February 2021, 4.24 Release Notes
In this article
Key New Features in SnapLogic
Platform:
Universal Search includes new Pipeline search
Snaplex-based Scheduler
Notifications via Slack
API Management:
API Dashboard UX improvements
eXtreme:
Cross account IAM support
ELT for Cloud Data Platforms:
Support for Azure Synapse
Ease-of-use improvements
New Snap Packs:
HubSpot, MS Power BI, Marketo, OpenAPI, MS Teams
Updated Snap Packs:
- Enhancements to the Confluent Kafka Snap Pack
- Redshift and Amazon SQS support for cross domain IAM roles
Important
- Per the SnapLogic Release Process, all remaining Snaplex instances across Orgs are auto-upgraded to the recommended version at 9 p.m. PT on March 20, 2021. Orgs migrated to the 4.24 GA version prior to the auto-upgrade are not impacted.
- To use the new SnapLogic features and Snaps in the 4.24 release, ensure that your Snaplex nodes are upgraded to the recommended version.
- This 4.24 release includes the patches deployed to SnapLogic after the 4.23 release, as listed in the 4.24 Dot Releases section.
4.24 UAT Delta
This section tracks the changes made during the iterative pushes to the UAT server and the GA release. The following is the release schedule:
UAT: Friday, February 05, 2021 – Use Snaplex Version: 4.24_rc2-9059 - 4.24 GA
GA: Saturday, February 13, 2021 (9 p.m. PT) - main-9488 - Patch 3
The SnapLogic GA release build on the production server is also deployed on the UAT server.
UAT Fixes
Snaps
- Fixes an issue in the JDBC Snaps to output the data time values in the same format as the 4.23 release (November, 2020) to support backward compatibility in the output view.
4.24 Dot Releases
Platform
| Date of Update | Snaplex Build | Updates |
|---|---|---|
| main-9488 - Patch 3 (Recommended) |
| |
| N/A | Control Plane update:
| |
| main-9292 - Patch 2 |
| |
| main-9191 - Patch 1 |
|
We currently recommend you to use main-9488 - Patch 3 as your Snaplex version.
UI
| Date of Update | Update |
|---|---|
Known issues:
| |
Fixes an issue with Orgs using enhanced encryption that run into an error decrypting sensitive information with non-ASCII characters when connecting with end-point accounts. |
Standard-mode Snaps
SOAP Snap Pack uses the 4.23 GA version (main7430)
Due to an upgrade to the CXF library, SOAP Execute Snap that uses the CXF client targeting SOAP 1.2 endpoints can fail. We also observe increased thread counts related to this upgrade. Hence, during the 4.24 auto-upgrade on , we did not update the SOAP Snap Pack and are moving the stable version for all your Orgs to main7430 (4.23 GA) instead of main8556 (4.24 GA). This should not impact your existing Pipelines.
You can also use SOAP Snap Pack version 423patches7441 that was deployed as 4.23 dot release on , if needed.
| Snap Pack | Date of Update | Snap Pack Build Name | Updates |
|---|---|---|---|
| Binary | 424patches9044 | Enhanced the S3 File Writer to use an MD5 checksum that automatically checks for data integrity and corruption while uploading the file. | |
| Box | 424patches9242 |
| |
| Hadoop | 424patches9262 | Enhanced the AWS S3 Account for Hadoop to provide role-based access when you select the IAM role check box. | |
| Anaplan | 424patches9313 | Fixes an issue related to Index out of range in the Anaplan Upload Snap when the separator is not present or does not match the one in the upload file. | |
| Binary | 424patches9020 | Fixes the file operation error of copying large S3 files in the File Operation Snap by supporting the transfer of zero-byte S3 files while uploading the file. | |
| Snowflake | 424patches8905 | Enhances the Snowflake - Bulk Load Snap to allow transforming data using a new field Select Query before loading data into the Snowflake database. This option enables you to query the staged data files by either reordering the columns or loading a subset of table data from a staged file. This Snap supports CSV and JSON file formats for this data transformation. | |
| DynamoDB | 424patches9031 |
| |
| SOAP | 424patches9077 |
| |
| JMS | 424patches9098 | Enhances the JMS account in the JMS Snap Pack by updating the JNDI properties (java.naming.security.principal, java.naming.security.credentials) with username and password, to support the requirements of certain JMS servers. | |
| JMS | 424patches9104 | Fixes an issue in the JMS Consumer Snap, where different JMS SQS accounts interfere with each other when running on the same JCC node by using the AWSStaticCredentialProvider instead of the SystemPropertiesCredentialsProvider. | |
| Salesforce | 424patches9024 |
| |
| Microsoft Power BI | main80 | Enhances the following Snaps in the Microsoft Power BI Snap Pack by adding two values, Dataflow and Dataflow Storage Accounts to the Entity Type field. | |
| Twilio | main80 | Introduces the Twilio Snap Pack that enables you to perform various communication functions programmatically, such as making phone calls and sending text messages using Twilio's Web Service APIs. This Snap Pack offers the following Snaps:
| |
| SQL Server | 424patches8657 | Enhances the SQL Server - Select Snap by introducing a new field, Query Hints, which helps to customize and optimize the database engine to process query statements. | |
| Exchange Online |
| 424patches8965 | Fixes an issue in the Snap Pack by handling the conflict of users having same email IDs by accepting only the first user’s email ID returned by the API and ignoring the duplicate ones. |
| /wiki/spaces/SD/pages/1438719 | 424patches8617 | Fixes an error handling issue in the PostTweet Snap, where data and error are now routed to the error view. | |
| Transform | 424patches8938 |
| |
| NetSuite | 424patches8891 | Introduces the new Snap NetSuite Call RESTlet that enables you to call RESTlet scripts through token-based authentication. This Snap provides the functionality of the NetSuite RESTlet framework that supports the HTTP methods (GET, DELETE, POST, PUT) and MIME types. | |
| RabbitMQ | 424patches8750 | Fixes the handling of RabbitMQ Headers in the RabbitMQ Consumer Snap, including the x-death header. | |
| JDBC | 424patches8903 | Fixes the Pipeline execution failure issue when using the JDBC Snaps with a Microsoft Access account by setting the correct quotation handler for the configured account. | |
| Binary | 424patches8876 |
| |
| Salesforce | 424patches8569 | Fixes an issue in Salesforce Bulk Upsert, Salesforce Bulk Update, and Salesforce Bulk Create Snaps that fail to process Related object and Related external ID values by modifying the input schema that formats the CSV data. Potential Breaking Change (now fixed in 424patches9024) This Salesforce Snap patch contains an issue affecting the Salesforce Subscriber and Salesforce Publisher Snaps. If you do not use these Snaps in your Pipelines, then you can use this patch version. Else, we recommend you to not use this patch version as Pipelines will fail. | |
| Confluent Kafka | 424patches8805 | Fixes an issue with the Kafka Producer Snap by removing the account validation, which is not required, when the Snap initializes in a Pipeline execution. | |
| Teradata | 424patches8799 |
| |
| Google Directory | 424patches8638 | Enhances the Google Directory Read Snap by introducing two field attributes, projection and customFieldMask, to retrieve custom schema fields. |
Data Automation
| Snap Pack | Date of Update | Snap Pack Build Name | Updates |
|---|---|---|---|
| ELT | 424patches8793 |
No changes are needed to your existing Pipelines. | |
| /wiki/spaces/SD/pages/410189849 | 424patches8724 | Fixes an issue with eXtremeplex that is unable to read Parquet files written from a Groundplex (and hence displays base64 enabled in output columns upon validation), by changing the data encoding from Base64-encoded to plain text format. This issue does not occur during Pipeline execution. |
Important
- Per the SnapLogic Release Process, all remaining Snaplex instances across Orgs are auto-upgraded to the recommended Snaplex version main-9105 - 4.24 GA at 9 p.m. PT on March 20, 2021. Orgs migrated to any of the other 4.24 versions prior to the auto-upgrade are not impacted.
- To use the new SnapLogic features and Snaps in the 4.24 release, ensure that your Snaplex nodes are upgraded to the recommended version.
- This 4.24 release includes the patches deployed to SnapLogic after the 4.23 release, as listed in the 4.23 Dot Releases page.
Groundplex Support for Java 11 and Sunsetting Java 8
Groundplex––Per the 4.22 release announcement, we are only supporting Java 11 and have ceased support for Java 8. Your nodes on Java 8 will not work. Hence, ensure that you upgrade to Java 11.0.8+ version for all your Groundplex instances. If your infrastructure is still using Java 8, you will see class file version errors when running your Groundplex.
Platform
New Features
Snaplex-based Scheduler: Introduces a new mechanism for activating your Scheduled Tasks. The Snaplex-based Scheduler improves the timeliness and reliability of Scheduled Task executions. Previously, the scheduler in the SnapLogic Control Plane handled all Scheduled Tasks executions. The Snaplex-based Scheduler shares the scheduling duties with the Control Plane scheduler, making Scheduled Task executions timelier and more reliable.
Enabling the Snaplex-based Scheduler
- We encourage you to enable the Snaplex-based Scheduler for all Scheduled Tasks in your Org. To plan for this adoption, see details about Snaplex-based Scheduler.
- We recommend that you use main-9292 - Patch 2 as your Snaplex version to use the scheduler feature.
- In the 4.25 Release (May 2021), the Snaplex-based Scheduler will be the default mechanism for scheduling all Tasks.
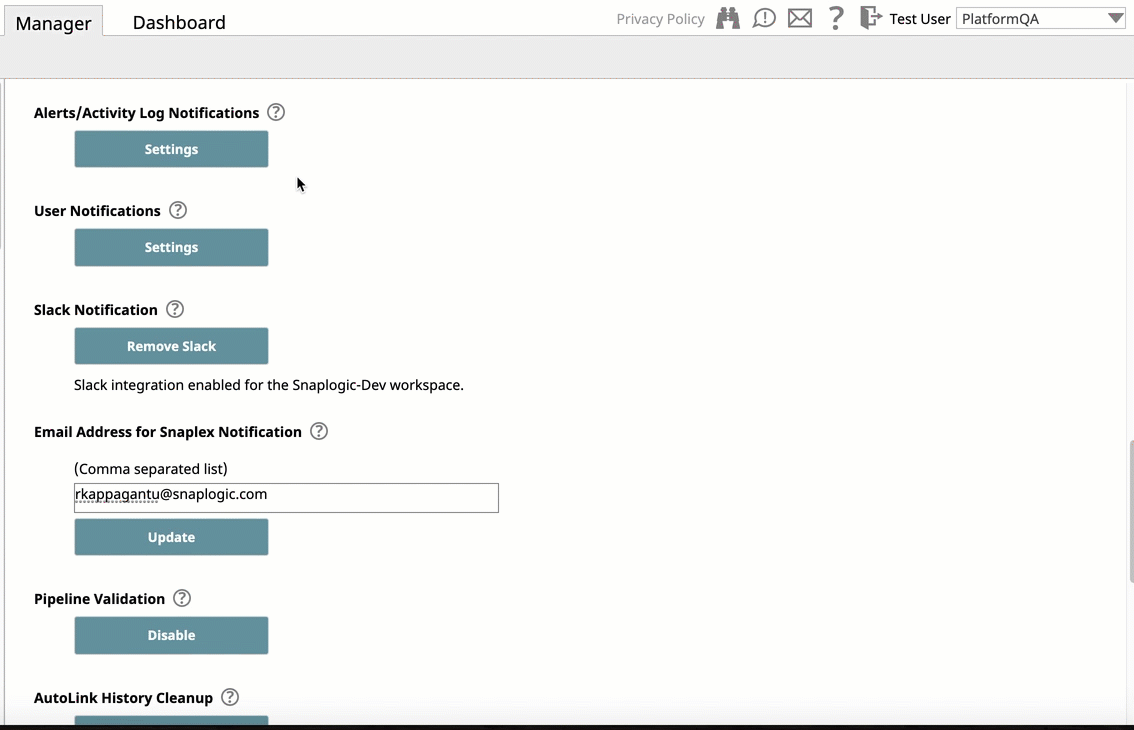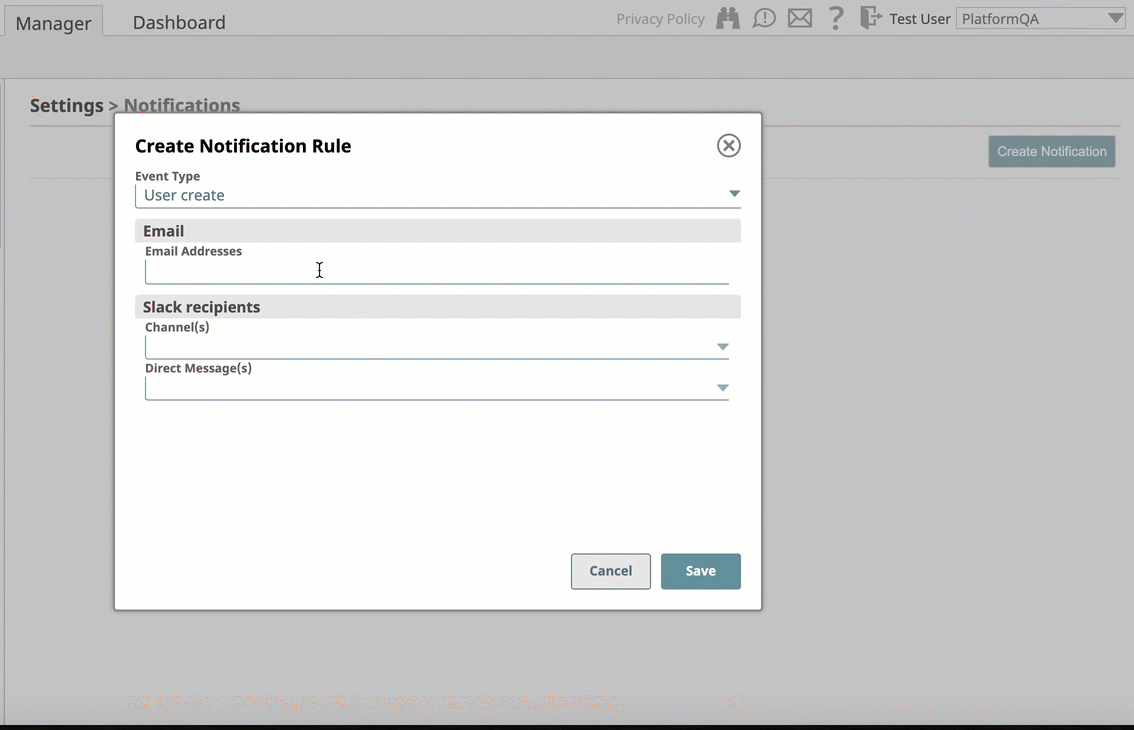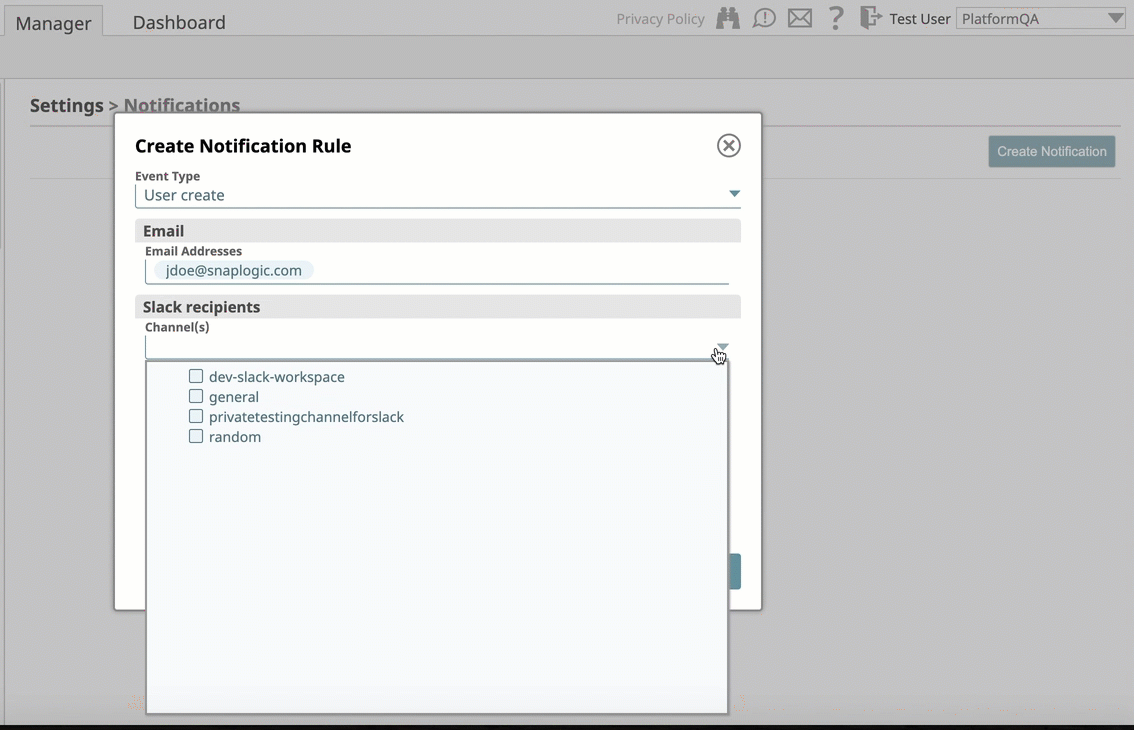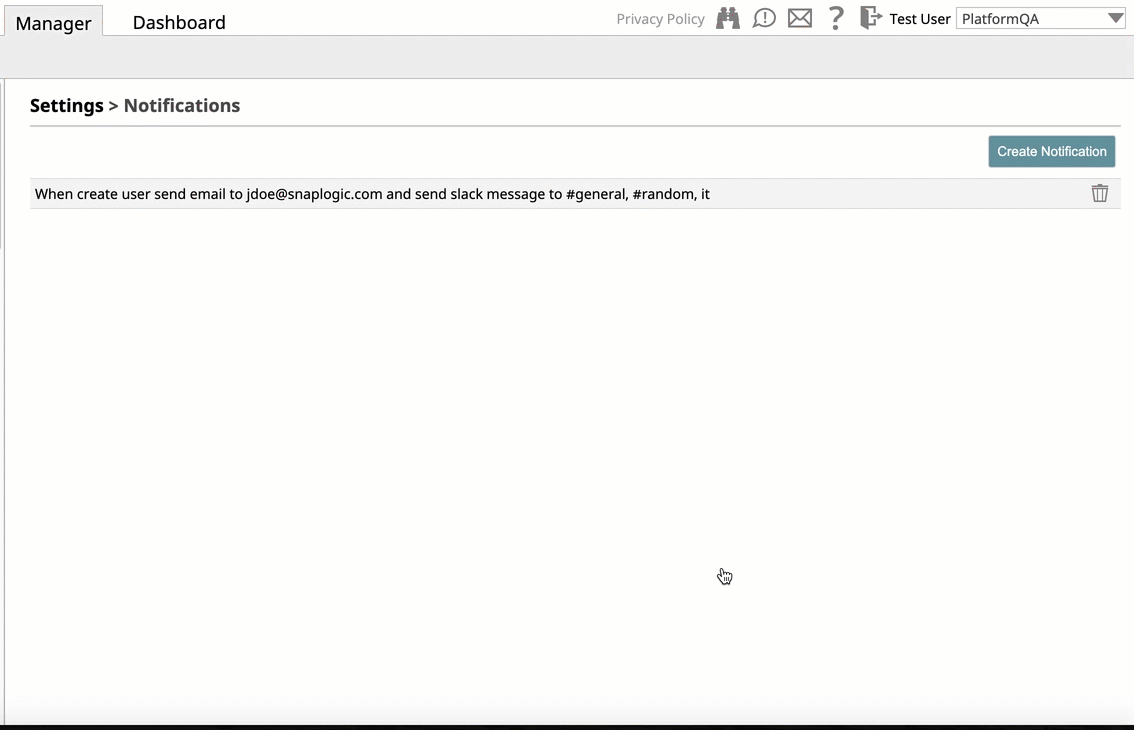
- Activity Notifications Via Slack: Introduces support for the Slack messaging app within the SnapLogic platform communication system, enabling you as an Org admin to add Slack channels and recipients for your SnapLogic communications. Slack notifications support is in the following areas of the SnapLogic UI:
- The alerts and notifications in Manager > Settings.
- The Create Snaplex and Update Snaplex dialogs in Manager > Project Spaces also support adding Slack recipients.
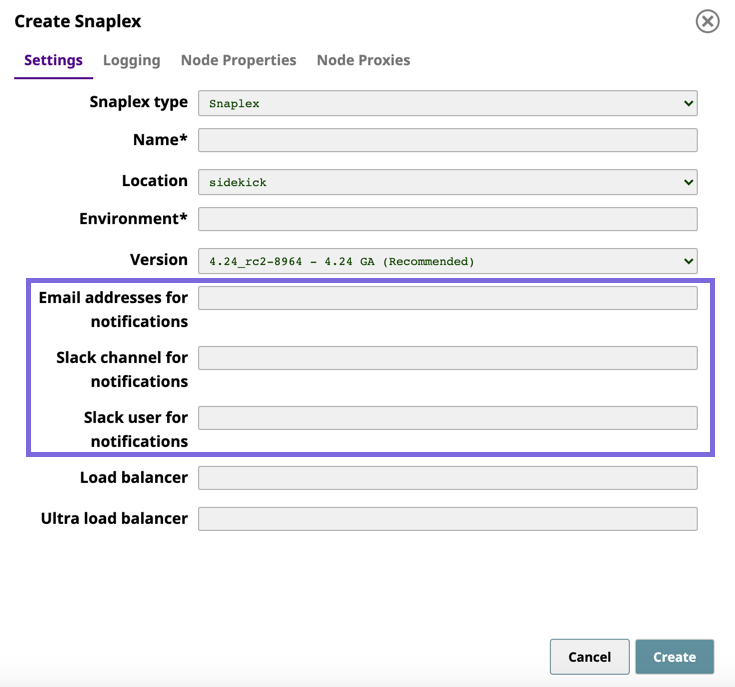
The integration setup follows an easy workflow, which is also in Manager > Settings, and requires that you grant permission to access the Slack channels and recipients in your workspace.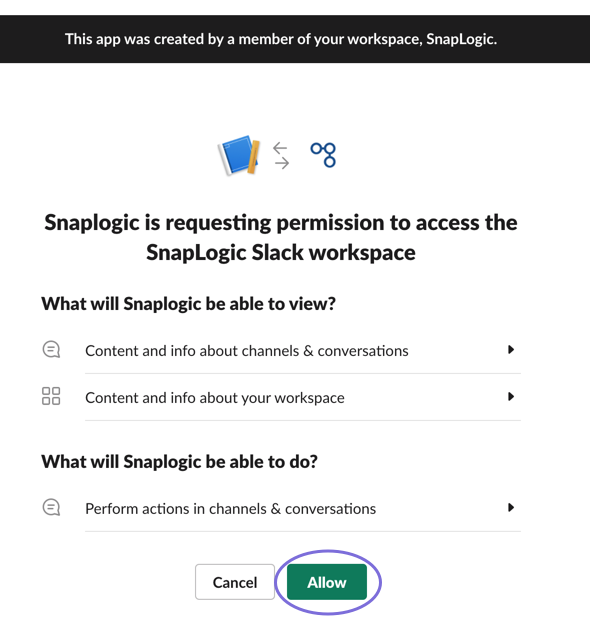
After adding Slack, you can send notifications and alerts to Slack recipients through Slack channels or directly to Slack users, making it easier to communicate with team members who are either users or nonusers of the SnapLogic platform.
- The alerts and notifications in Manager > Settings.
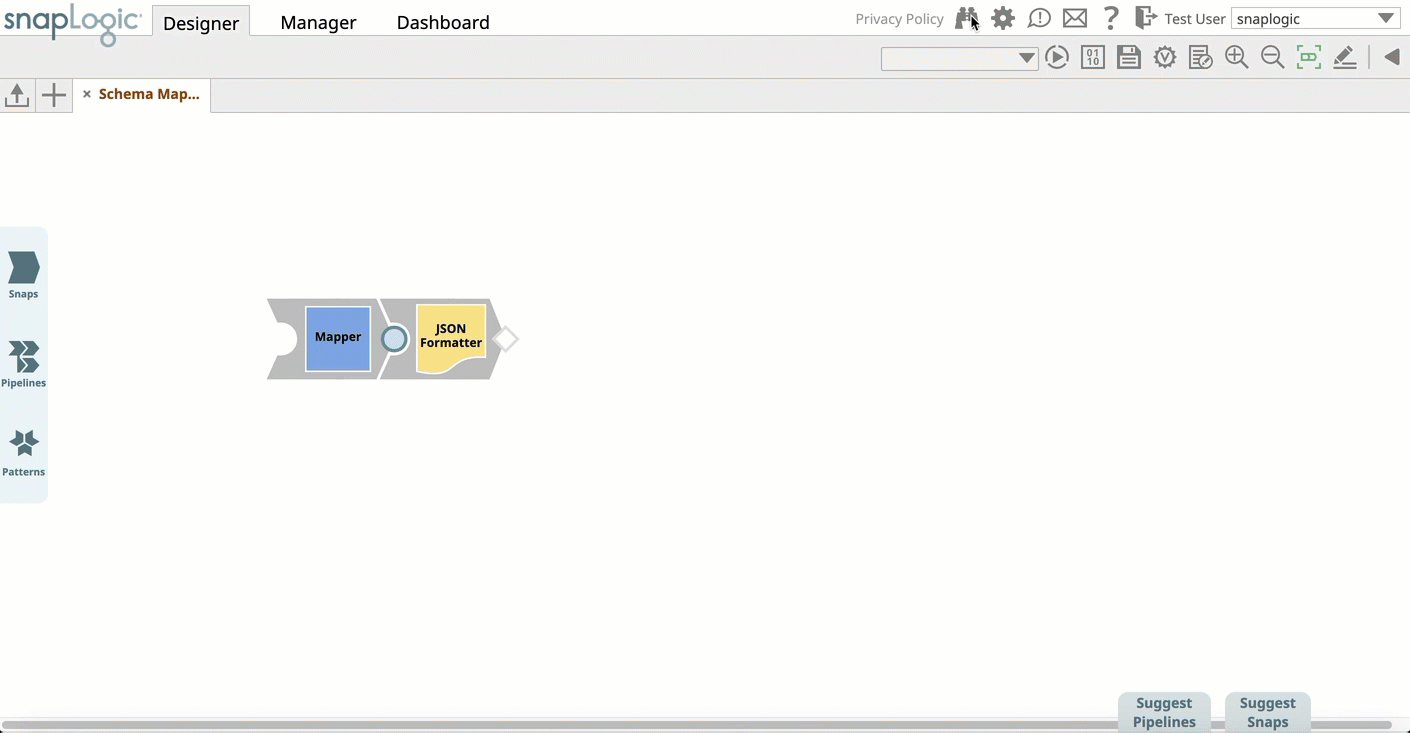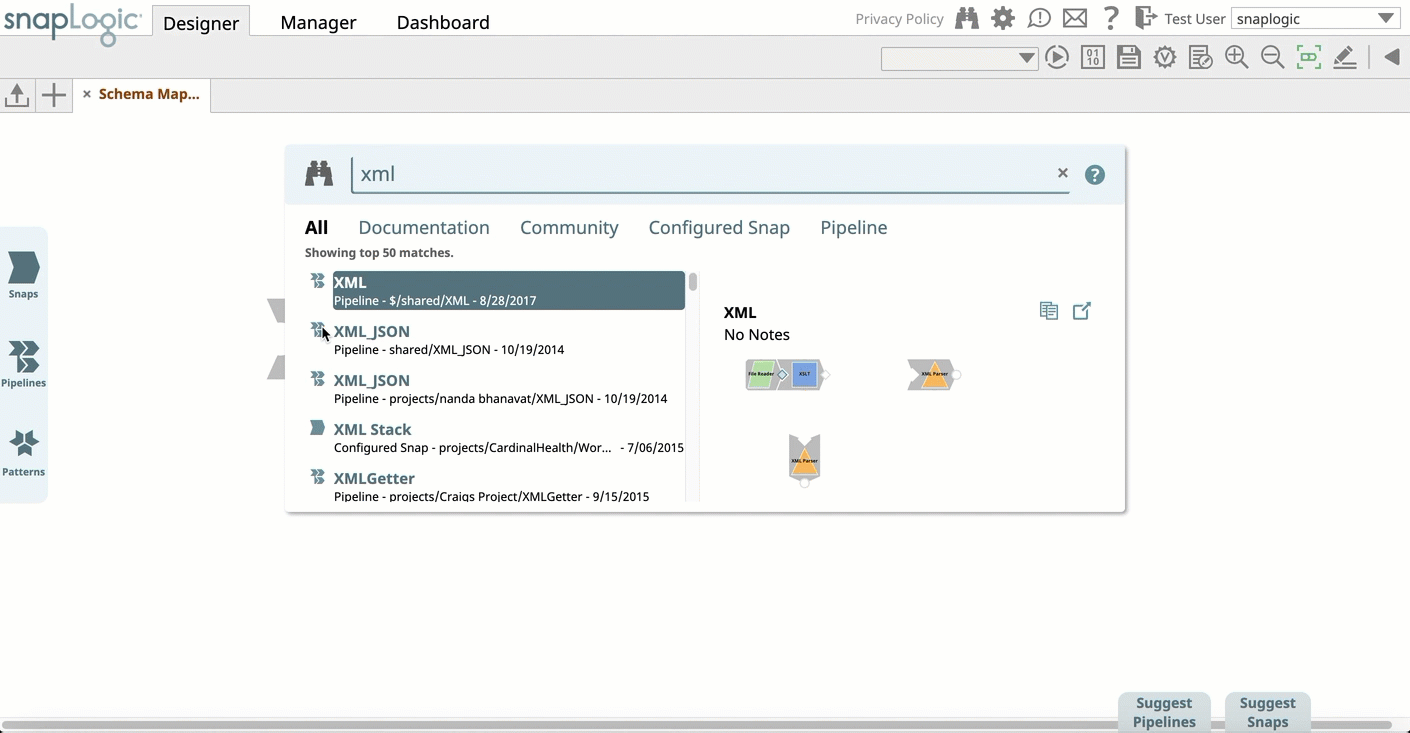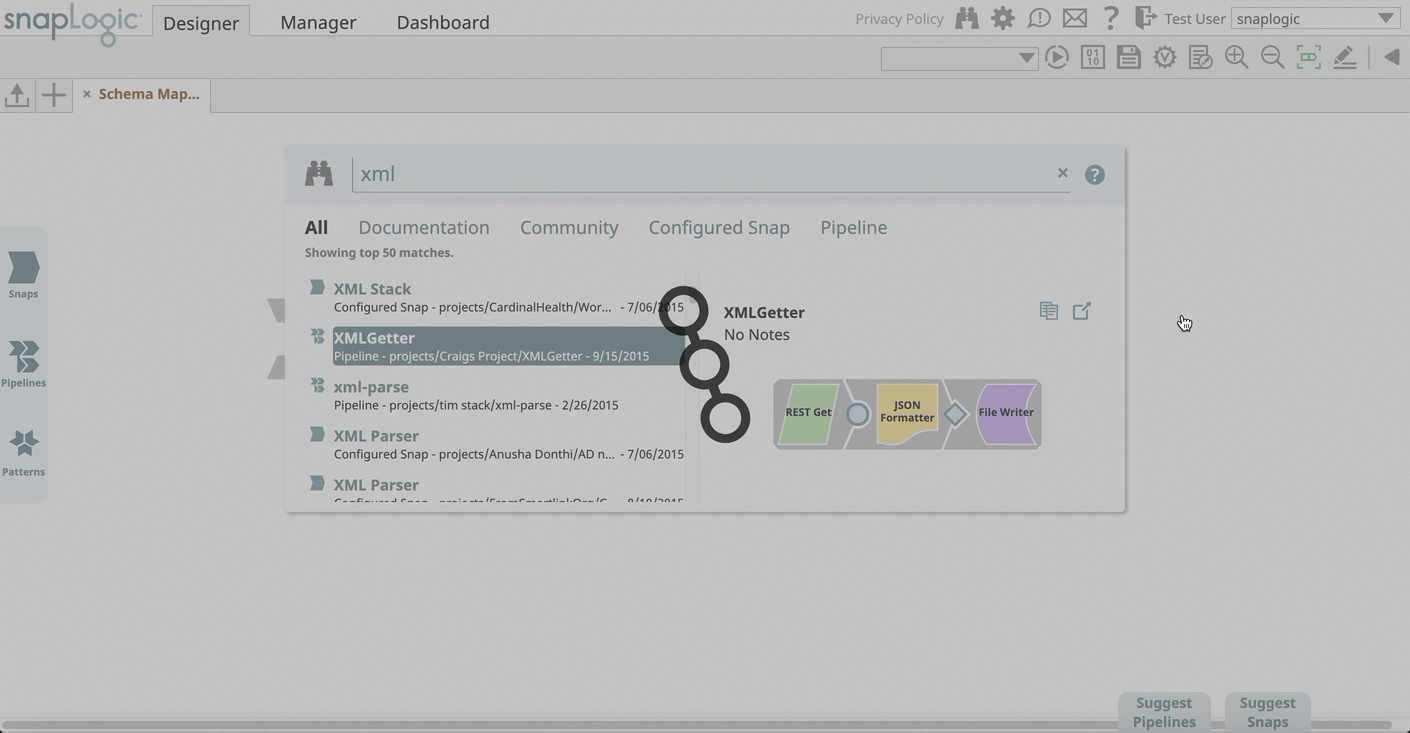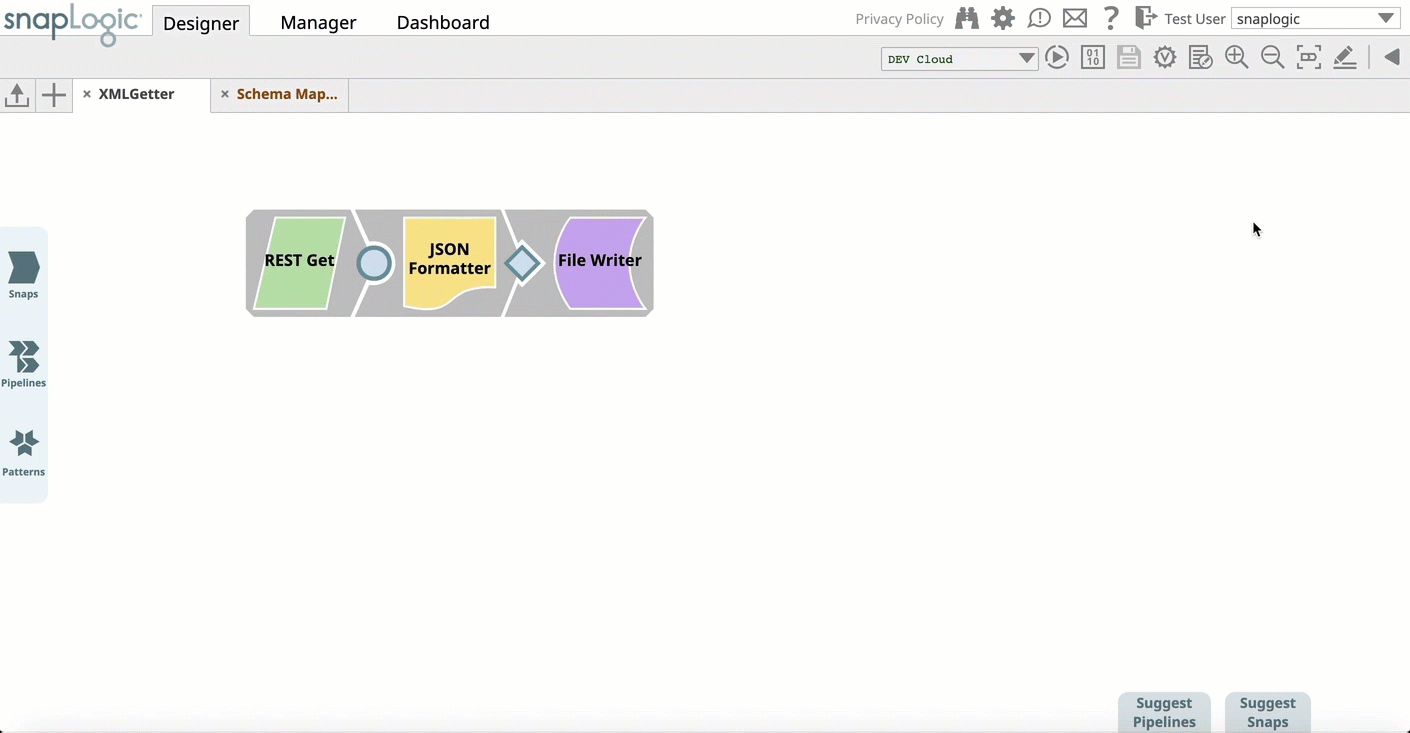
- Pipeline Search: Introduces a new search category in the Universal Search, you can now browse through search results that include high quality Pipelines in your Org. Pipelines deemed as high quality have successfully executed repeatedly. Similar to Configured Snap search, you can narrow the results by Project. You can also open the Pipeline or copy it to another Project.
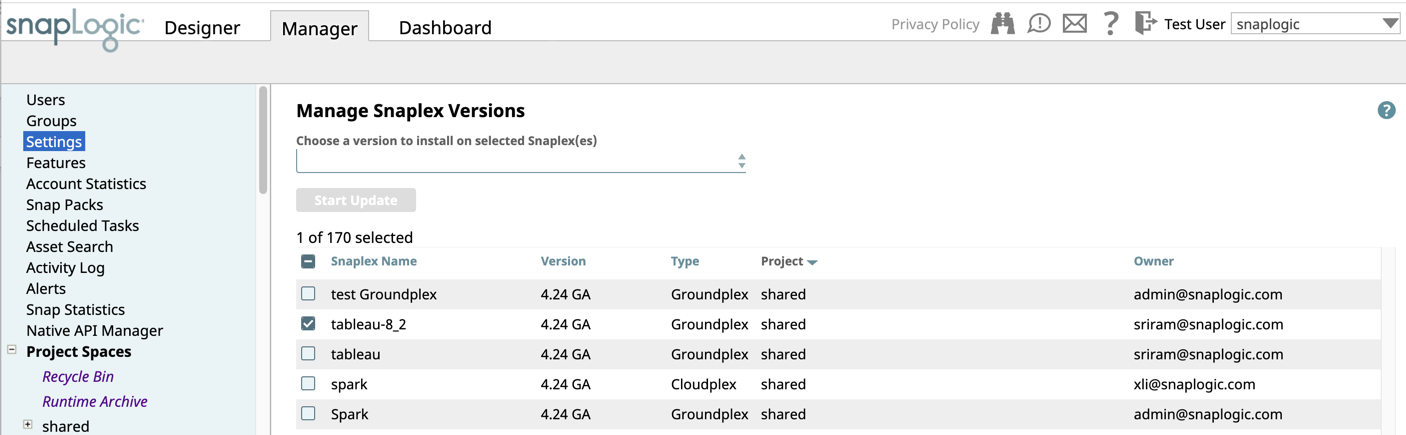
- Snaplex Version Manager: Introduces a new page in SnapLogic Manager that lists all the Snaplex instances in an Org and their versions. The selector enables you to choose the Snaplex version for each Snaplex in your Org. For example, you can select all your test Snaplex instances to update to the latest version, while leaving all others as is, and only the selected Snaplex instances are updated.
Enhancements to Existing Features
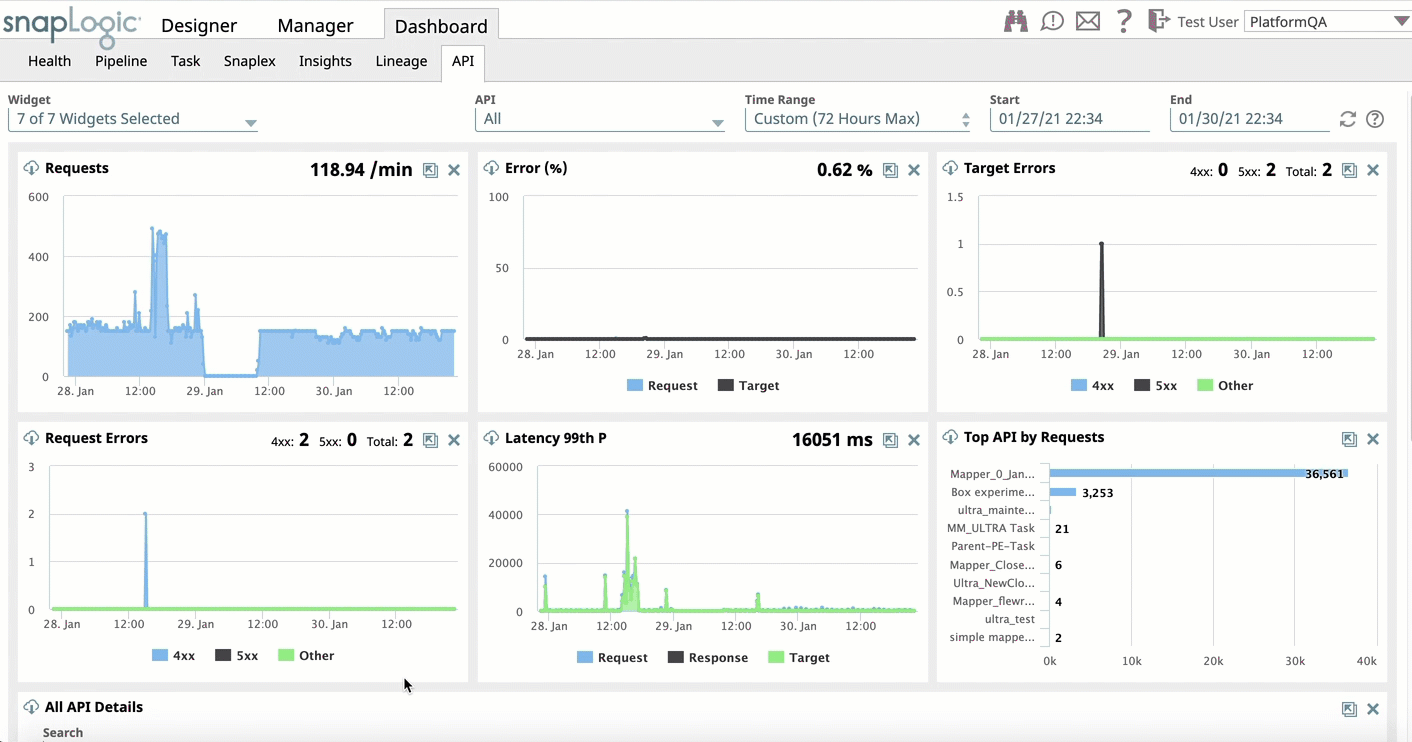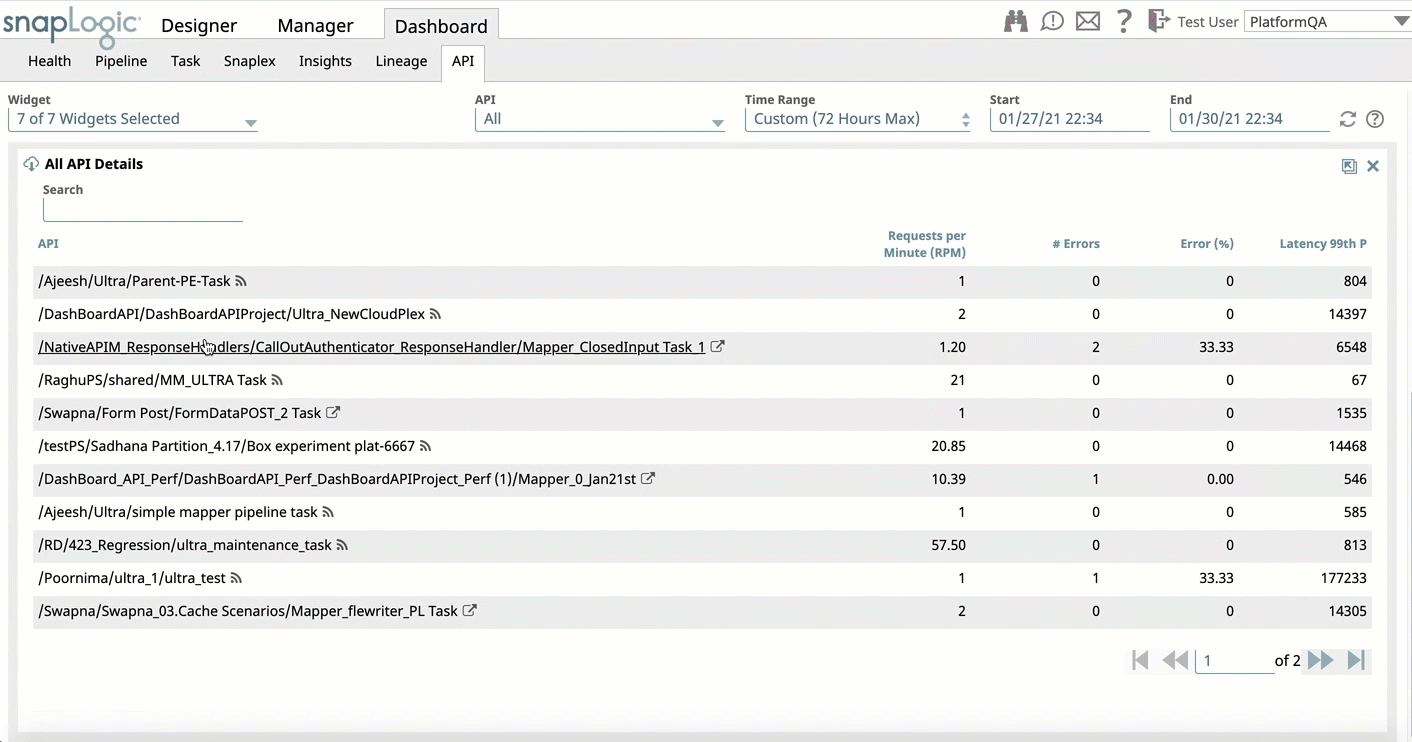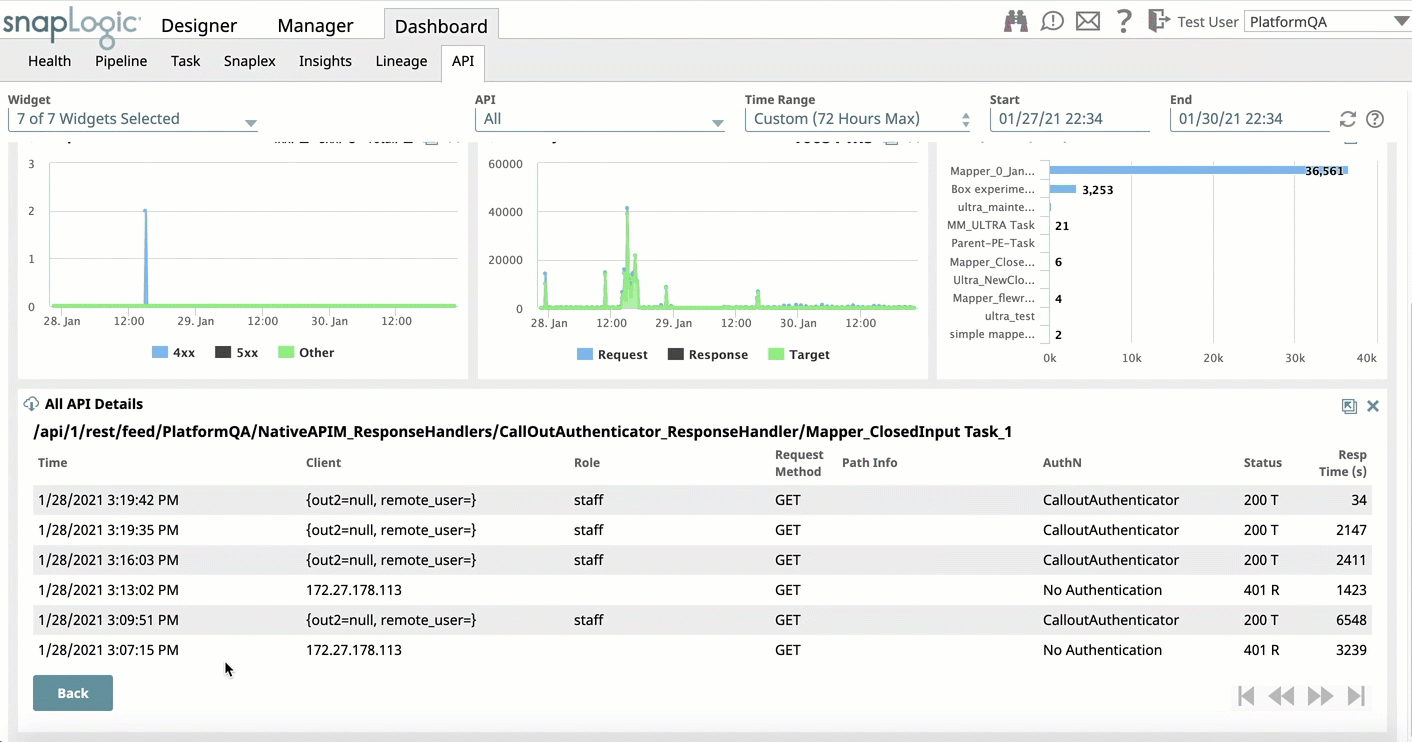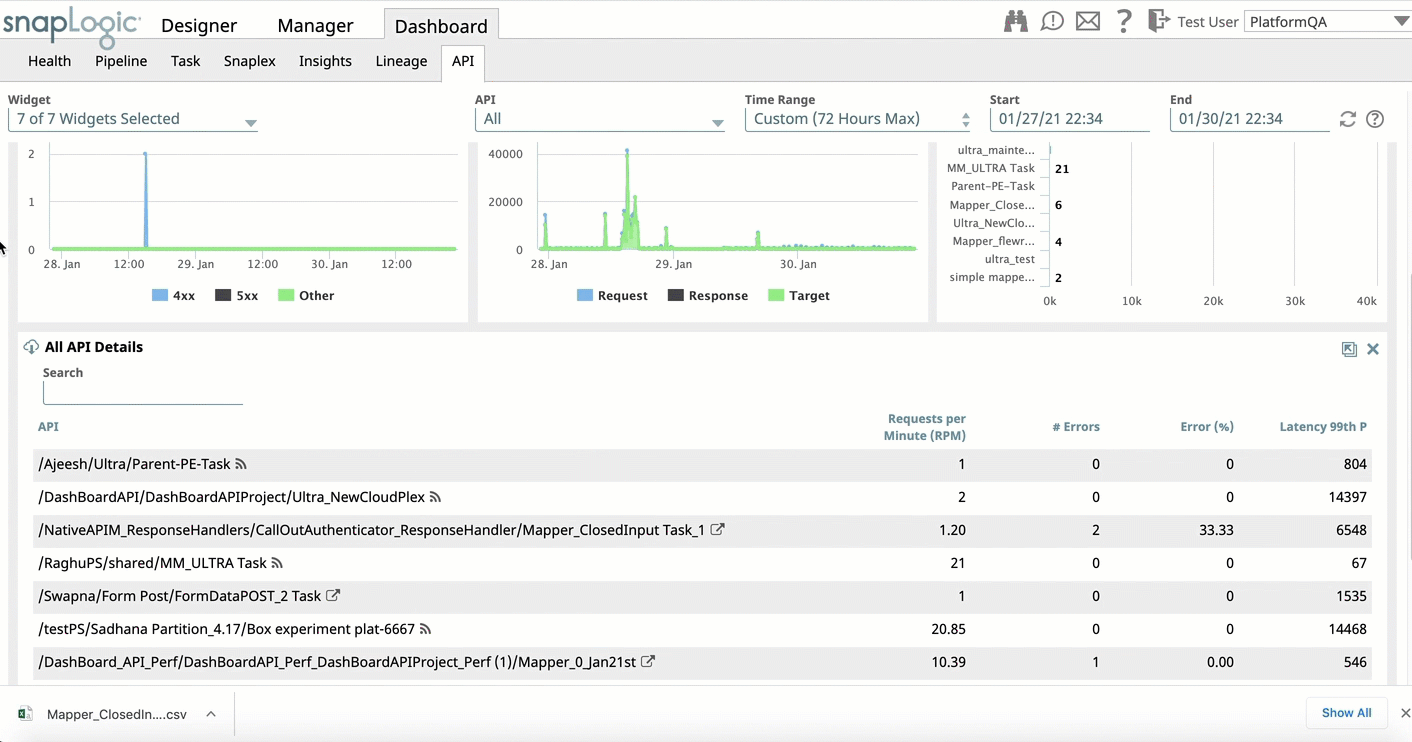
- API Dashboard: Improves the user experience with the following updates:
- Replaces non-intuitive tabs on All API Details widget with modal window for consistent experience.
- Expands the All API Details widget and improving navigation to the request log for the target API and back to the All API Details.
- Adds the ability to download all request details from the API Details widget.
Login Page: Refreshes the appearance of the SnapLogic login page. As part of this new branding, you will see a new SnapLogic login page, along with refreshed Password Recovery and SSO Login screens. However, the functionality is the same.

- Task Details: Enhances the UI display for the Task Details page, with a redesign that features better organized information, including headers, a streamlined look, and for Task runs, a search field and date selector for narrowing target Tasks.
New in 4.24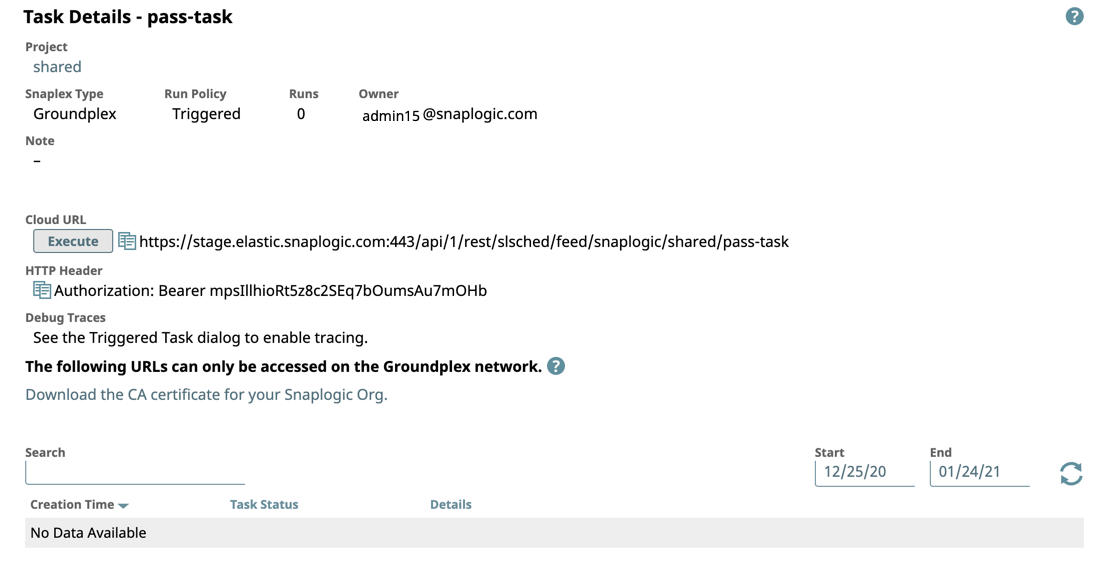
4.23 and Earlier
Additional Time Zones: Adds support for the following time zones in the 4.24 release:
New Display Time Zone Europe/London GMT/BST Europe/Paris CET/CEST Asia/Hong Kong HKT Asia/Bangkok ICT Asia/Dubai GST
Task Monitoring Dashboard Wall: Adds a new drop-down list for Invoker Type. You can now sort Tasks by type (Ultra, Scheduled, Triggered). Additionally, access permissions to the Task subtab on the Dashboard are changed in the 4.24 release:
Access permissions in 4.24 release Access permissions in 4.23 release and earlier An Org admin or any user with read access to the Project where the Task resides can view the Task monitoring Dashboard. Only Org admin or user with read and write access to the Task and underlying Pipeline can monitor Tasks.
- Extra Details: Updates the Extra Details page to display whether a Pipeline is running in Resumable Mode.
- IP Address Management: Changes Whitelist/Blacklist labels in the UI to Allowlist/Denylist.
- Child Pipelines: Changes the method for load balancing across Snaplex nodes to achieve improved node election for Pipeline executions.
Known Issues
- Scheduled Tasks that are migrated to a different Project do not reset their run counters.
- Scheduled Tasks continue executing, even when the frequency for a task is updated from 1 minute to 1 week.
- If your Org uses Snaplex Scheduling, disabling and then enabling a Scheduled Task should prevent the Task from executing while disabled, but it does not.
- Fixed in a UI patch on 3/11: Some of the new time zone labels in the Task dialog need to be updated.
When upgrading your Snaplex to the 4.24 GA version, if a node is under maintenance mode, then the node fails to upgrade.
In some cases, Ultra Pipeline Tasks duplicate messages that are being processed from the FeedMaster node, resulting in failed Retry errors. If you see this issue in your Org, see Enabling the Prevention of Duplicates Enhancement.
Behavior Change
- Project Migration API Parameter: You can now only use the
dest_pathparameter to specify a target Project. You can no longer use this parameter to specify Project Spaces as the destination path in the public API for Project migration. - Ultra Pipelines: In 4.23 release (November 2020) and earlier, you could enable and disable Ultra Tasks in Manager despite unsubscribing from the feature. Starting the 4.24 Release, you cannot access Ultra Tasks if the subscription expires.
Standard-mode Snaps
New Snaps
- HubSpot Snap Pack (dot release deployment during 4.23): Enables you to integrate with your HubSpot instance. This Snap Pack includes the following Snaps:
- HubSpot Read: Retrieves the specified entity's details from HubSpot.
- HubSpot Create: Creates an entity in HubSpot.
- HubSpot Update: Updates an entity in HubSpot.
- HubSpot Delete: Deletes the specified entity from HubSpot.
- Marketo Snap Pack: Introduces the Marketo Snap Pack to enable you to automating the process of performing operations to the Asset database and Lead database that manage the potential data for an organization in the marketing industry. This Snap Pack offers the following Snaps:
- Asset Read: Queries the Asset database to retrieve assets using commands.
- Asset Write: Interacts with the assets using commands and make modifications to the Asset database.
- Lead Read: Queries the Lead database to retrieve leads using commands.
- Lead Write: Interacts with the leads using commands and make modifications to the Lead database.
- Bulk Lead Extract: Retrieves leads in bulk from the Lead database.
- Bulk Lead Upsert: Inserts/Updates large number of leads in the Lead database.
- Microsoft Power BI Snap Pack (dot release deployment during 4.23): Enables you to access and control entities such as datasets, reports, gateways, and dashboards in the workspace. The Microsoft Power BI Snap Pack contains the following Snaps:
- Power BI Delete: Delete entities from the workspace.
- Power BI Post: Add/create entities in the workspace.
- Power BI Post Import: Import PBIX, RDL, XSLX files or files from OneDrive into the workspace.
- Power BI Push Dataset: Create datasets or modify tables or table schema in the workspace.
- Power BI Read: Read entities in the workspace.
- Power BI Read Groups: Read/retrieve entities matching a specified search criterion in the workspace.
- Power BI Update: Update entities in the workspace.
- OpenAPI Snap Pack: Introduces the OpenAPI Snap Pack to enable you to connect to your OpenAPI endpoints. This Snap Pack contains a single Snap that supports OpenAPI Specification versions 2.0 and 3.0.
- OpenAPI: Calls the OpenAPI endpoint associated with your application to perform operations, such as GET or PUT, based on the endpoint's configuration.
- OpenAPI: Calls the OpenAPI endpoint associated with your application to perform operations, such as GET or PUT, based on the endpoint's configuration.
- Teams Snap Pack: Introduces the Microsoft Teams Snap Pack to enable you to perform various operations on channels and teams. This Snap Pack offers the following Snaps:
- Teams - Channel Operations: Allows performing channel operations like add/remove/list channel members and rename channel.
Teams - Create Channel: Allows creating a public or private channel within an existing team.
- Teams - Create Team: Allows creating a new team in the Microsoft Teams environment.
- Teams - Send Channel Message: Allows sending messages and replying to messages to members in a channel.
- Teams - Team Operations: Allows to manage teams, channels, and member participation within the organization.
We strongly recommend you to use the new form UI enabled in Designer > User Settings (![]() ) for using the complete functionality in new Snap Packs from 4.23 release onwards.
) for using the complete functionality in new Snap Packs from 4.23 release onwards.
Updated Snap Packs
- Active Directory Snap Pack:
- Adds the Pass through check box in all the Snaps to include pass-through functionality. Select this check box to embed the upstream input documents under the
originalfield of the output document along with other records. Originally deployed as 423patches7454 (Latest), this Snap Pack is now part of 4.24 GA (Stable). Fixes an issue of fetching search records in the Active Directory Search Snap by adding a new field, Limit, wherein you can specify the number of search records to fetch from the Active Directory. Originally deployed as 423patches8210 (Latest), this Snap Pack is now part of 4.24 GA (Stable).
Behavior Change
- Previously the Page Size field worked similar to the Limit field, that is, it sets the limit on fetching records instead of fetching all the records.
- The Active Directory Search Snap output now displays the number of records that you specify in the Limit field under Settings. If your Pipelines use the Snap with the Page Size field, they may fail to execute if the downstream Snap expects the same count. To retrieve all the records, configure the Snap with default settings, that is, Limit: 0 and Page Size: 1000.
- Adds the Pass through check box in all the Snaps to include pass-through functionality. Select this check box to embed the upstream input documents under the
- Amazon SQS Snap Pack: Enhances the Snap Pack to support Cross-Account IAM role that allows to access the queues residing in another AWS account.
- Binary Snap Pack: Enhances the File Poller Snap by adding a field, Exit on first matches, which when set to true stops the Snap from executing after the first file paths matching the filter are written to the output view. If the field is not configured or is set to false (default value), then the Snap continues to poll the directory until the Polling timeout is reached. Originally deployed as 423patches7660 (Latest), this Snap Pack is now part of 4.24 GA (Stable).
- Kafka Snap Pack Originally deployed as 423patches7900 (Latest) , this Snap Pack is now part of 4.24 GA (Stable):
Removes the Confluent prefix from the Snaps and accounts in the Snap Pack. However, the Snap Pack name continues to be Confluent Kafka Snap Pack.
Adds Wait For Full Count check box to the Kafka Consumer Snap to determine how a positive value for the Message Count field must be interpreted.
Enabled (by default): The Snap continues polling for messages until the specified count is reached.
Disabled: If there are fewer messages currently available than the specified count, then the Snap consumes the available messages and terminates.
Adds support for writing and reading record headers:
- The Kafka Producer Snap has a new Headers table to configure the Key, Value, and Serializer for each header to be written.
- The Kafka Consumer Snap reads any headers present on the records it consumes. It provides two new fields to configure how the header values should be deserialized – Default Header Deserializer and Header Deserializers, for any headers that require a deserializer other than the default.
Adds support for writing and reading each record’s timestamp:
The Kafka Producer Snap has a new Timestamp field that can be configured to set each record’s timestamp, which is the number of milliseconds since the epoch (00:00:00 UTC on January 1, 1970). This can be set to an expression that evaluates to a long integer, or a string that can be parsed as a long integer, or a date. If you specify no expression, or the value is empty, then the timestamp is set to the current time.
The Timestamp field is only relevant if the Kafka topic is configured with
message.timestamp.type = CreateTime(which is the default). For more information, see the official Kafka documentation.
- The Kafka Consumer Snap has a check box, Include Timestamp, which by default is disabled for backward compatibility. If enabled, the output for each record includes its timestamp in the metadata.
The Kafka Producer Snap has a check box, Output Records, to determine the format of each output document when configured with an output view:
Disabled (by default): The Snap’s output includes only the basic metadata (topic, partition, offset) for each record, along with the original input document.
Enabled: Each output document contains a more complete representation of the record produced, including its key, value, headers, and timestamp.
The Kafka Consumer Snap has a field, Output Mode, with two options:
One output document per record (the default): Every record received from Kafka has a corresponding output document.
One output document per batch: Preserves the batching of records as received from Kafka. Every poll that returns a non-empty set of records results in a single output document containing the list of records as
batch,batch_sizeandbatch_index. This mode is especially useful when Auto Commit is disabled and Acknowledge Mode is Wait after each batch of records, depending on the nature of the processing between the Kafka Consumer and the Kafka Acknowledge Snaps.
Removes the Add 1 to Offsets check box from the Kafka Consumer Snap.
Removes the Account tab from the Kafka Acknowledge Snap, as it no longer needs an account.
- Data Snaps:
- Enhances the Oracle - Stored Procedure Snap to ignore the parameters evaluated as null by using the Ignore Null Parameters check box. This applies for parameters with defined default values.
- Stored Procedure Snaps: Enhances the Stored Procedure Snaps to accept parameters from input documents by column keys. If the values are empty, the parameters are populated based on the column keys for easier mapping in the upstream Mapper Snap. This enhancement impacts the following Snaps:
- Select Snaps: Enhances the Database Select Snaps to return only the selected output fields or columns in the output schema (second output view) using the Fetch Output Fields In Schema check box. If the Output Fields field is empty all the columns are visible. This enhancement impacts the following Snaps:
- Enhances the Oracle - Stored Procedure Snap to ignore the parameters evaluated as null by using the Ignore Null Parameters check box. This applies for parameters with defined default values.
- Google Spreadsheet Snap Pack: Enhances the Snap Pack by migrating from v3 to v4 API as Google announces sunsetting the v3 API on June 8, 2021. For more information, see Migrating Google Sheets Pipelines from V3 to V4. Originally deployed as 423patches7848 (Latest), this Snap Pack is now part of 4.24 GA (Stable).
- LDAP Snap Pack: Adds the Pass through check box in all the Snaps to include pass-through functionality. Select this check box to embed the upstream input documents in the
originalfield of the output document along with other records. Originally deployed as 423patches7454 (Latest), this Snap Pack is now part of 4.24 GA (Stable). - MongoDB Snap Pack: Fixes an issue in the MongoDB accounts to connect to Atlas Free Tier and Shared Cluster database using the Use cursor timeout option in the MongoDB cursor properties. If selected, this option enables the server to close a cursor automatically after a period of inactivity. For the existing accounts that does not have this field, the value for this check box returns false, which is backward compatible.
- Redshift Snap Pack: Enhances the Snap pack by adding two accounts, Redshift Cross-Account IAM Role Account and Redshift Cross-Account IAM Role SSL Account to support Cross-Account IAM Role in Redshift Snaps.
- SOAP Snap Pack: Enhances the SOAP Execute Snap by including an additional output view. When named debug (all lower-case), the Snap outputs the SOAP request headers, envelope, and the output document that is written to the default output view. Originally deployed as 423patches7411 (Latest), this Snap Pack is now part of 4.24 GA (Stable).
- Splunk Snap Pack: Enhances the Splunk Search Snap by adding a field, Response Mode, which allows receiving either JSON or XML response from the Splunk server. The default mode is XML, to enable backward compatibility. Originally deployed as 423patches7504 (Latest), this Snap Pack is now part of 4.24 GA (Stable).
Tableau Snap Pack (Deprecated): Fixes an issue when updating user information in the Tableau REST Snap by not overwriting the the site ID or user ID if the entries already exist.
Teradata Snap Pack: Fixes an issue with TPT Load Snap wherein now a null value is load as null and empty string is load as empty string.
This fix may cause existing pipelines to fail if empty string values are expected to be loaded as null.
Following are the new configurations:
VARCHAR QuotedData= OptionalVARCHAR OpenQuoteMark= \”VARCHAR NullColumns= Yes
Documentation Enhancements
Snowflake Snap Pack: Updated the Snap documents in this Snap Pack to include the following:
- Security Prerequisites required to execute the Snaps.
- Minimum permissions required to execute the Snaps.
- Commands the Snap uses internally to execute the Snaps.
Deprecated Snaps
- Starting from 4.24 GA, the following Snap Packs are deprecated. Contact support@snaplogic.com, if your existing Pipelines use Snaps from any of these Snap Packs.
- Adobe Experience Platform Snap Pack
- Concur Snap Pack
- Google DFA Snap Pack
- SAP Analytics Cloud Snap Pack
Google DFA and Adobe Experience Platform Snap Packs are now supported by the SnapLogic Professional Services team as private Snaps, in case you want to use them in your Pipelines. Contact your SnapLogic account manager for more information.
Known Issues
- Cassandra - Select Snap: This Snap supports inet Data Type that stores the IP address values. Upon validation, the Snap must display a blank space followed by the corresponding IP address value in its output view, which is the expected behavior. However, in the 4.24 Release, the Snap incorrectly displays empty string as null for inet Data Type followed by the IP address value in its output view.
- Salesforce Create Snap: The Snap passes downstream data even when the Pass through check box is not enabled.
Prior 4.23 Snap Dot Releases are Merged into 4.24 GA
| Snap Pack | Date of Update | Snap Pack Build Name | Updates |
|---|---|---|---|
| Transform | 423patches7958 | Fixes an issue in the JSON Splitter Snap by not logging a | |
| Binary | 423patches8453 | Fixes an issue in the File Writer Snap with the ADL protocol, to perform the correct action when OVERWRITE is selected from the File Action drop-down field. | |
| 423patches8397 | Fixes an authorization issue in the Snap Pack by migrating to a verified Google OAuth application. | ||
| Binary | 423patches8368 | Fixes an encryption issue with the File Operation Snap by implementing both SSE-KMS and SSE-S3 supports to the Snap. | |
| JDBC | 423patches8027 | Fixes a multiple connection issue in the JDBC Snap Pack that occurs when the Auto Detect field is enabled for each execution of the Snap by storing a copy of the database name. | |
| Binary | 423patches8368 | Fixes an issue in the Binary Snap Pack by removing the plaintext credentials in the file URL from the JCC log messages. | |
| 423patches7454 | Adds the Pass through check box in all the Snaps to include pass-through functionality. Select this check box to embed the upstream input documents under the | ||
| Active Directory | 423patches8210 | Fixes an issue of fetching search records in the Active Directory Search Snap by adding a new field, Limit, to specify the number of search records to fetch from the Active Directory. Your existing Pipelines that use Page Size for limiting records may fail to execute. Hence, modify your Pipelines using the Limit field. | |
| SQL Server | 423patches8190 | Fixes an issue with SQL Server - Execute to handle SQL statements that begin with special characters. | |
| Binary | 423patches8099 | Enhances the Snap Pack by upgrading the SMB client library. | |
| Google Directory | 423patches7817 | Fixes the authorization issue in the Snap Pack by migrating to a verified Google OAuth application. | |
| Binary |
| 423patches7958 | Fixes an issue with the File Writer Snap by avoiding overwriting of documents when appending the data to a CSV file in SFTP. |
| Confluent Kafka | 423patches7900 |
The Confluent Kafka Snap Pack documentation will be updated along with 4.24 GA, scheduled for . | |
| Transform | 423patches7898 |
| |
| Transform | 423patches7792 | Fixes an issue in the XML Formatter Snap when it fails to convert input JSON data, with the JSON property having a special character as its prefix, to the XML format by sorting the elements. | |
| Binary | 423patches7958 | Rolls back the recent patch to Binary Snap Pack (File Writer Snap - 423patches7923) that might induce SSL handshake failures/terminations in existing Pipelines. | |
| Salesforce | 423patches7888 | Fixes the the following Snaps to ensure that they maintain lineage when using in Ultra Pipelines.
This fix does not affect the bulk action Snaps in this Snap Pack that produce more than one output document for each input document. | |
| Binary |
| 423patches7923 |
As of April 20, 2021, we recommend that you not use the 423patches7923 build for the File Writer Snap, because it causes connectivity issues with the Snaplex nodes. |
| Snowflake | 423patches7905 | Fixes the performance issue in the Snowflake - Bulk Load Snap while using External Staging on Amazon S3. | |
| Binary | 423patches7795 | Fixes an issue with File Writer Snap by skipping the validation of the SAS URI having write permission, if the SAS URI uses an access policy. | |
| 423patches7800 | Fixes an issue with JDBC account through a Test Query option to establish a database connection upon using Auto detect option for the Database name. | ||
| Google Spreadsheet | 423patches7848 | Enhances the Google Spreadsheet Snap Pack by migrating from v3 to v4 API as Google announces sunsetting the v3 API on June 8, 2021. For more information, see Impact on Migrating Google Spreadsheet Pipelines from v3 to v4. | |
| Marketo | 423patches7812 | Introduces the Marketo Snap Pack to enable you to automating the process of performing operations to the Asset database and Lead database that manage the potential data for an organization in the marketing industry.
| |
| OpenAPI | 423patches7812 | Introduces the OpenAPI Snap Pack to enable you to connect to your OpenAPI endpoints. This Snap Pack supports OpenAPI Specification versions 2.0 and 3.0. | |
| SOAP | 423patches7441 | Enhances the SOAP Execute Snap by including an additional output view. When named debug (all lower-case), the Snap outputs the SOAP request headers, envelope, and the output document that is written to the default output view. | |
| Script | 423patches7671 | Fixes an issue with the PySpark Snap by removing the dependency on the json-path library, thus avoiding a conflict between the external library version and the SnapLogic json-path.jar. | |
| MySQL | 423patches7732 | Fixes an issue in the MySQL - Bulk Load Snap to support the following versions:
| |
| Microsoft Power BI | main76 | Updates the dependencies and documentation links for all the Microsoft Power BI Snaps. | |
| Transform | 423patches7753 | Fixes an issue with the JSON Splitter Snap's behavior in Ultra Pipelines that prevents processed requests to be acknowledged and removed from the FeedMaster queue, resulting in retries of requests that are already processed successfully. | |
| Binary | 423patches7660 | Enhances the File Poller Snap by adding a field, Exit on first matches, which when set to true stops the Snap from executing after the first file paths matching the filter are written to the output view. If the field is not configured or is set to false (default value), then the Snap continues to poll the directory until the Polling timeout is reached. | |
| SharePoint Online | main75 | Fixes the error view issue in SharePoint Online - Upload File Snap by dragging a new instance of SharePoint Online - Upload File Snap to the canvas, since the existing Snap that is used with a version that contains the bug continues to fail. | |
| Hadoop | 423patches7440 | Fixes the issue in HDFS Reader Snap by supporting to read and write files larger than 2GB using the ABFS(S) protocol. | |
| SAP HANA | 423patches7548 | Fixes the batch size issue in SAP HANA - Upsert Snap by using a prepare statement when sending the batch request. | |
| Box | 423patches7526 | Fixes the intermittent failure in access token refresh for the Box OAuth2 account by adopting the refreshAccessTokenIfExpired() method that checks and refreshes the access token within the last minute of its expiry. | |
| SharePoint Online | main74 | Fixes the socket timeout issue in the Snap Pack by making the following changes:
| |
| Adobe Experience Platform (Deprecated in 4.24 GA) | 423patches7447 | Fixes the Adobe Experience Platform Execute Snap issue of not passing data correctly to the downstream Snap by creating Map obj = new LinkedHashMap(); inside loop. LinkedHashMap is a hash table and linked list implementation of the Map interface, with a predictable iteration order. | |
| Splunk | 423patches7504 | Enhances the Splunk Search Snap by adding a new field, Response Mode, which allows receiving either JSON or XML response from the Splunk server. The default mode is XML, to enable backward compatibility. | |
| SAP | 422patches7378 | Enhances the SAP Execute Snap to process the structure that contains nested Table Type fields in the output document by recursively parsing them into a Map or a List set. |
Data Automation
SnapLogic's data automation solution speeds up the identification and integration of new data sources or the migration of data from legacy systems. The solution can automatically detect duplicate, erroneous, or missing data, or identify structures and formats that do not match the data model. Data automation can accelerate the loading and transformation of your data into the data warehouse, speeding up the data-to-decisions process.
ELT: New Feature
- Adds support for Azure Synapse database. You can now use the ELT Snap Pack to transform tables for Snowflake, Redshift, and Synapse databases.
Supported JDBC JAR Versions
ELT Snaps require a corresponding JDBC JAR file to connect to your target database and to perform the load and transform operations.
| Supported Database | Certified JDBC JAR File | Download Link |
|---|---|---|
| Snowflake | snowflake-jdbc-3.12.16.jar | Download this JAR file |
| Redshift | redshift-jdbc42-1.2.43.1067.jar | Download this JAR file |
| Azure Synapse | mssql-jdbc-8.4.1.jre8.jar | Download this JAR file |
Using Alternate JDBC JAR File Versions
We recommend you to use the listed JAR file versions for the current release. However, you may use a different JAR file version of your choice.
Updated Snap Pack
- ELT Snap Pack:
- ELT Database Account:
- Enhances the ELT Database Account to support the Azure Synapse database.
- Enhances the JDBC URL support for connecting to Redshift and Azure Synapse databases to work with the following URL formats.
- Redshift:
jdbc:redshift://endpoint:port/<databaseName>?<parameter1=value1>&<parameter2=value2>
OR
jdbc:redshift://endpoint:port/database?ssl=true&UID=your_username&PWD=your_password - Azure Synapse:
jdbc:sqlserver://endpoint:port;<database=databaseName>;<parameter1=value1>;<parameter2=value2>;
OR
jdbc:sqlserver://yourserver.database.windows.net:1433;database=yourdatabase;user={your_user_name};password={your_password_here};encrypt=true;trustServerCertificate=false;hostNameInCertificate=*.database.windows.net;loginTimeout=30;
- Redshift:
Alternatively, you can make use of the Username, Password, Port Number, and Database Name fields, along with the Advanced Properties > URL Properties field set to provide the parameters required for building your JDBC URL.Your existing account configurations need no changes
The ELT Database Account continues to work with the existing way of specifying the JDBC URL for Redshift - jdbc:redshift://<endpoint> with the remaining parameters provided separately within the Snap Account.
- ELT Aggregate: Enhances the Snap to:
- Support Azure Synapse's T-SQL aggregate functions and the aggregate functions in Snowflake and Redshift databases.
- General Aggregate Function
COUNT_IFin Snowflake. - General Aggregate Functions in Snowflake.
- Linear Regression Aggregate Functions in Snowflake.
- Aggregate Concatenation Functions in Snowflake, Redshift, and Synapse.
- Percentile Distribution Functions in Snowflake and Redshift.
- General Aggregate Function
- Suggest appropriate column names to select in the Snap fields for Snowflake, Redshift, and Synapse databases.
- Support Azure Synapse's T-SQL aggregate functions and the aggregate functions in Snowflake and Redshift databases.
- ELT Insert Select: Enhances the Snap to:
- Suggest appropriate column names to select in the Snap fields.
- Create Hash-distributed tables using the Target Table Hash Distribution Column (Azure Synapse Only) field when using Merge Into statement.
- ELT Join:
- Enhances the Snap to support Natural JOINS (NATURAL INNER JOIN, NATURAL LEFT OUTER JOIN, NATURAL RIGHT OUTER JOIN, and NATURAL FULL OUTER JOIN) in addition to the INNER, LEFT OUTER, RIGHT OUTER, FULL OUTER, and CROSS Joins in Azure Synapse Database. This enhancement also makes account configuration mandatory when using this Snap.
- Enhances the Snap to support Natural JOINS (NATURAL INNER JOIN, NATURAL LEFT OUTER JOIN, NATURAL RIGHT OUTER JOIN, and NATURAL FULL OUTER JOIN) in addition to the INNER, LEFT OUTER, RIGHT OUTER, FULL OUTER, and CROSS Joins in Azure Synapse Database. This enhancement also makes account configuration mandatory when using this Snap.
- ELT Load: Enhances the Snap to:
- Support the File Name Pattern option using Key Based Mechanism for Redshift database.
- Suggest appropriate column names to select in the Snap fields for Snowflake, Redshift, and Synapse databases.
- Create Hash-distributed tables using the Target Table Hash Distribution Column (Azure Synapse Only) field when the Load Action is selected as Drop and Create table.
- ELT Merge Into: Enhances the Snap to:
- Suggest appropriate column names to select in the Snap fields for Snowflake, Redshift, and Synapse databases.
- Include the Target Table Hash Distribution Column (Azure Synapse Only) field for the Snap to create hash-distributed tables.
- Include the Update Expression List - When Not Matched By Source field set to allow defining one or more Update Expressions for the WHEN clause - WHEN NOT MATCHED BY SOURCE. This applies to Azure Synapse database.
- Include the Target Table Alias field to specify the alias name required for the target table. The Snap is also equipped with the ability to auto-replace the actual table names (with the alias name), if any, used in the ON clause condition, secondary AND conditions, Update Expression list, or Insert Expression list. This applies to Snowflake, Redshift, and Synapse databases.
- ELT Sample: Enhances the Snap to:
- Support sampling type for tables by adding Number of Records and Percentage of Records fields.
- Support sample clauses for tables in Azure Synapse.
- ELT Transform: Enhances the Snap to:
- Display input schema and output schema based on the upstream and downstream Snaps connected to this Snap.
- Delete fields mentioned in the Expression field from the Snap's output when the mappings have an empty Target Path.
- Display input schema and output schema based on the upstream and downstream Snaps connected to this Snap.
- ELT Window Functions: Enhances the Snap to support the following Window Functions in addition to the existing ones:
- Value Based Analytic Functions
- LEAD and LAG Analytic Functions
- Fixes the issue of displaying generic error messages for Triggered Task failures with ELT Pipelines by displaying detailed error messages for ease in debugging.
- ELT Database Account:
We recommend you to create ELT accounts for Snaps (where required) through the respective ELT Snaps in Designer. Avoid creating ELT accounts via Manager, since ELT accounts use the functionality of the new form UI, which is currently supported only in Designer.
Updated eXtreme Snap Packs
- eXtreme Execute Snap Pack: Enhances the eXtreme Execute AWS Account to support the use of cross-account IAM roles. JAR Submit - Spark SQL 2.x and PySpark Script - Spark SQL 2.x Snaps can now be used with cross-account IAM roles. See Configuring Cross-Account IAM Role Support for eXtreme Snaps for instructions to define a Cross Account IAM role in your AWS environment.
- eXtreme Redshift Snap Pack: Enhances the /wiki/spaces/SD/pages/836534651 Snap by adding the Enable SQL query editor check box to enable you to enter the SQL query in a separate editor window.
- eXtreme Snowflake Snap Pack: Enhances the /wiki/spaces/SD/pages/722010467 Snap by adding the Enable SQL query editor check box to enable you to enter the SQL query in a separate editor window.
- Spark SQL 2.x Snap Pack: Enhances the AWS Account for Spark SQL 2.X to support the use of cross-account IAM roles. File Reader - Spark SQL 2.x and /wiki/spaces/SD/pages/410091608 Snaps can now be used with cross-account IAM roles. See Configuring Cross-Account IAM Role Support for eXtreme Snaps for instructions to define a Cross Account IAM role in your AWS environment.
Known Issues
- ELT Pipelines that run successfully may fail during validation with the error class java.lang.Boolean cannot be cast to class java.lang.Number when fetching bit values from Azure Synapse database tables as the ELT Snaps currently do not support the use of bit data type.
- Snaps in the ELT Snap Pack that contain the Schema Name field display schema name suggestions from all databases that the Snap account user can access, instead of the database selected in the Snap account or the Snap Settings.
- The ELT Limit Snap does not currently support applying an ELT Limit Offset when fetching data from an Azure Synapse database.
- Breaking Change for Pipelines consisting of PySpark Script, Parquet Formatter, or ORC Formatter Spark SQL 2.x Snaps: Due to an unexpected field name change internally, existing Pipelines (prior to 4.24 GA) will likely fail. You will need to recreate the said Pipelines for them to successfully execute.
com.atlassian.confluence.api.service.exceptions.PermissionException: Parent page view is restricted
If you're experiencing issues please see our Troubleshooting Guide.
Prior 4.23 eXtreme Dot Releases are Merged into 4.24 GA
None.
Have feedback? Email documentation@snaplogic.com | Ask a question in the SnapLogic Community
© 2017-2024 SnapLogic, Inc.