August 2021, 4.26 Release Notes
- Ankur Parekh
- Anand Vedam
- John Brinckwirth
In this article
Key New Features in SnapLogic
Platform:
- Zero Downtime during quarterly release updates.
- Snaplex-based Scheduler will be the default scheduling mechanism for all Scheduled Tasks after the auto-upgrade on September 18.
- Ability to encrypt SnapLogic user emails.
API Management:
- Ability to manage lifecycle of APIs.
- Redesigned API Catalog and API documentation for the Developer Portal.
- Support for creating APIs from existing SnapLogic Assets.
New Snaps:
- Shopify Snap Pack.
- Tableau Snaps—Hyper Formatter, Hyper Parser, and Hyper Write.
- Zuora Snaps—Zuora OpenAPI and Zuora REST Read.
ELT for Cloud Data Platforms:
- Support for Databricks Lakehouse Platform as a target database.
- Ability to run multiple SQL queries using ELT Execute Snap.
New! Introducing SnapLogic Flows
4.26 UAT Delta
Important
Per the SnapLogic Release Process, all remaining Snaplex instances across Orgs are auto-upgraded to the main-10245 - Patch 1 version at 9 p.m. PT on September 18, 2021. Orgs migrated to the 4.26 GA version prior to the auto-upgrade are not impacted.
The Snaplex upgrade process also upgrades the Java version to the latest version. After the upgrade, the Java version of your Cloudplex nodes may not be the same as your FeedMaster nodes. However, this does not impact the operations of your SnapLogic instance. We will be fixing this issue in a subsequent release.
- To use the new SnapLogic features and Snaps in the 4.26 release, ensure that your Snaplex nodes are upgraded to the main-10245 - Patch 1 (Recommended) version.
- This 4.26 release includes the patches deployed to SnapLogic after the 4.25 release, as listed in the 4.25 Dot Releases section.
4.26 Dot Releases
Platform
UI
Standard
Data Automation
Platform
Snaplex-based Scheduler
During the 4.26 release cycle's auto-upgrade date of September 18, the Snaplex-based Scheduler will be enabled by default through the Control Plane. The new scheduling mechanism improves the timeliness and reliability of Scheduled Task executions. You do not need to update your Snaplex instances to enable the new scheduler, unless you have set the feature flag to false for your Org, in which case you will have to switch it to true in order for the Snaplex-based Scheduler to be enabled for your Org. Contact support@snaplogic.com for more information.
Zero downtime of the SnapLogic Platform during the release window: Starting with this release, we are implementing zero downtime for the SnapLogic Platform during quarterly release updates. Thus, you will be able to access the SnapLogic UI and all your Pipelines will run as schedule during the release window. For details, see the SnapLogic release process article.
Email Encryption: Adds the ability to upload a public key in Manager to be used for emails. You can now encrypt your emails using this public key. Email Encryption is a subscription feature.
New APIM Features
Lifecycle Management for APIs: Added the capability to manage the lifecycle of your SnapLogic APIs. You can now publish APIs created from API specifications to the new developer portal in the Portal Manager console. You can also unpublish, deprecate, and retire an API version, providing full API lifecycle management features.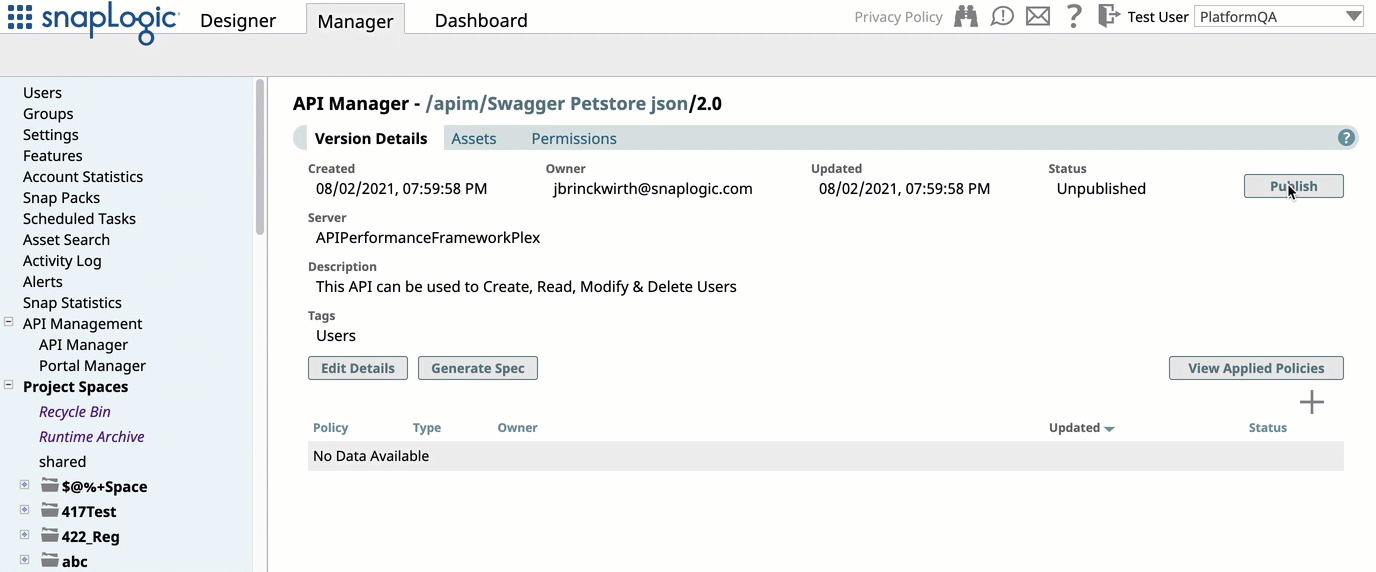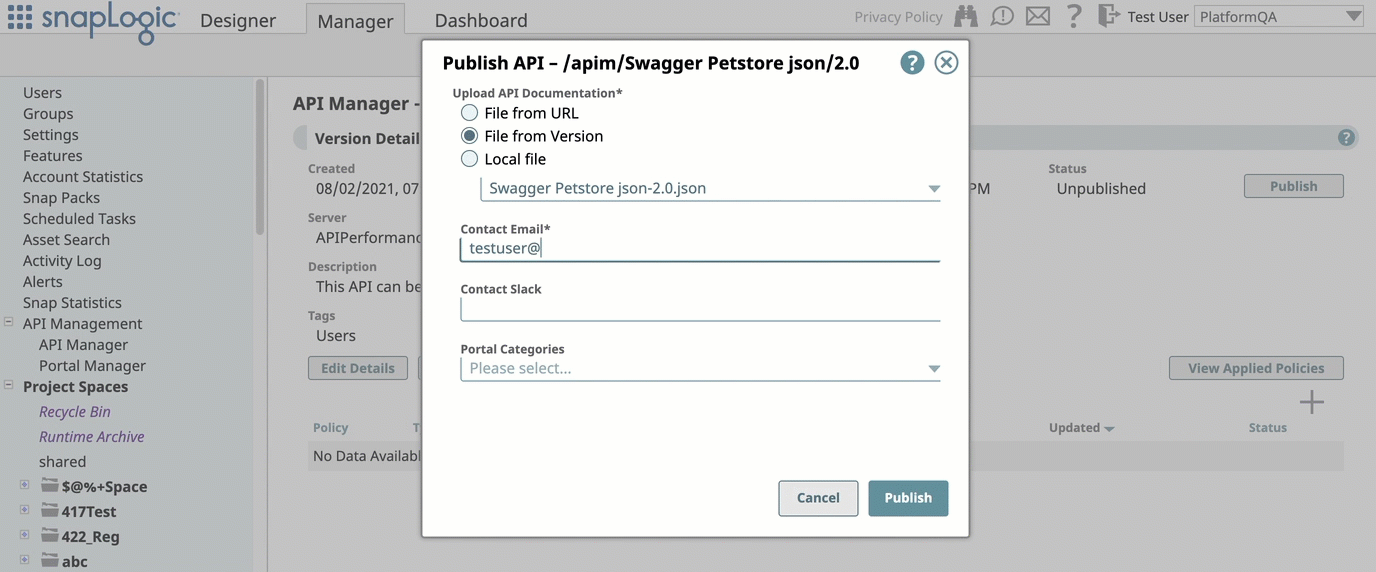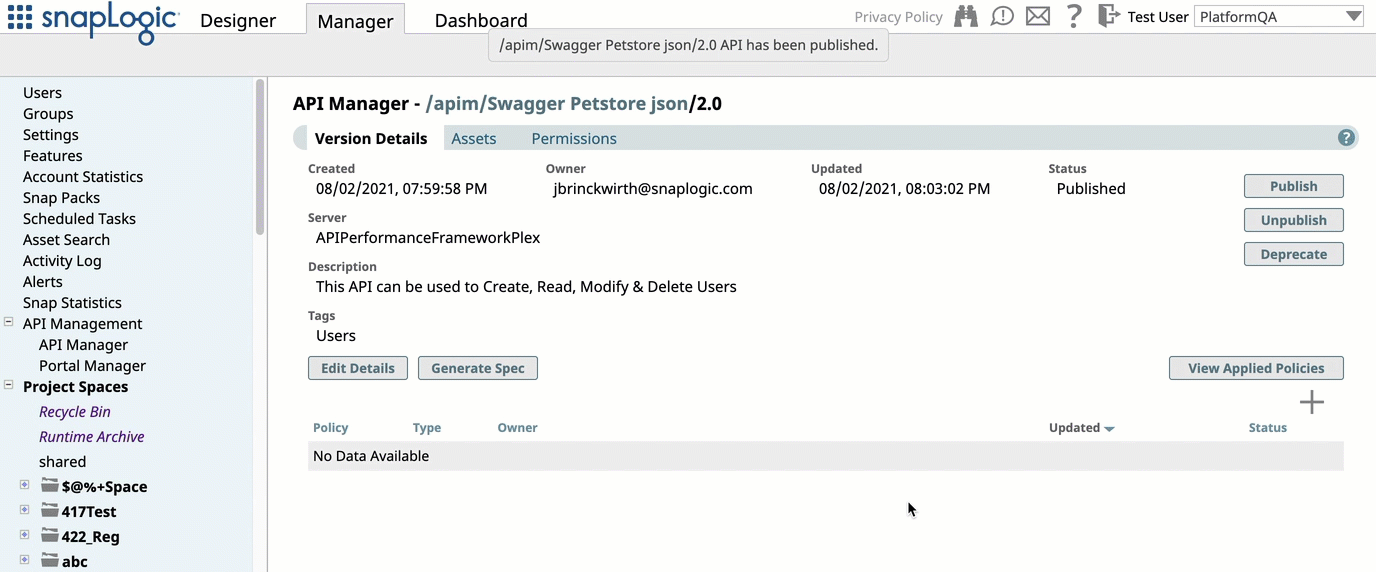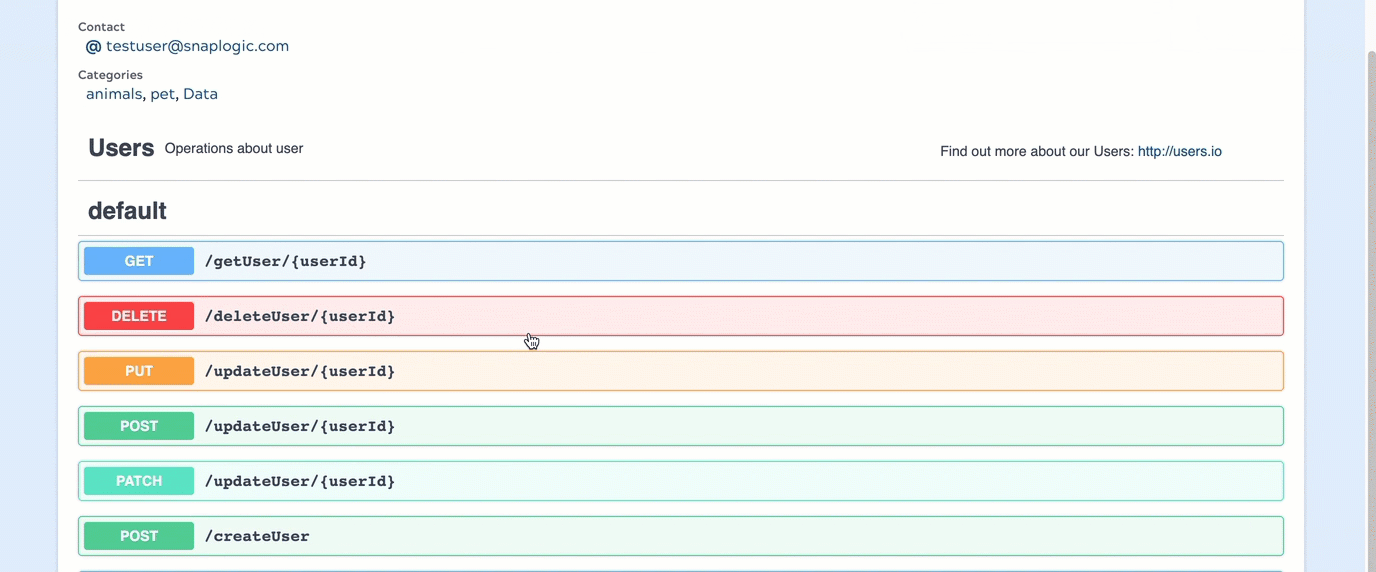
Portal Manager: Added console for managing the developer portal for your Org. You can now customize the new Developer Portal with your own branding and URL suffix. The Portal Manager also enables you to view API status on the API Catalog.
API Developer Portal: Introduced a new page where API consumers can explore and view APIs created in your Org. The API Catalog provides a space where APIs can be exposed to users outside of the SnapLogic ecosystem. You control the consumer's ability to view and call APIs by adding API policies in the API Version Details page.
Create APIs from Assets in Manager: Added options in the API Manager console to create APIs directly from Projects and the Assets. You can now build your APIs by developing Pipelines and Tasks, and add other assets like Accounts and Files to the Project to be uploaded as an API in the API Manager. You can also create an Empty API asset as a placeholder.
OAuth 2.0 Credentials API Policy: Added a new OAuth2 flow to authenticate users using client credentials in the API Policy.
Enhancements to Existing Features
Batching Support: Added batching support to the Pipeline Execute Snap. In contrast to the Reuse mode, the batching field enables users to specify the number of documents to be processed to completion through the child Pipelines before processing the next document in the batch. Accordingly, batch mode does not support reuse mode.
Windows 2019 Support: Added Windows 2019 support for your Groundplex instances.
SnapLogic will sunset support for Windows Server 2012 on . Hence, ensure that you upgrade your Groundplex instances to Windows 2016 or 2019.
Snaplex Tab Dashboard Improvements: Snaplex tab widgets now display one-minute data intervals for time ranges up to seven days.
OAuth Accounts: Optimized the OAuth account refresh operations by moving them to the customer Groundplex instances. Additionally, the Box OAuth 2.0 account type was also added to Snaps that do not restart Ultra Task instances because Box has the capability of reloading the new account token.
Known Issues
- Few Snaplex instances with an unusually high number of tasks may take slightly longer to start scheduling tasks when a node is starting.
- For Scheduled Tasks scheduled every 5–10 minutes, the next execution time is not being updated even though the Task is executed.
- In the Version Details page of an API, clicking Edit Details from the API > Versions page displays the Server field for selecting another Snaplex, but the field is disabled if the specified Snaplex is in a down state.
Behavior Change
- Users are no longer unsubscribed from a Snap Pack if the Snap Pack's name is changed.
Your Groundplex thread/heap dump files are now stored in a folder as configured in the
java.io.tmpdirproperty, which is usually /tmp on Linux.
Standard-mode Snaps
Behavior Fix in the CSV Formatter Snap
In 4.26, we fixed the Ignore empty stream checkbox functionality in the Snap to actually produce an empty binary stream output in case there is no input document when the checkbox is NOT enabled. Previously, there was no output even when the checkbox was NOT enabled.
If your existing Pipelines (prior to 4.26) use the Ignore empty stream functionality, then you might need to revisit your Pipeline design and either enable or disable the said checkbox depending upon the expected behavior.
New Snaps
Binary Copy: This Snap that belongs to the Flow Snap Pack enables you to copy a binary stream to the Snap’s output views. Use this Snap if you want to send the same information to multiple endpoints.
Copybook Snap Pack: This Snap Pack enables you to work with Cobol Copybooks. This Snap Pack has the following Snaps:
- Cobol Copybook Data Generation: Generates sample records based on Cobol Copybooks.
- Cobol Copybook Parser: Parses Cobol Copybook and data.
Shopify: This Snap Pack allows businesses to set up an online store and sell their products online. You can use this Snap Pack to create orders, products, customers, and run automated workflows. The Shopify Snap Pack has the following Snaps:
- Calculate Order Refund: Generate refund transactions for an order.
- Create Customer: Add a new customer account in the store.
- Create Fulfillment: Create, modify, or delete an order's fulfillment.
- Create Order: Create an order of a purchase that includes details of the customer, cart, and transactions.
- Create Order Refund: Create a refund for an existing order in the Shopify store.
- Create Order Risk: Create an order risk (fraud analysis and recommendations) associated with an existing order.
- Create Product: Add a new product in the store.
- Create Product Variant: Add a new product variant for an existing product.
- Create Transaction: Create a transaction for an order.
- Delete Customer: Remove an existing customer record from the store.
- Delete Order: Remove an existing order record from the store.
- Delete Order Risk: Remove a risk associated with an order.
- Delete Product: Remove a product record from the store.
- Delete Product Variant: Remove a product variant record associated with a product.
- Get Customers: Fetch a list of customers or a specific customer using the customer resource ID.
- Get Order Refund: Fetch a list of refunds for an order or a specific refund of an order using the resource ID.
- Get Order Risk: Fetch a list of all order risks of an order or a specific risk of an order using the resource ID.
- Get Orders: Fetch a list of orders/draft orders or a specific order/draft order using the resource ID.
- Get Product Variants: Fetch a list of product variants or a specific product variant using the resource ID.
- Get Products: Fetch a list of products or a specific product using the resource ID.
- Get Transactions: Fetch a list of transactions or a specific order transaction using the transaction resource ID.
- Order Operations: Close, cancel, or reopen an existing order.
- Send Invoice: Email an invoice of the draft order.
- Update Customer: Update information relating to an existing customer.
- Update Orders: Update information relating to existing orders.
- Update Order Risk: Update any risks associated with an order.
- Update Product: Update the information relating to the product.
- Update Product Variant: Update product variants of a specific product.
- The Snap Pack consisting of the Tableau 8 version Snaps (Tableau 8 Write and TDE 8 Formatter) is deprecated due to no customer usage. See the Deprecated Snaps section for more information.
- Starting from the 4.26 release, the existing Tableau 9 & 10 Snap Pack is renamed to Tableau Snap Pack.
Added the following Tableau Snaps to support hyper extract files for Tableau 10.25 and later versions. Hyper is Tableau's in-memory data engine that is optimized for fast data ingestion and analytical query processing on large or complex data sets.
- /wiki/spaces/AP/pages/2231337693: Converts the incoming documents to Tableau hyper extract format and sends the output (extract) to the binary output view.
- /wiki/spaces/AP/pages/2231599682: Parses Tableau hyper extract files and converts them to a document format.
- /wiki/spaces/AP/pages/2275278950: Creates a hyper file in a temporary location (local disk) for incoming documents and publishes it to Tableau Server/Online without packaging it into a data source.
Zuora: Added the following Snaps and account types to connect these Snaps with the Zuora REST API.
- Zuora REST Read Snap: Retrieves all the fields from a Zuora object.
- Zuora Open API Snap: Calls the Zuora REST API endpoint associated with your application.
- Zuora Dynamic OAuth2 Account: Enables OAuth2 authentication using Pipeline Parameters.
- Zuora OAuth2 Account: Enables OAuth2 authentication.
Updated Snap Packs
- Enhanced the Amazon SQS Account with a new checkbox Enable Large Message Support that enables Amazon SQS client to send and receive messages up to 2GB through Amazon S3.
- Enhanced the AWS S3 and Amazon SQS accounts to add the Snap’s information to the User Agent header for Cross IAM account requests.
Anaplan: Added the following fields to the Anaplan Write Snap:
- Override server settings
- Separator
- Text Delimiter
Azure Active Directory: Enhanced the Create Entry and Update Entry Snaps to support Pipeline parameters and upstream values for the Attribute name setting under Attributes and the Snap Pack to support proxy authentication.
- Enhanced the Directory Browser Snap to process files with the owner field for the SFTP protocol. Upon validation, the output of the Snap fetches the owner’s name, which was previously displayed as unknown.
- Fixed an issue with the File Writer Snap where the Snap fails to connect to the SFTP endpoint using the AWS Transfer Family.
- Fixed an issue where Pipelines fail to connect the SFTP Server with the Binary Snap Pack after upgrading to the SnapLogic 4.25 release version (main9554).
- Removed the Project ID field from the Google Service Account, since the JSON Key already contains information about the Project ID.
Box:
- Modified default values of the following fields across the Snap Pack to trigger automatic retries by default, in case of connection failures or timeouts:
- Number of Retries - Changed from 0 to 3
- Retry Interval (seconds) - Changed from 1 to 5
Google Sheets: Enhanced the Worksheet Writer Snap to populate the target schema preview with headers and associated data types (when the data is written to an existing worksheet with a valid header) in the upstream Snap.
JDBC:
- Fixed an issue with Generic JDBC - Select Snap where if there are URL properties in the account, the unPooledConnection does not use the properties when creating a connection. This causes the auto-detect functionality to use the wrong database name.
- Fixed an issue with MySQL and MariaDB in Generic JDBC - Update Snap when a table is incorrectly reported as not being found.
- Enhanced the Kafka Producer Snap to support the Avro serialization format with the new target data type Avro under Key and Value Serializer.
Enhanced the Kafka SSL Account with new fields (Registry Username or Key and Registry Password or Secret) for Schema Registry authentication. The two existing SASL properties (SASL Username and SASL Password) are revised to SASL Username or Key and SASL Password or Secret, respectively.
- Enhanced the Kafka Producer and Kafka Consumer Snaps to create a default client ID string that identifies the specific Snap instance.
Improved the handling of interrupted/aborted Kafka Snaps to ensure a proper clean-up of metrics.
Optimized the Kafka Producer Snap to initialize the Kafka API only if there is at least one input document.
Fixed an issue of account passwords being included in the log messages output of Kafka Snaps. The account passwords are now hidden in the logs for both Kafka Consumer and Kafka Producer Snaps.
Apache Kafka client library is upgraded from version 2.6.0 to 2.8.0.
Confluent Kafka client libraries are upgraded from version 5.2.1 to 6.2.0.
- Enhanced the MySQL - Lookup Snap suggestions to load the Output Fields and Lookup Column settings.
- Fixed an issue with the MySQL - Select Snap where the second output view of the Snap was showing empty column values and improved error messages in the Snap where the Snap fails with a null pointer exception error when the given account information is invalid.
OpenAPI: Enhanced the OpenAPI Snap with the following two fields:
- HTTP Headers
- Query Parameters
PostgreSQL: Enhanced the performance of PostgreSQL - Bulk Load Snap significantly. We expect the Snap to execute up to three times faster than the previous version for enterprise workloads.
REST:
- Added Send Client Data as Basic Auth Header checkbox to the Create Account settings of the OAuth2 and OAuth2 SSL accounts to include and pass the client credentials information in the header when connecting to the OAuth endpoint.
- Added a new account type REST AWS SigV4 that adds the ability to call any AWS API.
Salesforce: Enhanced the Salesforce Read Snap to enable you to add an optional second output view to display the schema of a target object as the output document.
ServiceNow: Enhanced the ServiceNow Query, ServiceNow Insert, ServiceNow Update, and ServiceNow Delete Snaps with a retry mechanism that includes the following fields:
- Number Of Retries
- Retry Interval (seconds)
- Enhanced the Snowflake S3 Database and Snowflake S3 Dynamic accounts with S3 AWS Token field that allows you to connect to private and protected Amazon S3 buckets.
- Added a new account type Snowflake Google Storage Database to connect to Google Cloud Storage to load data.
Added support for all existing Snowflake Snap accounts to connect to a Snowflake instance hosted on the Google Cloud Platform
- Enhanced Snowflake - Lookup and Snowflake SCD2 Snaps with the Input Date Format field to select from the following two options:
- Continue to execute the snap with the given input Date format
- Auto Convert the format to Snowflake default format
SOAP: Enhanced the SOAP Execute Snap with a new checkbox Escape special characters to escape XML special characters in variable values when inserting values into the Velocity template.
SQL Server: Fixed an issue with the SQL Server - Bulk Load Snap where the Snap fails when the login password contains a colon or a less than (<) symbol.
- Enhanced the CSV Parser Snap with a new checkbox Preserve Surrounding Spaces that enable the Snap to preserve the surrounding spaces for the values that are non-quoted.
- Enhanced the JSON Splitter Snap with a new field Show Null Values for Include Paths that enables the Snap to show key-value entries of the null values for the objects added to the Include Paths field in the output document.
- Enhanced the Join Snap with a new field Available Memory Threshold (%) to enable the Snap to keep all the Right input view documents with the same join-path values in memory until the join operation is done for the specific join-path values.
- Replaced Strict XSD output field in the XML Formatter Snap with Map input to first repeating element in XSD. If selected, the Snap ignores the root element from the XSD file.
Improved the error messages in Teradata Snap Pack, Oracle Snap Pack, MySQL - Select in MySQL Snap Pack, Channel Operations Snap in Slack Snap Pack, Create Event Snap in Exchange Online and Teams - Create Team in the Teams Snap Pack where the Snaps fail with a null pointer exception error when the given account information is invalid.
Enhanced the JIRA, Coupa, SOAP Snap Packs and Workday Prism Analytics Bulk Load Snap in Workday Prism Analytics Snap Pack to support HTTP proxy authentication.
Updated the AWS SDK from version 1.11.688 to 1.11.1010 in the DynamoDB Snap Pack Redshift Snap Pack, and added a custom SnapLogic User Agent header value.
Renamed Snap Packs
Revised the names of the following Snap Packs. This does not affect your subscription to these Snap Packs.
| Old Snap Pack Name | New Snap Pack Name |
|---|---|
| Confluent Kafka | Kafka |
| Google Spreadsheet | Google Sheets |
| Tableau 9&10 | Tableau The Snap Pack consisting of the Tableau 8 version Snaps is deprecated starting from the 4.26 GA. See the Deprecated Snaps section for more information. |
Deprecated Snaps
The Snap Pack consisting of the Tableau 8 version Snaps (Tableau 8 Write and TDE 8 Formatter) is deprecated due to no customer usage. Contact support@snaplogic.com, if your existing Pipelines use Snaps from the deprecated Snap Pack.
Known Issues
None.
Prior 4.25 Snap Dot Releases that are Merged into 4.26 GA
Data Automation
SnapLogic's data automation solution speeds up the identification and integration of new data sources, and the migration of data from legacy systems. The solution can automatically detect duplicate, erroneous, or missing data, and identify structures and formats that do not match the data model. Data automation can accelerate the loading and transformation of your data into the data warehouse, speeding up the data-to-decisions process.
New Features in ELT Snap Pack
Starting with the 4.26 release, you can use the Snaps in the ELT Snap Pack to perform ELT operations on Databricks Lakehouse Platform (DLP). This is in addition to the existing list of supported target databases—Snowflake, Redshift, and Azure Synapse.
Supported JDBC JAR Versions
ELT Snaps automatically use a corresponding JDBC JAR file to connect to your target database and to perform the load and transform operations.
| Database | Certified JDBC JAR File |
|---|---|
| Azure Synapse | mssql-jdbc-9.2.1.jre8.jar |
| Databricks Lakehouse Platform (DLP) | SimbaSparkJDBC42-2.6.17.1021.jar |
| Redshift | redshift-jdbc42-2.0.0.2.jar |
| Snowflake | snowflake-jdbc-3.13.1.jar |
Using Alternate JDBC JAR File Versions
Though we recommend you to use the above JAR file versions, you can choose to use a different version, based on your environment.
Updated ELT Snaps
Enhanced the ELT Snap preview to support the following Snowflake data types: array, object, variant, and timestamp.
The Snaps convert the values to hexadecimal (HEX) equivalents—the default setting for the session parameter BINARY_OUTPUT_FORMAT in Snowflake. See Session Parameters for Binary Values for more information.
If this setting is different from hexadecimal (such as base64) in the Snowflake table, the Snaps still convert the values to hexadecimal equivalents for rendering them in the Snap preview.
- Enhanced all ELT Snaps to display the Get preview data checkbox below the Snap's Label field.
The ELT Database account is now mandatory for all Snaps in the ELT Snap Pack.
Breaking change
Starting with the 4.26 release, all Snaps in the ELT Snap Pack (except the ELT Copy Snap) require an account to connect to the respective target database. Your existing Pipelines that do not use an account may fail. We recommend you to associate an ELT Database Account to each of the ELT Snaps (except ELT Copy Snap) for your Pipelines.
- Enhanced the ELT Aggregate Snap to support Linear Regression functions on Redshift and Azure Synapse. The Snap also supports these functions on Databricks Lakehouse Platform.
- Enhanced the ELT Execute Snap to enable running multiple DML, DDL, and DCL SQL statements from the same Snap instance.
- Enhanced the ELT Join Snap to:
- Support LEFT ANTI JOIN and LEFT SEMI JOIN types on all supported databases.
- Display or hide the Resultant Column Names Prefix Type field based on the target database selected in the Snap's account.
- Enhanced the ELT Load and ELT SCD2 Snaps to provide a list of suggested data types, while adding columns to or creating a table.
Known Issues
- Selecting the Pipeline Parameters from the drop-down list enabled for using expressions or the expression editor to define fields within your ELT Database Account does not currently respond as it should. Hence, we recommend that you manually key-in the parameter names with the preceding underscore ( _ ). For example,
_dbfsPwd,_sfUsername. - ELT Transform Snap displays incorrect data types (string instead of the actual data type) for column names populated in its Input schema section.
ELT Pipelines created prior to 4.24 GA release using one or more of the ELT Insert Select, ELT Merge Into, ELT Load, and ELT Execute Snaps may fail to show expected preview data due to a common change made across the Snap Pack for the current release (4.26 GA). In such a scenario, replace the Snap in your Pipeline with the same Snap from the Asset Palette and configure the Snap's Settings again.
In case of Databricks Lakehouse Platform, all ELT Snaps' preview data (during validation) contains a value with precision higher than that of the actual floating point value (float data type) stored in the Delta. For example, 24.123404659344 instead of 24.1234. However, the Snap reflects the exact values during Pipeline executions.
- In any of the supported target databases, this Snap does not appropriately identify nor render column references beginning with an _ (underscore) inside SQL queries/statements that use the following constructs and contexts (the Snap works as expected in all other scenarios):
WHEREclause (ELT Filter Snap)WHENclauseONcondition (ELT Join, ELT Merge Into Snaps)HAVINGclauseQUALIFYclause- Insert expressions (column names and values in ELT Insert Select, ELT Load, and ELT Merge Into Snaps)
- Update expressions list (column names and values in ELT Merge Into Snap)
- Secondary
ANDcondition Inside SQL query editor (ELT Select and ELT Execute Snaps)
Workaround
As a workaround while using these SQL query constructs, you can:
Precede this Snap with an ELT Transform Snap to re-map the '_' column references to suitable column names (that do not begin with an _ ) and reference the new column names in the next Snap, as needed.
- In case of Databricks Lakehouse Platform where CSV files do not have a header (column names), a simple query like
SELECT * FROM CSV.`/mnt/csv1.csv`returns default names such as _c0, _c1, _c2 for the columns which this Snap cannot interpret. To avoid this scenario, you can:- Write the data in the CSV file to a DLP table beforehand, as in:
CREATE TABLE csvdatatable (a1 int, b1 int,…) USING CSV `/mnt/csv1.csv`where a1, b1, and so on are the new column names. - Then, read the data from this new table (with column names a1, b1, and so on) using a simple SELECT statement.
- Write the data in the CSV file to a DLP table beforehand, as in:
- Fixed with 426Patches11262 on : When loading data from a JSON file into a target Databricks Lakehouse Platform (DLP) instance using an ELT Load Snap, if you choose the Drop and Create Table option as the Load Action and specify an additional column (that is not available in the JSON file) for the new table, it results in one more column null added to the new target table. In case of CSV files, this Snap behaves the same way as mentioned above, but only when the CSV file uses a comma separator.
- Fixed with 426Patches11262 on : For a Snowflake target instance, the ELT Insert Select Snap does not suggest column names to select for the Insert Column field in the Insert Expression List.
- Due to an issue with the COPY_INTO mechanism provided by Azure Synapse, the ELT Load Snap does not display an error message (the Pipeline appears to run successfully) even when the source file path does not resolve to a valid file. We recommend that you verify whether the source file location you provide in the Snap’s settings is valid and accessible, before running your Pipeline.
- ELT Pipelines targeting a Databricks Lakehouse Platform (DLP) instance might fail due to a very long or complex SQL query that they build.
- As a workaround, you can set an advanced (URL) property useNativeQuery to 1 in your ELT Database Account configuration as shown below:
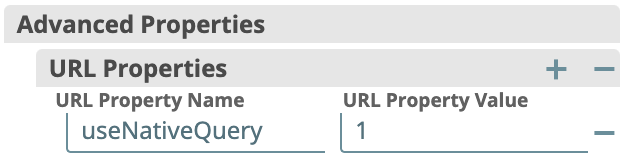
- As a workaround, you can set an advanced (URL) property useNativeQuery to 1 in your ELT Database Account configuration as shown below:
- Fixed with 426Patches11262 on : The Snaps—ELT Merge Into, ELT Select, ELT Join, and ELT Filter—do not prevent the risk of SQL injection when your target database is Databricks Lakehouse Platform (DLP).
After the fix with 426Patches11262 on , the ELT Load Snap on Databricks Lakehouse Platform (DLP) may cause intermittent null-pointer exceptions only when you specify an incorrect source file path in any of the DBFS Folder Path and the File List > File fields.
- Fixed with 426Patches11262 on : In case you are writing into a Snowflake target table, the ELT Insert Select Snap attempts to create the target table even when it exists in the database.
- Fixed with 426Patches11262 on : When you use the SQL editor in the ELT Select Snap configuration to define your SQL query, the Pipeline validation fails due to a syntax error in the following scenarios. However, the Pipeline execution works as expected. The only workaround is to drop the LIMIT clause and the optional OFFSET clause from the SQL query during Pipeline validation.
The query contains a LIMIT clause on a Snowflake, Redshift or Databricks Lakehouse Platform target instance: The SQL query created during Pipeline validation includes an additional LIMIT clause, for example:
SELECT * FROM "STORE_DATA"."ORDERS" LIMIT 10 LIMIT 990.- The query contains an OFFSET clause (supported in case of Snowflake and Redshift): The SQL query created during Pipeline validation looks like
SELECT * FROM "STORE_DATA"."ORDERS" LIMIT 10 OFFSET 4 LIMIT 990.
Prior 4.25 ELT Dot Releases that are Merged into 4.26 GA
Introducing SnapLogic Flows
SnapLogic Flows is a breakthrough new user interface that empowers business users to self-build new application integrations and data automations to support the specific needs of their respective functions and departments. Flows removes coding barriers and makes it easy for business users to succeed in developing and integrating applications such as Salesforce, Marketo, Google Sheets, Slack, to get the data and insights they need to make faster business decisions.
Flows also enables IT to step away from the core development of these solutions but gives them the ability to add requirements and guardrails for non-technical developers, enabling IT to centrally maintain visibility, control access, and oversee what is developed before it is pushed to production.
To get started, register for Flows.
Have feedback? Email documentation@snaplogic.com | Ask a question in the SnapLogic Community
© 2017-2025 SnapLogic, Inc.