May 2019, 4.17 Release Notes
- Ankur Parekh
- Chandna Mitra
- Mohammed Iqbal
On this page:
- Per the SnapLogic Release Process, all Snaplexes across Orgs are upgraded to the 4.17 release at 9 pm PT on June 15, 2019. In case of Hadooplex, you have to manually upgrade the Snaplex.
- This release also includes the patches made to SnapLogic after the 4.16 GA release, as listed in the 4.16 Dot Releases page.
- We recommend that you upgrade to the latest Chrome or Firefox browser version and clear your browser cache before logging into the SnapLogic Intelligent Integration Platform (IIP).
Release Highlights
- Data visualization in Data Preview.
- Three new Snaps in SnapLogic Data Science: Clustering, Match, and Feature Synthesis.
- Snap execution control in all Snap types.
General Platform Enhancements
- Disabled Snap Functionality: Introduces a fundamental shift in the modes in which your Pipelines are executed. You can now disable a Snap, preventing it–and all downstream Snaps–from executing. This change takes a major complexity out of iterative development of Pipelines. If you have Pipelines with multiple branches, you can now test each branch in isolation without having to copy and import the branch into a new canvas.
- Triggered Task Updates: Introduces the following enhancements for running Pipelines as Triggered Tasks:
- You can access custom HTTP headers during execution through Pipeline parameters.
- Performance optimizations resulting in improved latency when triggering Tasks through On-premise and Local Override URLs, reducing latency.
- API Management Enhancements: The API Management layer is enhanced to handle at-scale management of APIs (Triggered tasks) configured to run on a Groundplex, as well as add support for OAuth2 authentication flow for APIs. APIM Proxies now support Tasks that are triggered from Groundplexes.
- Enhanced Support for Data Catalog: Enhances data catalog usability by enabling you to infer the Schema of your data using the JSON Formatter Snap. Previously, only metadata from Parquet-formatted files could be written to the Data Catalog. You can now use the following Snap pattern to populate the Data Catalog: JSON Formatter → File Writer → Catalog Insert.
- SFTP connection update for Snaps: Changed the default value for
maxSftpChannelsfield to 2. - New Expressions: Enhance the SnapLogic Expressions Language by adding the following expressions:
HTML.encode()/decode(): Encode/decode strings into and from HTML entities.zipObject(): Returns an object composed from key/value pairs, which accepts two arrays: the first containing only properties and the second containing only values.toObject(): Performs arrow functions on the values of the array to generate the key/value pair in the object returned by the callback.getMonthFromZeroandgetUTCMonthFromZero: Returns the month in the specified date (with the option of UTC time) as an integer between 0 (January) and 11 (December).capitalize(),camelCase(),kebabCase(),snakeCase(),lowerFirst(),upperFirst(): Alters characters in your strings.
UI
General
- The session timeout behavior has changed. Until 4.16, if you belonged to multiple Orgs, the shortest idle timeout set in any of the Orgs was applied. With the 4.17 release, the session timeout of the current Org is applied instead.
- Insights data is now automatically aggregated on a daily basis. As such, the Insights Schedule setting has been removed from SnapLogic Manager.
Designer
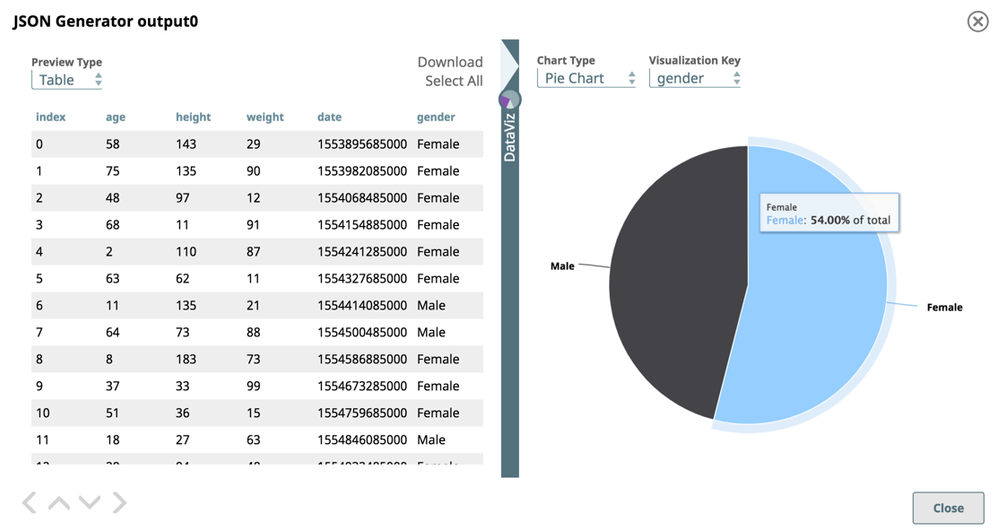
Data Preview Enhancement: Adds the ability to display your data in pie, bar, line, and scatter charts. You can see the entire dataset while navigating through your data records in the paginated tabular view. Apart from offering better controls for navigating through your previewed data Snap by Snap, the enhanced Data Preview form provides multiple options for plotting the various categories of data. You can also select the number of records (up to 2000) that you want to preview through a drop-down menu available on some Snaps.
The Data Preview charts only appear if you are on the latest Snaplex version.
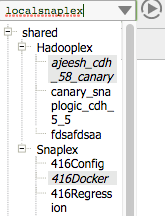
- Snaplex Deprecated Version Indicators: Alerts you about using an older Snap Catalog if any Snaplex node is running an older version of SnapLogic. Starting with the May 2019 release, a warning appears if any of your Snaplexes are deprecated. Additionally, in the Snaplex drop-down menu, the deprecated Snaplexes appear in italics, shaded in gray.
Manager
- Files: Enhances SnapLogic Manager to support the download of certain file types, such as HTML, JPEG, and PNG files. Additionally, you can now upload multiple files at a time to Manager.
- Notification Enhancements: When you log in as an Org Admin, you can configure notifications in Manager for CPU and Memory usage based on thresholds that you set in Manager.
Dashboard
- Snaplex Deprecated Version Indicators: When you hover over a Snaplex that contains old versions of JCC nodes, a warning message appears indicating the deprecated version of the JCC node. When you click the Snaplex, the Details pop-up for that Snaplex displays a note recommending the latest SnapLogic version.
Snap Enhancements
- Pipelines that start before a Snap update continue to run with the older version of the Snap. All Pipelines executed after a Snap update run with the new Snaps.
- For Ultra Pipelines, the currently running instances continue to run with the older Snap Packs. Editing and saving the task instance in Manager causes a rolling restart of the Ultra Pipeline instances, and the new Snap Packs get picked up.
- Customers using SQL Server with Windows authentication and SAP need to restart their Groundplex and Cloudplex instances.
- New Snap Packs appear in the SnapLogic Designer only after all the JCCs in an org upgrade to the latest version.
Updated Snap Packs
- Enhanced the Binary Snap Pack to support SMB versions 2.0 and 3.0.
- Added two properties, Number of retries and Retry interval. Use these to manage retry attempts to the following Snaps in case of network failures:
Confluent Kafka Snap Pack and Hadoop Snap Pack
- The Snap Packs are tested and certified against CDH 6.1.
Database Snap Packs
- Fixed an issue with the Database Execute-type Snaps wherein the Snaps would send the input document to the output view even if the Pass through field is not selected in the Snap configuration. With this fix, the Snaps send the input document to the output view, under the key original, only if you select the Pass through field. The impacted Snaps are:
- Added a new authentication method, User ID and Password with SSL, for Hive SSL Accounts which allows SSL connections for valid user name and password credentials.
- Certified and tested the Snap Pack against CDH 6.1.
- Profile: Added an optional second output view. When enabled, this outputs a graphical representation of the Snap's first output as a HTML file.
- AutoML: Enhanced the AutoML Snap. You can now:
- Select algorithms to derive the top models.
- Input the best model generated by another AutoML Snap from a previous execution.
- View an interactive HTML report that contains statistics of up to 10 models.
- Clustering: New Snap that performs exploratory data analysis to find hidden patterns or groupings in data.
- Feature Synthesis: New Snap that automatically creates features out of multiple datasets that share a one-to-one or one-to-many relationship with each other. Features are measurements of data points. For example, height, mean, mode, min, max, etc.
- Match: New Snap that identifies matched records across datasets that do not have a common key field.
- NetSuite is enforcing two-factor authentication (2FA) for credentials-based accounts and advises that all web-based integrations transition to token-based authentication. To support this transition, NetSuite Credentials account will be deprecated, and we recommend that you either create or switch to NetSuite Token account immediately, so that all SnapLogic Pipelines continue to work without any disruption.
- Added support for OAuth 1.0 accounts, which enable you to connect to applications that require OAuth 1.0.
- ServiceNow Insert and ServiceNow Query: Added Batch Size field that enables you to configure the number of documents that you want to process per batch. You can configure the Batch Size for Ultra Tasks as well.
- JSON Formatter: Added the Derive schema from sample size menu option, whereby you select the sampling size of the schema from the data source.
- Mapper: Added the capability to select either document (previously supported) or binary data (new) for your input and output views.
Snap Execution Enhancement Impacts all Snaps
This release renames the Execute During Preview field as Snap Execution for those Snaps where the field exists and introduces a drop-down menu called Snap Execution for all other Snaps. This field allows you to enable (full or limited) or disable Snap execution.
Backwards Compatibility
Disabled Snaps are not supported in Snap Packs prior to the 4.17 release. If you decide to roll back a Snap Pack to an earlier version, change any Snap Execution Type from Disabled to Execute Only or Execute & Validate before you initiate the rolled-back.
Known Issues
Platform/UI
- If you click a Pipeline link, SnapLogic Designer opens the Pipeline only if you are in the Org that corresponds to the Pipeline. Otherwise, an Org change is implemented, and an empty workspace appears. The workaround is to paste the link in the browser URL bar to open the Pipeline.
- You might experience performance issues running ground triggered Pipelines that have Pipeline Execute Snaps when the child Pipeline runs on a different node.
- The JSON View and Table View are incorrect for new line character (
\n) in the Snap output preview. - When the output document contains too many columns, the dropdown list in DataViz view of the Data Preview fails to show all of the columns when you should be able to scroll through all of them.
- If you create a Pipeline with a File Reader Snap left open while creating a second Pipeline with the File Writer Snap open, you receive the following error message when saving the second Pipeline:
Try again or refresh the page. If error continues to occur, please contact customer support. sl.ibm.saveAll() Threw an unexpected error: "TypeError: Converting circular structure to JSON".
Clicking OK results in the following error:
Refresh the page to try reloading your workspace. If the error continues to occur, please contact customer support. Uncaught TypeError: Cannot read property 'class_id' of undefined.
Snaps
In the Email Reader Snap, when you specify the full file path in the Attachment Folder field and you select Rename in the File Action field, you receive the following error message:
Failed to retrieve messages.- Soap Execute Snap does not evaluate expressions for the Attachments properties, even when the expressions are enabled.
- ServiceNow Snaps do not work with Ultra Pipelines/Tasks.
- Snowflake Lookup Snap fails to retrieve table column details in Lookup column name when the same table name exists in another database in Snowflake.
- Redshift Insert Snap fails to create a table with a 2nd input view when the input documents contain NCHAR/BPCHAR (fixed length character string) data type column data.
- MS Dynamics 365 for Sales Read Snap fails with a
NullPointerExceptionerror. - Auto-refresh does not work for Box Accounts.
- Parquet Writer Snap is unable to write Parquet files to S3 when executing Pipelines on HDP Hadooplex.
- File Delete Snap fails to validate even when the SFTP file is successfully deleted.
- Google Worksheet Writer Snap is having an issue where the number of valid records in the output should not include the header row.
- JDBC Insert Snap connected with Derby database when create table is enabled, fails with the length, precision, scale attribute for column, or type mapping VARCHAR (variable character field) error.
- File Reader Snap is accepting zip files, which should not the expected behavior.
Azure SQL - Bulk Extract Snap is unable to parse big integer calculations.
- OpenAir Read Snap is missing
ResourceRequestandResourceRequestQueueread types. - Anaplan Read Snap pulls archived and deleted models.
- The Snowflake Bulk Upsert Snap does not support the file format options that the Snowflake Bulk Load Snap supports.
- CSV Formatter Snap fails when no value is entered in the Quote character field. A possible workaround is to ensure a null value or in Manager choose the 4.16 release Snap version –
snapsmrc508.
UAT Delta
This section tracks the changes made during the iterative pushes to the UAT server and the GA release. The expected schedule is:
- UAT #1: Friday, April 19, 2019 (Release updates are published above)
- UAT #2: Friday, April 26, 2019
- UAT #3: Friday, May 3, 2019
- GA: Saturday, May 11, 2019 (9 pm PT)
UAT #2 Updates
UI
- Fixed an issue where the Pie Chart in Data Preview does not display when the document count is over 500 because there are too many sectors.
- Fixed an issue where the Alert Notification Settings dialog for Snaplex Node Usage Event Type does not have a field for the Snaplex name.
- Fixed an issue where the Visualization Key drop-down menu does not display correctly for the Data Preview.
- Fixed an issue where infoboxes are not displaying properly in Match, Clean Missing Values, and Numeric to Categorical Snaps.
- Fixed an issue where Data Preview crashes after selecting remaining Dependent Keys when the values are already specified.
- Fixed an issue with Profile and AutoML where HTML rendering did not display correctly in Firefox browsers.
- Fixed an issue where you have to reload Tasks to see them in SnapLogic Manager.
- Fixed an issue to make the table in Data Preview display correctly.
Platform
- Fixed an issue that causes preview data to be unavailable after 15 minutes.
- Fixed an issue with the Snap version used when triggering Pipeline execution from a Groundplex.
- Fixed an issue that causes the certificate warning to show up when using signed certificates.
- Fixed an issue that causes the SnapLogic Designer canvas to be cleared when switching organizations.
- Fixed an error during Dynamic Validation for the Mapper Snap when a binary input view is selected.
- Fixed a property value with Dynamic Accounts wherein properties in these Snaps did not validate properly, resulting in the error:
java.lang.String cannot be cast to java.math.BigInteger. - Fixed an issue where after creating an alert for node usage, the notification is not actually sent to the recipients.
- Fixed a visualization issue in the new Data Previewer that does not work if the previewer is opened before the Pipeline validation is complete.
- Fixed an issue with The Profile and AutoML report that do not work in Firefox because of a security policy.
Big Data
- Cluster events for eXtreme such as
cluster_initiatedandcluster_terminatedare not displaying on the Dashboard
Snaps
- Fixed an issue with the ForEach Snap where no preview output displays when the Validate and Execute option is selected as the Execution Mode.
- Fixed an issue with the Directory Browser and File Poller Snaps that fails getting a list of files when using an SMB server account.
- Fixed an issue with the HDFS ZipFile Read Snap that writes the encoded name to the output view despite the Prevent URL Encoding property enabled.
- Fixed an issue with the File Poller Snap that fails to access the sldb:/// Directory, displaying a "
URLDecoder: Illegal hex characters in escape (%) pattern" error. - Fixed an issue with the MongoDB Find Snap that fails with Query Expression with the error "
Failed to parse MongoDB query expression." - Fixed an issue where the Microsoft Dynamics CRM Account fails to validate after the first time as the ADFS Mex URL property does not work as expected.
UAT #3 Updates
UI
Fixed an issue where Table and JSON Views display the new line character (
\n) incorrectly in the Data Preview.Fixed an issue where File Preview did not display binary files or a file name given in an incorrect file path.
- Fixed an issue where ML Showcase, some tutorials, and the reporting feature of Profile and AutoML Snaps when loading the scripts for Bootstrap, JQuery, and Highcharts display unreliably.
Platform
Fixed an issue where Snaplex alerts generate regardless of the Snaplex for which the alert is configured.
Fixed an issue where runtime information and execution details are missing from the Dashboard for some Triggered Tasks.
Fixed an issue where If a child Pipeline has an unconnected output view, the Pipeline Execute Snap in the parent Pipeline has to have an output view, or else the main Pipeline fails with an Invalid Output View Configuration error.
Big Data
- Fixed an issue where Extreme Snowflake Pipelines fail due to the Snowflake Account not decrypting.
- Fixed an issue where Extreme Pipelines fail when using private Snap Packs.
- Fixed an issue when downloading Pipeline Execution statistics on Hadooplex gives a 500 error.
Snaps
- Fixed an issue with the Match Snaps and Feature Synthesis Snaps where the suggested schema works for only one of the input views.
- Fixed an issue with the ServiceNow Query Snap that retrieves only 250 records at a time.
- Fixed an issue with the Preview doc count value when it is hardcoded to 50 for some Snaps and cannot be set to any other value.
- Fixed an issue with the REST OAuth2 accounts experiencing an intermittent issue where a Pipeline fails displaying an "
Invalid JWT token. The token is expired." error even when the token is valid. - Fixed an issue with the Catalog Writer Snap (Spark SQL 2.x) where the expressions are not evaluated correctly.
- Fixed an issue with the Parquet Reader, ORC Reader, HDFS Reader, HDFS ZipFile Reader, and Hadoop Directory Browser Snaps that do not accept a full path in the File and Directory fields.
- Fixed an issue with the Match Snap where incorrect input values in Left field and Right field outputs all the records from the upstream Snap.
- Fixed an issue with the Directory Browser, File Poller, and Multi File Reader Snaps where their performance slows down when using using SMBv1 Account, taking over 2 hours to process.
- Fixed an issue with the Pipeline Execute Snap that fails when not having an output open view after receiving a document from a child Pipeline.
- Fixed an issue with the Match Snap that fails when the number of documents in the first input view is more than the ones in the second input view.
- Fixed an issue with the File Poller Snap not polling indefinitely when Polling timeout value is -1.
- Fixed an issue with the File Delete Snap for S3 fails with "
The file server returned success on the delete request, but the file still exists" error when the Validate deletion option is selected. - Fixed an issue with the REST Snaps where auto refresh does not work for OAuth2 accounts.
GA Updates
Platform
- Fixed an issue that caused authentication errors in some scenarios when running ground triggered Pipelines that have Pipeline Execute Snaps.
- Fixed an issue where the
pipe.flags.is_suggestflag is not initialized for ground trigger Pipelines. - Fixed an issue where the property label for Execute During Preview was set incorrectly for eXtreme mode and Spark mode Snaps.
- Fixed an issue that caused
File not founderrors during SLFS file operations.
4.17 Dot Releases
Snap Packs
| Snap Pack | Update Date | Build | Updates |
|---|---|---|---|
| MongoDB | 7/29/2019 | db/mongo7665 | Fixed an issue with the MongoDB Find Snap wherein the Snap fails to query using UUIDs. |
| Flow | 7/22/2019 | flow7637 | Fixed an issue with the Data Validator Snap wherein the output fails to report all but one of the violations when there are multiple constraints of the Required type. |
| SQL Server | 7/18/2019 | MULTIPLE7479 | Fixed an issue with the SQL Server - Lookup Snap wherein it fails a UUID search. |
| PostgreSQL | 7/16/2019 | db/postgres7588 | Fixed an issue with tables sharing an overlapping column name wherein Pipeline execution fails due to the table collision. |
| Binary | 7/16/2019 | binary7589 | Fixed an issue with the File Reader Snap wherein SMB fails to provide multiple Snaps with concurrent access. |
| Salesforce | 7/15/2019 | salesforce7474 | Added Order by clause and Limit clause properties to the Salesforce Reader Snap to fix an issue wherein the Snap throws an error while fetching records. |
| Confluent Kafka | 07/12/2019 | confluentkafka7537 | Updated the following Snaps:
|
| Binary | 07/02/2019 | binary7487 | Fixed an issue with the File Writer Snap wherein the Overwrite File action for SMB files fails on subsequent executions. |
| Oracle | 06/26/2019 | db/oracle7459 | Fixed an issue with the Oracle Stored Procedure Snap wherein the Pipeline execution fails with an error when the input data type is CLOB. |
| Transform | 06/26/2019 | transform7431 | Added a new field, Ignore empty stream, to the Avro Formatter Snap that writes an empty array in the output in case of no input documents. |
| Redshift | 6/20/2019 | db/redshift7433 | Fixed an issue with the Redshift Bulk Load Snap wherein the Snap fails to copy the entire data from source to the Redshift table without any statements being aborted. |
| MongoDB | 6/18/2019 | db/mongo7427 | Fixed a Null Pointer Exception for old MongoDB accounts that did not have driver jars. |
| Anaplan | 6/18/2019 | Anaplan7422 | Fixed an issue with the Anaplan Read Snap wherein the Snap pulls archived and deleted models. |
| Transform | 6/17/2019 | Transform7417 | Added a new field, Format as canonical XML, to the XSLT Snap that enables canonical XML formatting. |
| All Snap Packs | 6/11/2019 | ALL7402 | Pushed automatic rebuild of the latest version of each Snap Pack to SnapLogic UAT and Elastic servers. |
| SQL Server | 6/10/2019 | db/sqlserver7394 | Fixed an issue wherein bit data types in the SQL Server - Select table convert to true or false instead of 0 or 1. |
| MySQL | 6/10/2019 | db/mysql7395 | Fixed an issue wherein bit data types in the MySQL - Select table convert to true or false instead of 0 or 1. |
| Snowflake | 6/10/2019 | db/snowflake7396 | Fixed an issue wherein bit data types in the Snowflake - Select table convert to true or false instead of 0 or 1. |
| Binary | 6/7/2019 | binary7381 | Fixed an issue with SMB accounts wherein login to the server fails if password contains a plus (+) sign. |
| Salesforce | 6/7/2019 | salesforce7352 | Fixed an issue with the Read and SOQL Snaps wherein Pipeline validation fails because of a dynamic account opening multiple file descriptors. |
| SumoLogic | 6/5/2019 | sumologic7369 | Fixed an issue with the Execute Search Job Snap wherein it fails to return the results correctly. |
| Binary | 6/4/2019 | binary7366 | Added support for multiple slashes as a prefix for SMB file URLs. |
| MySQL | 6/3/2019 | db/mysql7357 | Fixed an issue with the MySQL Execute snap wherein the Retry property for connection fails after the database connection is severed. |
| Snowflake | 5/31/2019 | db/snowflake7334 | Added AWS Server-Side Encryption support for AWS S3 and AWS KMS (Key Management Service) for Snowflake Bulk Load, Snowflake Bulk Upsert, and Snowflake Unload Snaps. |
| MongoDB | 5/24/2019 | db/mongo7331 | Fixed an issue with the MongoDB - Update Snap wherein the Snap converts all non-updated integer and float data types to string data type. |
| Google Spreadsheet | 5/15/2019 | google/spreadsheet7283 | Fixed an issue with the Worksheet Writer Snap wherein the No of valid records written field in the output document would count the header row. |
| Binary | 5/15/2019 | binary7280 | Added a new field, File delete action, to the File Delete Snap that handles missing target files. |
Platform
| Update Date | Build | Updates |
|---|---|---|
| 7/2/2019 |
| Enhanced SSO Login functionality to support additional authentication methods RequestedAuthnContext and RequestedAuthnContext Comparison at the Org-level. As an Org admin, you can configure these additional options for user logins across your Org. |
| 6/28/2019 | master-5508 - Patch 4 |
|
| 6/13/2019 | master-5472 - Patch 3 |
|
| 6/4/2019 | master-5396 - Patch 2 | Fixed a performance issue in Tasks triggered on a Groundplex, where the Pipeline uses the Pipeline Execute Snap to invoke a child Pipeline that references expression libraries. |
| 5/22/2019 | master-5365 - Patch 1 |
|
| 5/20/2019 | N/A |
|
UI
| Update Date | Build | Updates |
|---|---|---|
| 6/13/2019 | N/A |
|
| 5/20/2019 | N/A |
|
Have feedback? Email documentation@snaplogic.com | Ask a question in the SnapLogic Community
© 2017-2025 SnapLogic, Inc.