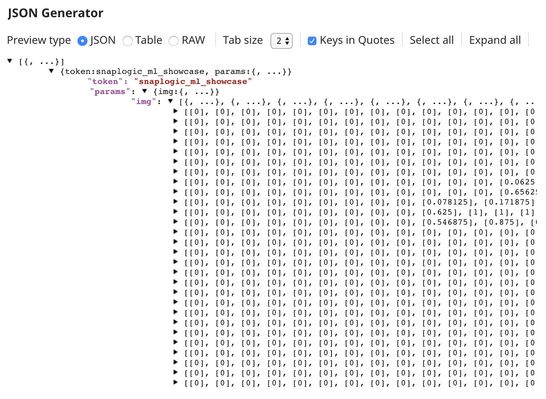
Below is the content of the JSON Generator Snap. It contains $token and $params which will be included in the request body sent by REST Post Snap.
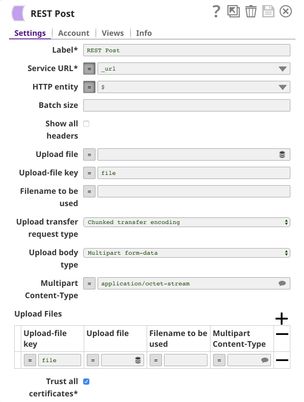
The REST Post Snap gets the URL from the pipeline parameters. Your URL can be found in the Manager page. In some cases, it is required to check Trust all certificates in the REST Post Snap.
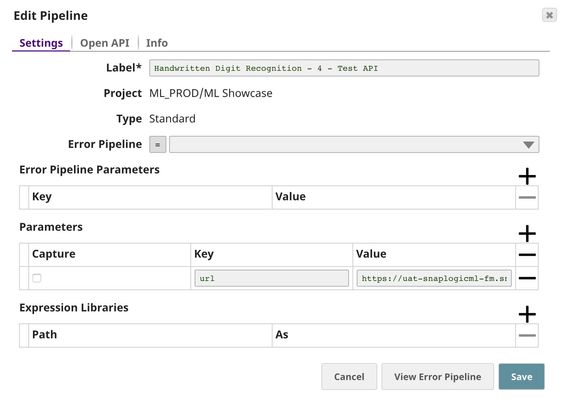
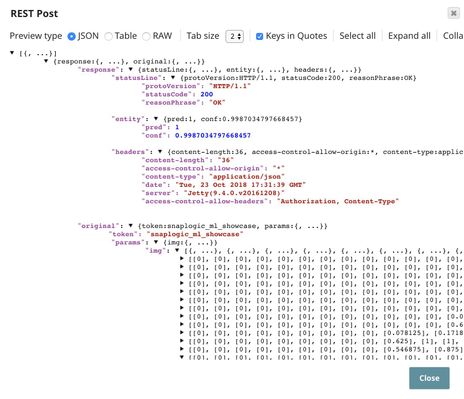
The output of the REST Post Snap is shown below. The last Mapper Snap is used to extract $response.entity from the request. In this case, the prediction is 1 with the confidence level of 0.9987.
Downloads
Important steps to successfully reuse Pipelines
- Download and import the pipeline into the SnapLogic application.
- Configure Snap accounts as applicable.
- Provide pipeline parameters as applicable.
Have feedback? Email documentation@snaplogic.com | Ask a question in the SnapLogic Community
© 2017-2025 SnapLogic, Inc.